一种众所周知的技术,用于改善软件系统的运行时间性能(以Python或任何语言)的功能进行记忆。记忆是应用于单个函数的一种缓存。如果一个具有相同参数的函数多次称为函数,则可以通过将结果存储在映射(或磁盘上)中,并由参数键入,可以避免重复计算。在随后的电话中,如果找到了参数,则返回存储的结果。
这个机会带来了权衡。纪念活动以空间成本减少时间:先前计算的结果必须存储在内存或磁盘上。此外,回忆的函数必须是纯的:必须由其输入仅确定输出。最后,对函数参数的类型有限制。随着记忆中的记忆,结果存储在映射中的情况下,参数必须是可观的且不可变的。通过基于磁盘的回忆,结果存储在文件中,必须将参数还原为唯一的文件名。从加密哈希功能得出的消息摘要对于此目的是最佳的。
记忆的另一个挑战是缓存无效:要避免过度的缓存增长,必须放弃缓存。 Python标准库提供了使用functools.lru_cache() Decorator的内存解决方案。该装饰器以“最不最近使用”的(LRU)缓存无效策略实现了回忆:在达到最大计数之后,删除了最不切实际的缓存。
对于使用PANDAS DataFrames作为函数参数的Python程序员,还有进一步的挑战。作为可变的容器,Pandas DataFrame和Series无法使用。如果参数是Pandas DataFrame,functools.lru_cache()将失败。
>>> import functools
>>> @functools.lru_cache
... def cube(v):
... return v ** 3
...
>>> import pandas as pd
>>> df = pd.DataFrame(np.arange(1_000_000).reshape(1000, 1000))
>>> cube(df)
Traceback (most recent call last):
File "<console>", line 1, in <module>
TypeError: unhashable type: 'DataFrame'
StaticFrame是一个替代数据帧库,可为基于内存和磁盘的回忆提供有效的解决方案。
哈希功能和哈希碰撞
在用静态框架演示数据框后,很重要的是区分不同类型的哈希函数。
哈希函数将可变大小的值转换为较小的(通常)固定尺寸的值。哈希碰撞是在不同的输入哈希到相同结果时。对于某些应用,哈希碰撞是可以接受的。加密哈希功能旨在消除碰撞。
在Python中,内置的hash()函数将Hashable对象转换为整数。任意类型可以通过实现魔法__hash__()来提供支持。重要的是,hash()的结果不是抗碰撞的:
>>> hash('')
0
>>> hash(0)
0
>>> hash(False)
0
python词典使用hash()将字典键转换为低级C数组中的存储位置。预计使用__eq__()进行碰撞,如果发现,则可以通过平等比较来解决。因此,要使任意类型具有可见,它需要同时实现__hash__()和__eq__()。
加密哈希功能与hash()不同:它们旨在避免碰撞。 Python在hashlib库中实现了一系列加密哈希功能。这些功能消耗字节数据并使用hexdigest()方法返回,将消息摘要作为字符串。
>>> import hashlib
>>> hashlib.sha256(b'').hexdigest()
'e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855'
>>> hashlib.sha256(b'0').hexdigest()
'5feceb66ffc86f38d952786c6d696c79c2dbc239dd4e91b46729d73a27fb57e9'
>>> hashlib.sha256(b'False').hexdigest()
'60a33e6cf5151f2d52eddae9685cfa270426aa89d8dbc7dfb854606f1d1a40fe'
内存回忆
要记忆将数据框作为参数的函数,需要一个不可变的hashable数据框架。静态框为此目的提供了FrameHE,“他”代表“ hash,quals”,这是python hashable的两个必需的实现。虽然staticframe Frame是不可变的,但它不可行。
FrameHE.__hash__()方法返回索引和列标签的hash()。虽然这将与其他标签相同但值不同的其他FrameHE碰撞,但仅使用标签来防御更昂贵的全值与__eq__()。
FrameHE.__eq__()的实现只需将Frame.equals()委派给Frame.equals(),这种方法总是返回单个布尔值。这与Frame.__eq__()形成鲜明对比,后者在布尔Frame中返回元素的比较。
>>> f = sf.FrameHE(np.arange(1_000_000).reshape(1000, 1000))
>>> hash(f)
8397108298071051538
>>> f == f * 2
False
可以使用FrameHE作为参数,可以使用用functools.lru_cache()装饰的cube()函数。如果缺少FrameHE,则可以使用to_frame_he()方法从其他静态帧容器中有效地创建FrameHE。由于基本的Numpy阵列数据是不可变的,并且可以在容器中共享,因此这是一个轻巧的无拷贝操作。如果来自Pandas DataFrame,则可以使用FrameHE.from_pandas()。
在下面的示例中,我们创建一个大型FrameHE。 ipython %time实用程序表明,在被调用一次后,随后的呼叫相同的参数是三个数量级的速度(从ms到µs)。
>>> %time cube(f)
CPU times: user 8.24 ms, sys: 99 µs, total: 8.34 ms
