介绍
此博客文章将介绍如何使用名为Replit的在线IDE,以及如何将其用作主机选项,以托管您的SERPAPI代码来为您的SEO,数据提取脚本或其他任何内容运行CRON作业。
什么是serpapi?
Serpapi提供了一个方便的网关,可通过JSON响应从Google和其他搜索引擎访问原始数据,这意味着您在Google或其他引擎中看到的任何内容都可以在响应JSON中看到。
IT has support for 9 languages(2即将推出2,Swift和C ++)。 Playground page to play around and experiment。
但是为什么要回复?
好吧,它比其他类似工具(例如pythonanywhere)更简单,并且至少在现在,它一直在变得越来越好。
几个关于“始终在”功能上的单词
请记住,此示例至少需要一个Hacker plan,该示例目前每月的价格为7美元。此计划需要使用“始终”功能。我认为这是值得的。
设置REPLIT帐户和REPT
首先,请确保您已经注册了一个帐户,然后选择一个黑客计划:

接下来,我们需要创建一个将添加所有代码的替补:

创建了重置后,这是我们要触摸的主要内容,与您的IDE或文本编辑器中的相同:

安装软件包
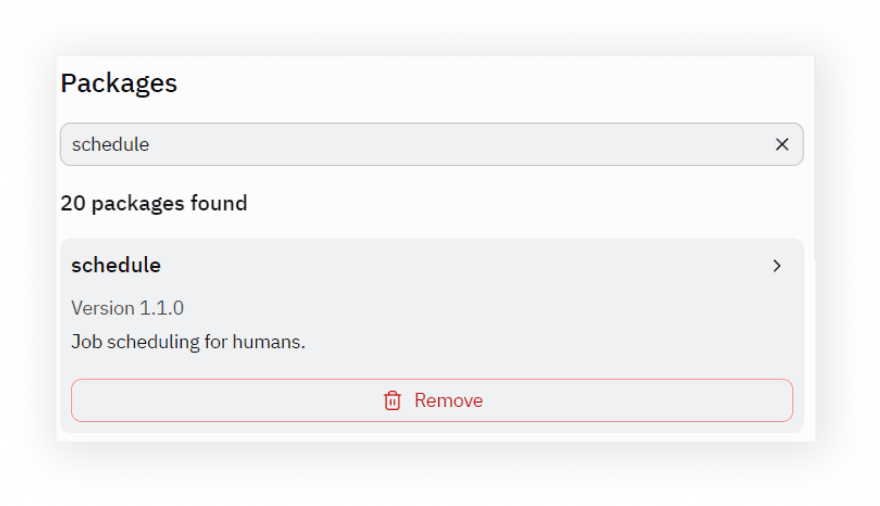
现在到代码本身。在“软件包”工具下添加koude0并安装它:

添加一个可以从事cron工作的koude1软件包:
代码
这是一个非常简单的示例代码,每5秒钟运行一次,直到n时间n ntie并提取目标网站的位置。
Have a look at how the following example runs on Replit,以防万一(您需要将os.getenv("API_KEY")更改为your SerpApi key)。
from serpapi import GoogleSearch
import os
import time
from datetime import datetime, time as datetime_time
import schedule
def job():
TARGET_KEYWORD = 'coffee'
TARGET_WEBSITE = 'healthline.com'
QUERY = 'coffee tips'
params = {
"api_key": os.getenv("API_KEY"), # your serpapi api key, https://serpapi.com/manage-api-key
"engine": "google", # serpapi pareser engine
"location": "Austin, Texas, United States", # location of the search
"q": QUERY, # search query
"gl": "us", # country of the search, https://serpapi.com/google-countries
"hl": "en", # language of the search, https://serpapi.com/google-languages
"num": 100 # 100 results
}
search = GoogleSearch(params)
results = search.get_dict()
matched_results = []
for result in results["organic_results"]:
if TARGET_KEYWORD in result["title"].lower() and TARGET_WEBSITE in result["link"]:
matched_results.append({
"position": result["position"],
"match_title": result["title"],
"match_link": result["link"]
})
print(datetime.now().strftime("%H:%M"))
print(matched_results)
if __name__ == "__main__":
scheduled_off_time = datetime_time(6, 11) # 6 hours, 11 minutes. Repl server local time
schedule.every(5).seconds.until(scheduled_off_time).do(job)
while True:
schedule.run_pending()
print("job pending ⌛")
time.sleep(4)
current_time = datetime.now().time()
if current_time > scheduled_off_time:
schedule.clear()
print("Done ✅")
break
完整执行输出
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
Done ✅
返回结果:
[
{
"position":75,
"match_title":"8 Ways to Make Your Coffee Super Healthy - Healthline",
"match_link":"https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy"
}
]
我要强调的一件事是,确保您通过运行下面的命令来确保当前时间是什么。
这是为了确保您看到服务器的本地时间是什么,因为它可能与您的本地时间不同。
from datetime import datetime
datetime.now().strftime("%H:%M:%S") # or without %S, %M
# 05:35:02
设置“始终在”功能
除了启用“始终”功能之外,如果您需要更多RAM,CPU和存储,还可以启用“ Boost Rept”:
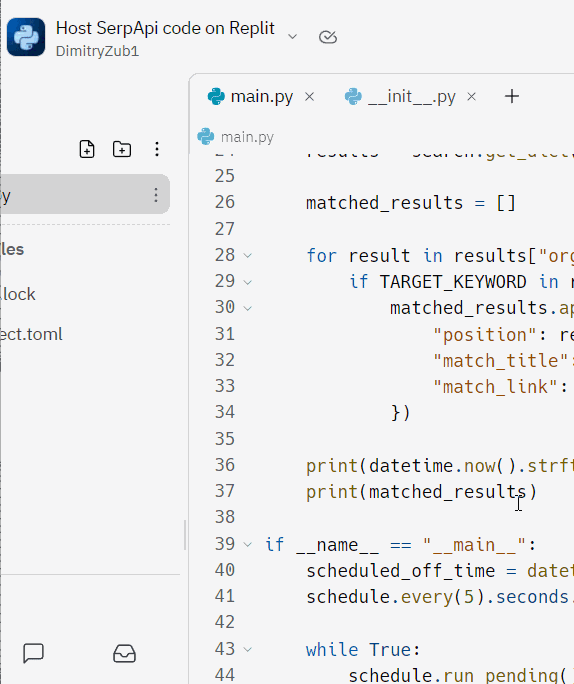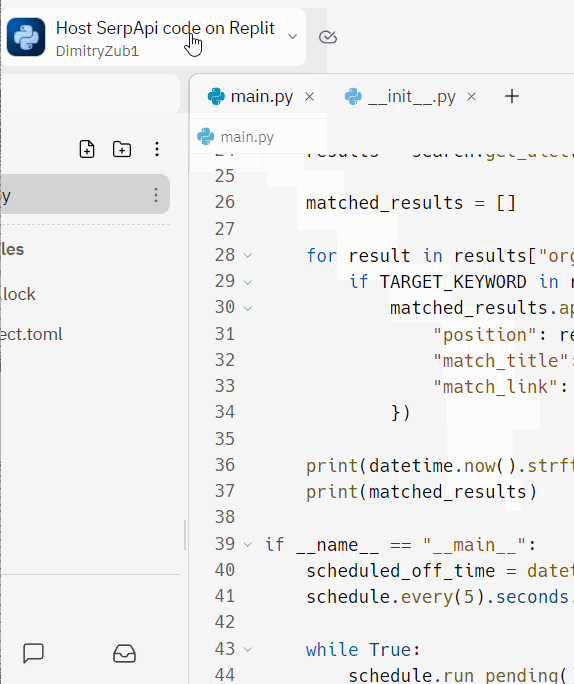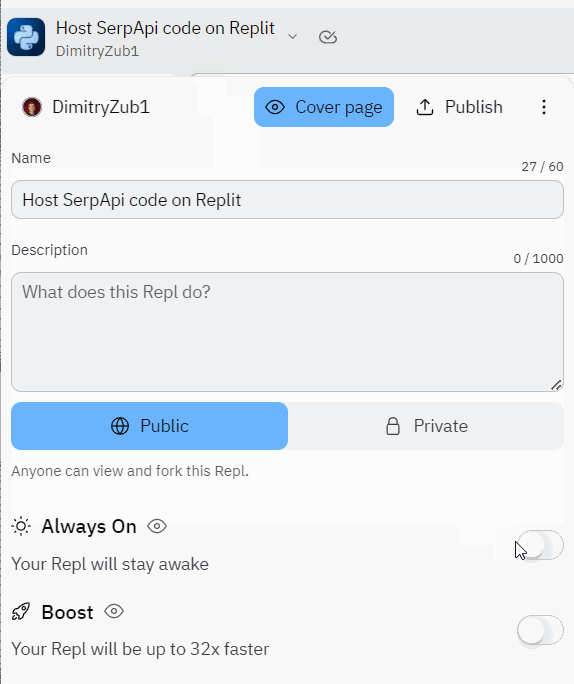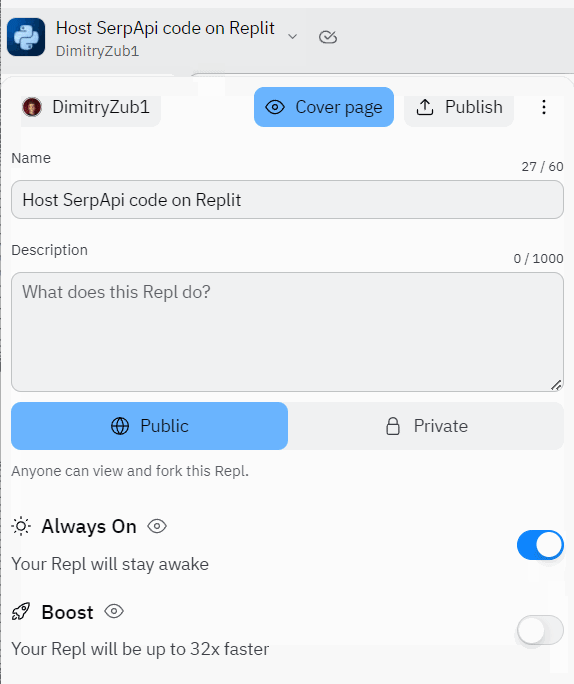
yayð现在您的脚本将始终处于活动状态并运行直到某个时间ð
使用这种方法,您可以添加诸如Google Cloud Storage之类的工具来提取数据并立即将其上传到云存储桶中,以及许多其他内容。
添加Feature Requestð«或Bugð