带有节点JS的Kafka入门

这是该系列的第1部分,这部分让我们了解kafka
为什么要卡夫卡?
KAFKA解决了传统消息系统中出现的几个问题: -
可伸缩性:设计为 水平缩放 ,这意味着您可以向群集添加更多的经纪人以增加吞吐量。这与其他通常仅限于单个服务器的其他消息系统相反。
可靠性:设计为 容忍 。采用诸如消息确认和复制品之类的技术,确保即使在存在故障的情况下也会传递消息。
性能:设计为 fast 。它使用日志结构的存储系统和自定义TCP协议来实现高吞吐量。这与通常使用基于队列的系统的其他消息系统相反。从视频中了解更多信息:-https://youtu.be/UNUz1-msbOM
复杂性:设计为 简单 。它使用带有Publish-Subscribe消息传递范式的简单消费者模型,并将消息存储在磁盘上。它提供了一个简单明了的API。
Kafka主要用于什么?
实时数据流:k afka ****是分布式的流媒体平台,可以处理实时数据提要,可用于构建实时数据管道和流应用程序。
日志聚合:可以使用KAFKA从多个来源汇总日志/事件,从而更容易分析和处理大量日志数据。
**微服务通信:**可以在微服务体系结构中使用Kafka。它可用于解除服务并实现它们之间的异步通信。它也可以用于构建事件驱动的系统。
Web Analytics : - KAFKA可用于构建用于收集,汇总和分析Web活动数据和指标的数据管道。这是LinkedIn的原始用例,导致其创建。
好吧,现在我们知道为什么和哪种kafka用于
让我们熟悉卡夫卡的基本术语: -
集群:Kafka正在运行的集体机器集团。 Kafka使用基于法定人数的复制来确保容错。这意味着每个分区都有一个领导者和零或更多关注者。领导者处理所有读写请求的所有读取请求。追随者复制领导者。如果领导者失败,那么其中一名追随者将自动成为新的领导者。如果老领导者返回在线,它将以追随者的身份加入追随者。这样,我们确保在失败时不会丢失任何消息。
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Replication