>>> %time cube(f)
CPU times: user 5 µs, sys: 4 µs, total: 9 µs
虽然对内存中的记忆有帮助,但FrameHE实例也可以是集合的成员,为收集独特的容器提供了一种新颖的方法。
从数据框架创建消息摘要
虽然内存回忆提供了最佳性能,但Caches消耗了系统内存,并且不会持续超出过程的寿命。如果功能结果很大,或者缓存应持续存在,则基于磁盘的备忘录是一种替代。
在这种情况下,参数的可熔性和可渗透性是无关紧要的。取而代之的是,可以从参数得出的名称的文件中检索缓存的结果。在参数上应用加密哈希功能是理想的选择。
因此,哈希函数通常以字节数据为输入,Frame及其所有组件必须转换为字节表示。一种常见的方法是将Frame序列化为JSON(或其他一些字符串表示),然后可以将其转换为字节。由于基本的numpy阵列数据已经存储在字节中,因此将数据转换为字符串的效率低下。此外,由于JSON不支持Numpy类型的全部范围,因此JSON输入也可能不足,导致碰撞。
staticframe提供via_hashlib()来满足这一需求,提供了一种有效的方法,可以为Python hashlib模块中的加密哈希功能提供字节输入。下面使用SHA-256的示例。
>>> f.via_hashlib(include_name=False).sha256().hexdigest()
'b931bd5662bb75949404f3735acf652cf177c5236e9d20342851417325dd026c'
首先,via_hashlib()被调用,以确定输入字节中应包含哪些容器组件的选项。由于默认的name属性None无法编码字节,因此被排除在外。其次,调用了哈希函数,返回带有适当输入字节的实例。第三,调用hexdigest()方法将消息Digest返回为字符串。替代加密哈希功能,例如sha3_256,shake_256和blake2b。
要创建输入字节,静态帧将所有基础字节数据(值和标签)串联,包括包括容器元数据(例如name和__class__.__name__属性)。 via_hashlib().to_bytes()方法可以使用相同的字节表示。如有必要,可以将其与其他字节数据相结合,以基于多个组件创建哈希摘要。
>>> len(f.via_hashlib(include_name=False).to_bytes())
8016017
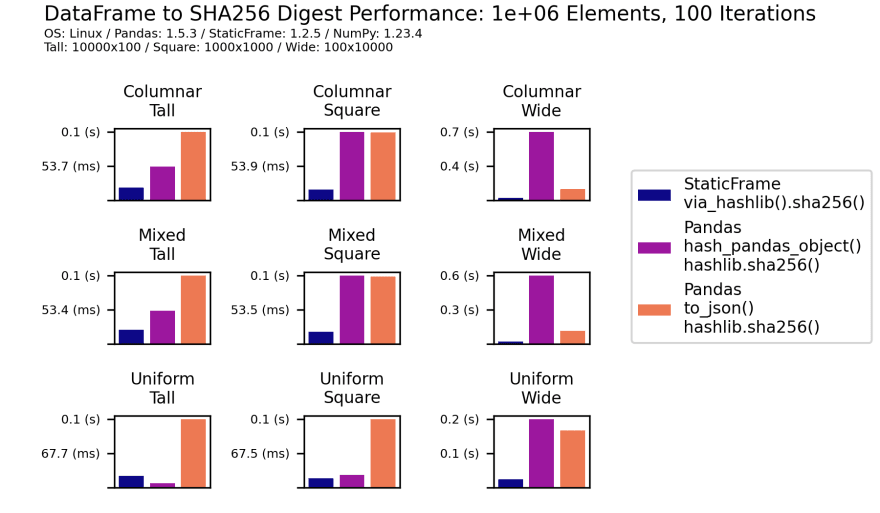
静态框架对创建消息摘要的内置支持比熊猫的两种常见方法更有效。第一种方法使用熊猫液体函数pd.hash_pandas_object()来得出每列整数哈希。此例程使用定制的摘要算法,该算法没有声称具有加密碰撞的声明。每个柱整数哈希被授予hashlib消息摘要功能。如上所述,第二种方法提供了整个数据框的JSON表示,作为hashlib消息摘要功能的输入。尽管这可能比pd.hash_pandas_object()更具碰撞性,但通常较慢。与via_hashlib()相比,以下图表显示了这两种方法的性能特征。在一系列数据框形状和类型混合物上,via_hashlib()的表现都超过一个。
基于磁盘的回忆
给出了一种将数据框架转换为哈希摘要的方法,可以实现基于磁盘的缓存例程。下面的装饰器对狭窄的函数的范围进行了此操作,该功能掌握并返回单个Frame。在此例程中,文件名是从参数的消息摘要得出的。如果文件名不存在,则调用装饰功能并编写结果。如果文件名确实存在,则将其加载并返回。在这里,使用了静态框架NPZ文件格式。正如最近的Pycon talk中所证明的那样,将Frame存储为NPZ通常比Parquet和相关格式快得多,并且提供了完整的往返序列化。
>>> def disk_cache(func):
... def wrapped(arg):
... fn = '.'.join(func.__name__, arg.via_hashlib(include_name=False).sha256().hexdigest(), 'npz')
... fp = Path('/tmp') / fn
... if not fp.exists():
... func(arg).to_npz(fp)
... return sf.Frame.from_npz(fp)
... return wrapped
要演示此装饰器,它可以应用于在十行窗口上迭代的函数,总结列,然后将结果串联到单个Frame中。
>>> @disk_cache
... def windowed_sum(v):
... return sf.Frame.from_concat(v.iter_window_items(size=10).apply_iter(lambda l, f: f.sum().rename(l)))
第一次使用后,性能降至原始运行时间的20%。虽然加载基于磁盘的缓存比检索内存中的缓存速度较慢,但避免重复计算的好处而不会消耗内存,并且缓存可以在过程中持续存在。
>>> %time windowed_sum(f)
CPU times: user 596 ms, sys: 15.6 ms, total: 612 ms
>>> %time windowed_sum(f)
CPU times: user 77.3 ms, sys: 24.4 ms, total: 102 ms
via_hashlib接口可以在其他情况下用作数字签名或数据帧的所有特征的校验和校验。
结论
如果纯函数被称为具有相同参数的多次,则记忆可以极大地提高性能。虽然输入和输出数据范围的功能需要特殊处理,但静态框架提供了方便的工具来实现内存和基于磁盘的回忆。必须格外小心,以确保缓存适当地无效并避免碰撞,因为这些错误是沉默的。但是,在这样的谨慎时,消除重复工作时可以实现巨大的表现好处。