您很难找到一个数据科学家,他不使用熊猫来日常工作,但有时从熊猫到numpy是值得的。
pandas拥有出色的可访问性和适用于中小型项目的各种工具,但并非所有熊猫方法都利用矢量化,从而降低了代码的运行时。以apply()方法为例。对于“循环,它本质上是一个荣耀的python”,并且具有巨大的速度约束,尤其是在大型数据集的情况下。
在明亮的一面,您可以通过从numpy拉出许多熊猫方法。让我们看一下如何使用Data Notebook使用Numpy方法加快PANDAS。
使用numpy方法加快熊猫的用例
在业务环境中,运行时优化至关重要。它直接影响了程序的性能 - 尤其是更大,更复杂的程序。
只需考虑客户体验的重要性即可。如果您公司的应用程序由更快,更有效地运行的程序提供动力,则最终用户必然会更加满意。因此,提高了客户忠诚度和终身价值。另一方面,一个缓慢的应用程序冒着将客户发送给竞争对手的风险。
也可以考虑节省成本和可扩展性。优化程序的运行时间意味着它将需要更少的资源来执行,从而有助于降低成本。随着应用的规模和复杂性的增长,运行时优化对确保性能不会受到影响至关重要。
熊猫的问题是,尽管它支持矢量化,但其某些方法不支持。对于apply()和groupby()方法是正确的。您最终使用本机python“用于执行循环,这会减慢熊猫的速度。
但是Numpy可以通过多种方式帮助提高熊猫的性能。例如,如果您正在执行数值操作,则Numpy提供了一套数值功能,包括元素操作和线性代数。通过使用这些功能而不是等效的熊猫方法,您可以获得性能提升。
plus,由于Numpy提供了针对数值计算进行优化的高性能数组数据结构,因此与PANDAS DataFrames相比,您通常可以实现更快的计算。还有一个事实是,numpy阵列存储在连续的内存块中,使它们比数据框架更高的内存效率,该数据范围将数据存储在更复杂的结构和形式中。
使用numpy方法在数据笔记本中加快熊猫的速度
pandas和numpy在交互式Python环境和Python脚本中都得到了支持。因此,可以在其中任何一个中实现运行时优化。
对于本教程,我们将探索如何从已安装Python的笔记本中从Pandas到Numpy方法。
ð请记住,如果您使用DeepNote笔记本电脑,则可以跳过下面的设置过程。 DeepNote配备了已安装的最受欢迎的data analytics and machine learning Python libraries,因此您可以无缝地将它们导入您的项目。
安装大熊猫和numpy
要在jupyter笔记本中安装pandas和numpy,请运行以下命令:

导入大熊猫和numpy
接下来,要使用他们的方法,我们必须导入它们。熊猫的常用别名是pd,对于numpy,它的np。

熊猫与numpy运行时比较
首先,让我们创建一个用于实验的虚拟数据集:

接下来,让我们创建一个带有两个列和10列的Numpy数组。在此数组中,我们使用pd.DataFrame方法创建PANDAS DataFrame。
前五行如下所示:

Pandas Apply()vs.Numpy WHEND()条件列()
我们主要使用apply()方法在熊猫中创建条件列。实现如下:

如果条目小于45和“ B类”,我们将列分为“ A类”。

如上所述,apply()方法基本上是“循环”的荣耀。结果,它错过了矢量化的全部。
使用numpy's koude8方法,我们可以创建有条件的列,同时还具有矢量化。

使用此方法,条件将作为第一个参数传递。如果条件评估为true(第二个参数)和false(第三个参数),则结果是结果。如上所述,np.where()方法的速度约为五倍。
Pandas Apply()与有条件列的Numpy Select()
np.where()方法允许我们在两个结果之间进行选择(即,它适用于二进制条件)。如果有多种条件,则应使用koude11。
考虑我们具有以下功能:

使用apply()方法,我们得到以下运行时:

但是,如果我们使用np.select(),我们会得到:
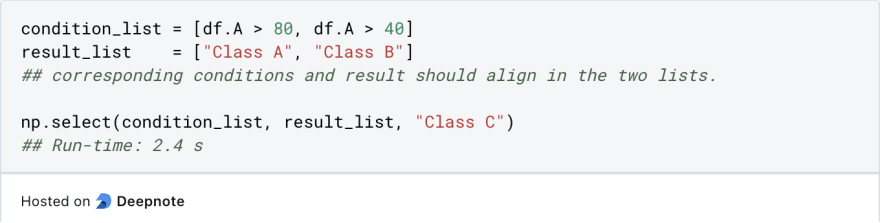
条件和相应的结果作为前两个参数传递。最后一个参数是默认结果。
您可以看到np.select()方法的速度比apply()方法快五倍。这是因为它正在使用矢量化,而apply()方法则通过列循环以基于条件创建新列。
pandas sort_values()与numpy sort()
排序是按特定顺序排列数据的常见操作。在熊猫中,我们使用df.sort_values()方法对数据框架进行分类。
使用较早的数据框,我们将获得以下运行时:

,但是Numpy也提供了一种排序方法。更具体地说,这是np.sort()方法:

使用numpy,我们首先将要排序的列转换为numpy数组。接下来,我们对获得的数组进行排序。最后,我们使用排序的数组创建一个新的数据框,然后重新排列另一列的列条目。
Numpy方法比Pandas快33%。
使用大熊猫和numpy进行运行时优化的最佳实践
优化很重要,但要谨慎也很重要。
首先介绍您的代码总是一个好习惯,因此您知道瓶颈。如果您在分析之前优化代码,则最终可能会优化错误的部分,使其更慢。
大熊猫中最大的瓶颈通常来自通过数据框架循环。因此,寻找可以用矢量化替换的部分。
此外,从外部图书馆获得支持也可以提供许多好处。它们通常针对性能进行优化,并且比自定义实现更快。
最后,确保您不会损害代码的可读性以进行优化。优化您的代码有时会使其不可读,这使其他人更难理解和维护它。
通常,如果您有鉴定代码很慢,并且优化将导致大幅提高性能。
,您才应进行优化。将大熊猫和numpy与deepnote结合在一起
Get started for free - 探索,协作和共享您的数据。