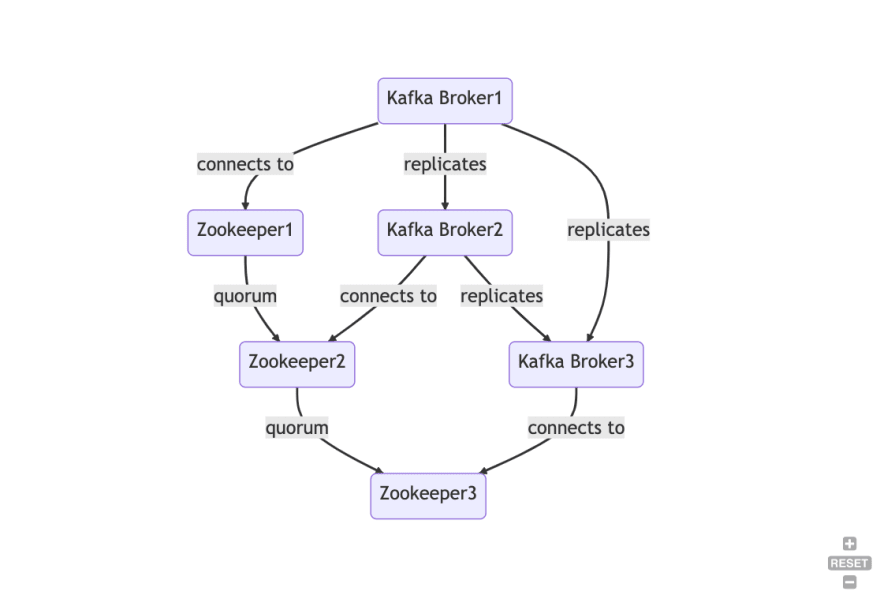
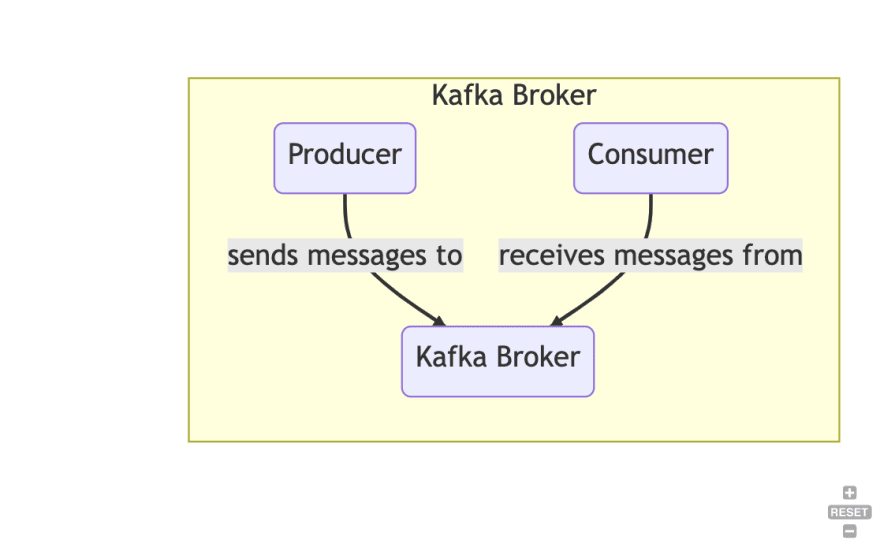
经纪人:一个Kafka实例称为经纪人。 Kafka集群由多个经纪人组成。每个经纪人都通过一个名为Broker ID的唯一ID标识。
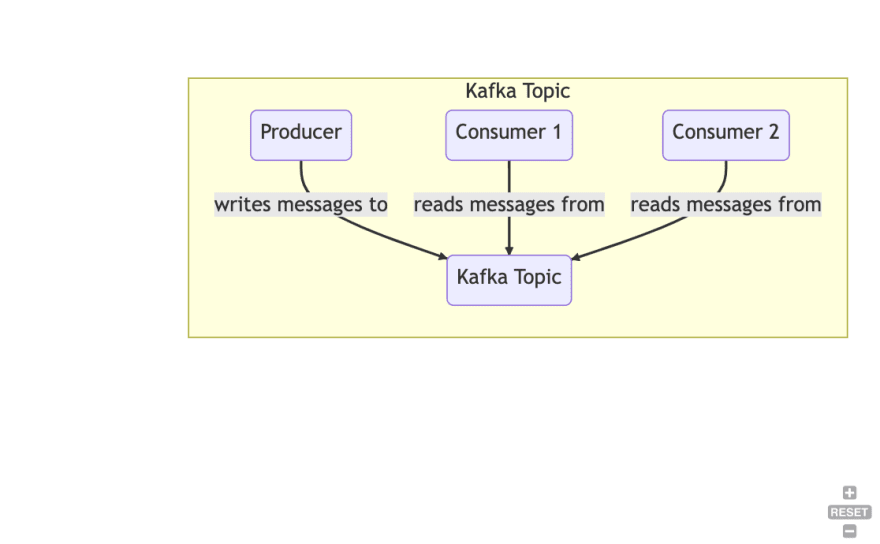
主题:主题用于组织数据。您始终读和写入特定主题
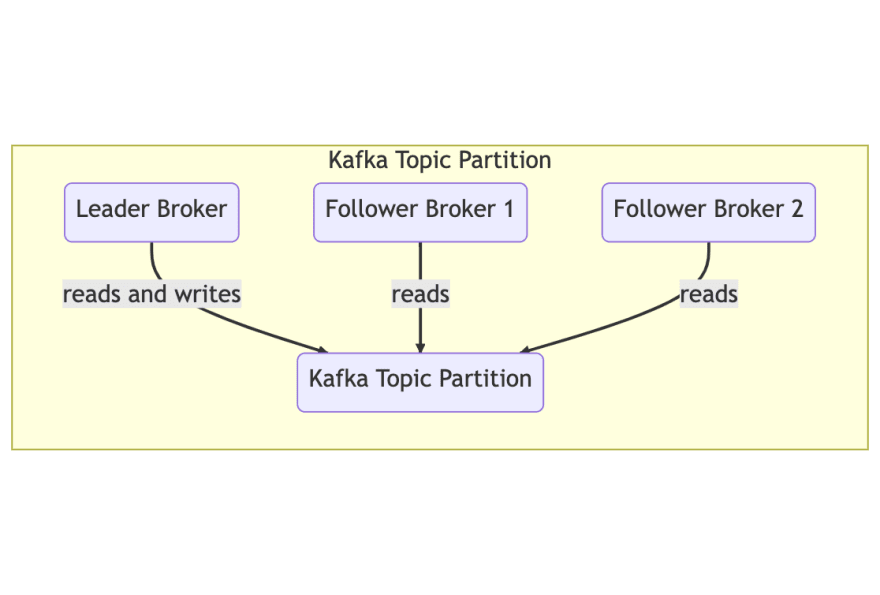
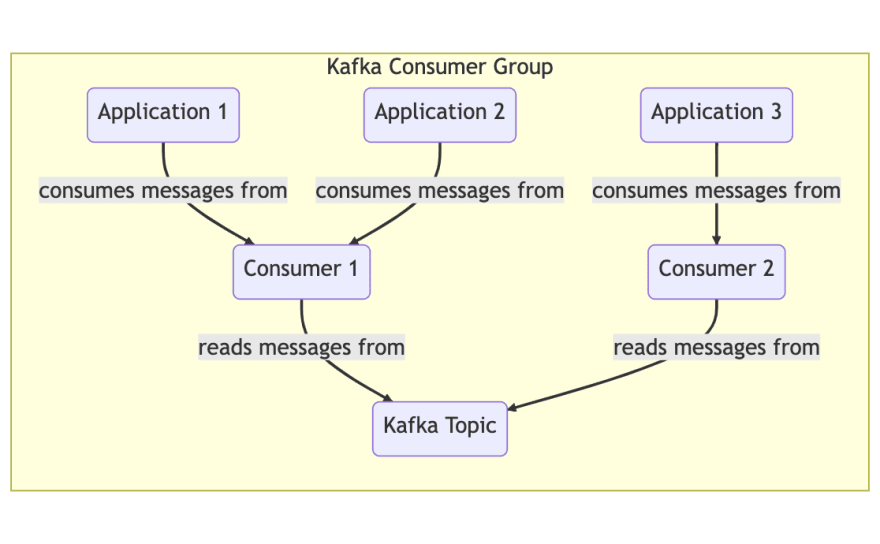
分区:主题中的数据分布在许多分区中。可以将每个分区视为日志文件,按时间订购。为了确保您以正确的顺序阅读消息,消费者组的一个成员一次可以从特定的分区中阅读。
生产者:将数据写入一个或多个Kafka主题
的客户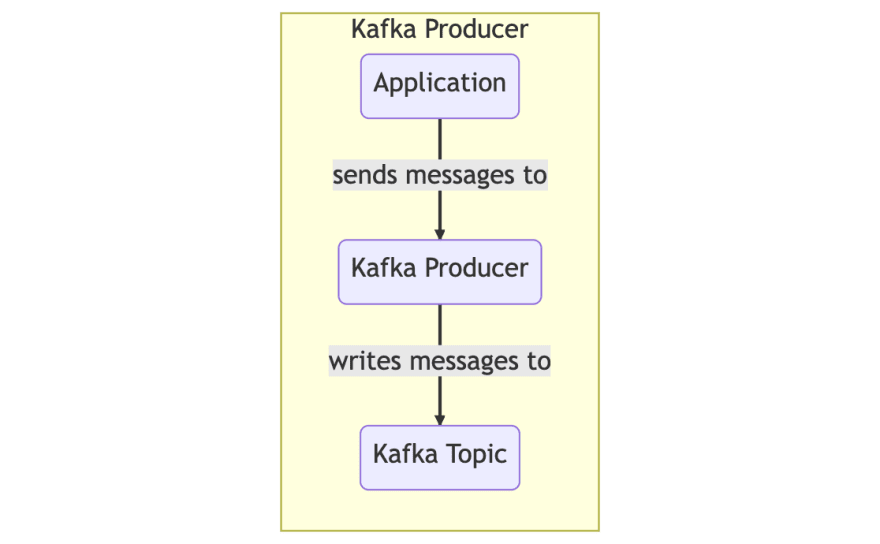
