我们经常开始编写Cadigos,并让可能影响系统性能的细节。我们认为性能问题比实际情况更大,因此,我们最终遵循更复杂的道路。
让我们考虑一些简单的东西。您正在使用Dapper,一个微ORM,以其其他CRM的速度而闻名。但是,您会正确使用Dapper并利用此性能吗?
您通常会仔细识别传递到查询的寓言吗?
让我们创建一个客户端类和一个存储客户的表:
class Cliente
{
public string Nome { get; set; }
public int Id { get; set; }
public string CPF { get; set; }
}
CREATE TABLE CLIENTE (
ID INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
NOME VARCHAR(200) NOT NULL,
CPF CHAR(11) NOT NULL
)
创建表之后,让我们将1000 cpfs(假)插入一个循环中,然后创建一个CPFãdice:
CREATE UNIQUE NONCLUSTERED INDEX IX_CLIENTE_CPF
ON Cliente (Cpf)
INCLUDE (Nome)
现在,让我们编写一个简单的代码以通过CPF获取客户,这是许多应用程序中的常见代码:
IConfigurationBuilder builder = new ConfigurationBuilder()
.AddJsonFile("appsettings.json", false, true);
IConfigurationRoot config = builder.Build();
SqlConnection sqlConnection =
new SqlConnection(
config.GetConnectionString("ecommerceConnectionString")
);
sqlConnection.Open();
var cliente = sqlConnection.QueryFirstOrDefault<Cliente>(
"select * from Cliente where CPF = @cpf",
new { cpf = "00000000090" });
sqlConnection.Close();
我们期望的是,由于我们有一个CPF列,因此数据库中执行的查询是最可行的。让我们证明存在存在,并且我们有最好的执行计划。

查询是通过对我们先前创建的CPFãdice进行索引来执行的。
现在让我们通过应用“相同”查询来运行。
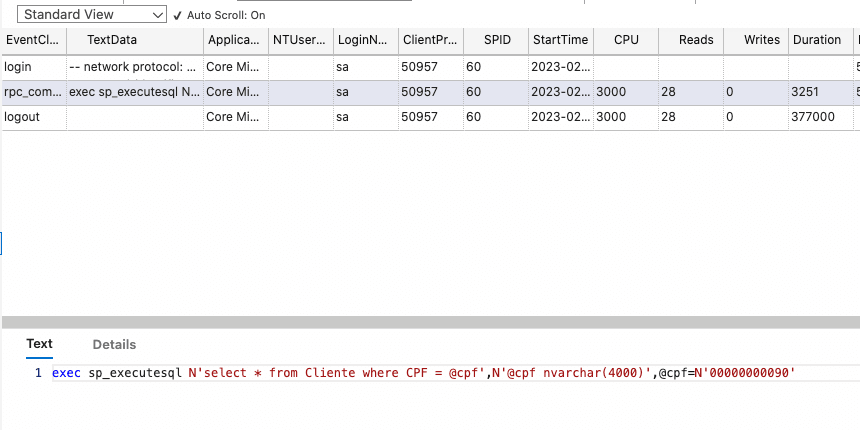
执行SQL的权利并获得执行计划。

结果并非如此。为了执行索引搜索,Dapper生成的查询执行了索引扫描。这是因为Dapper将咨询的Parano解释为标准NVarchar,这使SQL Server转换了Parano并更改执行计划,影响了咨询的绩效。 /P>
要避免此问题并改善查询的性能,有必要正确告知字符串类型Parano。在Dapper中,我们可以使用DBSTRING类指定Parano的类型。
var cliente = sqlConnection.QueryFirstOrDefault<Cliente>(
"select * from Cliente where CPF = @cpf",
new
{
cpf = new DbString
{
IsAnsi = true,
IsFixedLength = true,
Length = 11,
Value = "00000000090"
}
});
通过设置DBSTRING属性,Dapper可以使用正确的Parante类型生成约会,从而使SQL Server可以进行索引。请注意,根据数据库中的数据类型正确指定属性很重要。

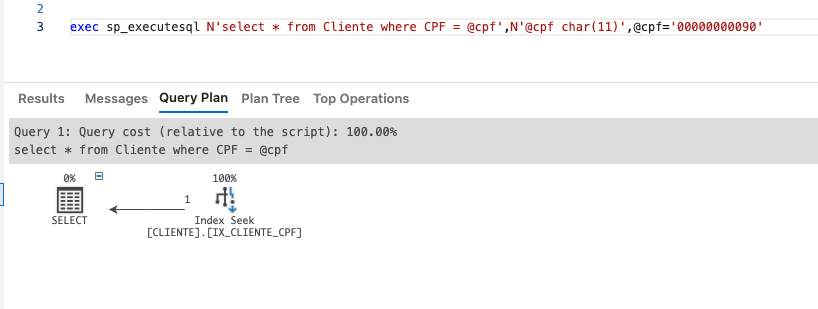
dbstring是一个dapper类,允许您指定将传递给数据库的parano的确切类型。因此,Dapper生成了一种使用正确的数据类型的仪器。这样,我们避免了不必要的对话并有助于提高咨询表现。
DBSTRING构建器允许您定义几个属性,例如Isansu,IsfixedLength,长度和值。 Isansons属性指示数据的类型是否对Unicode表示焦虑。 ISFIXEDLENGTH属性指示数据类型是固定还是变量。长度属性表示字段的大小,值属性是parano的值。
根据:

这个小细节在我们实施过程中常常没有注意到,并且会显着影响我们的应用程序的性能,直接影响常规的体验。因此,使用良好的实践和工具来帮助我们识别和纠正可能的问题很重要。
在下一个!