消费者:读取一个或多个Kafka主题数据的客户

replica :分区通常复制到一个或多个经纪人以避免数据丢失。
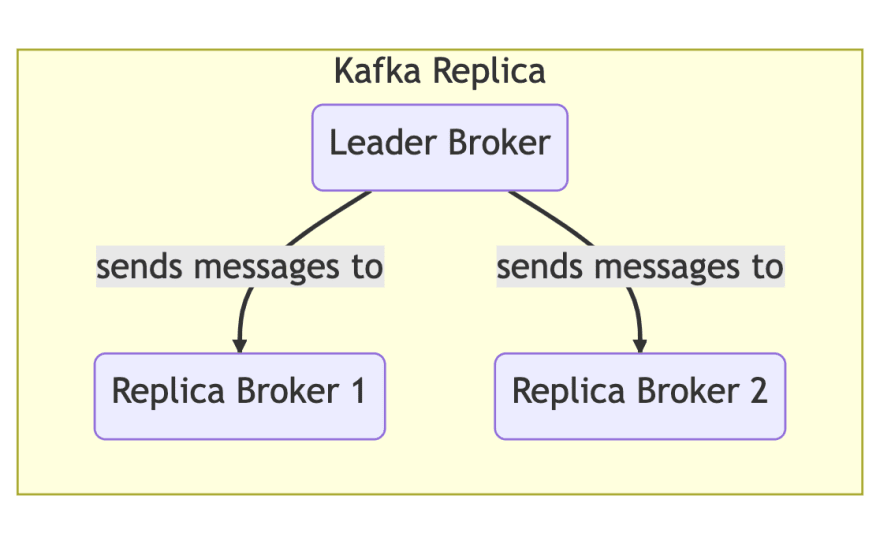
Leader: Although a partition may be replicated to one or more brokers, a single broker is elected the leader for that partition, and is the only one who is allowed to write or read to/from该分区

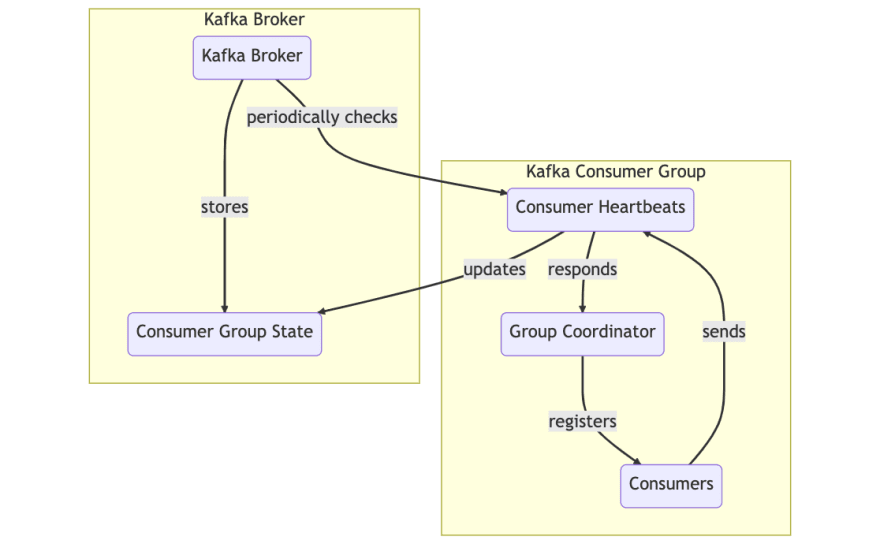
消费者群体:由groupID确定的集体消费者实例集。在水平缩放的应用程序中,每个实例都是消费者,他们一起充当消费者组。
组协调员:消费者组中的一个实例,负责将分区分配给组中的消费者
中的消费者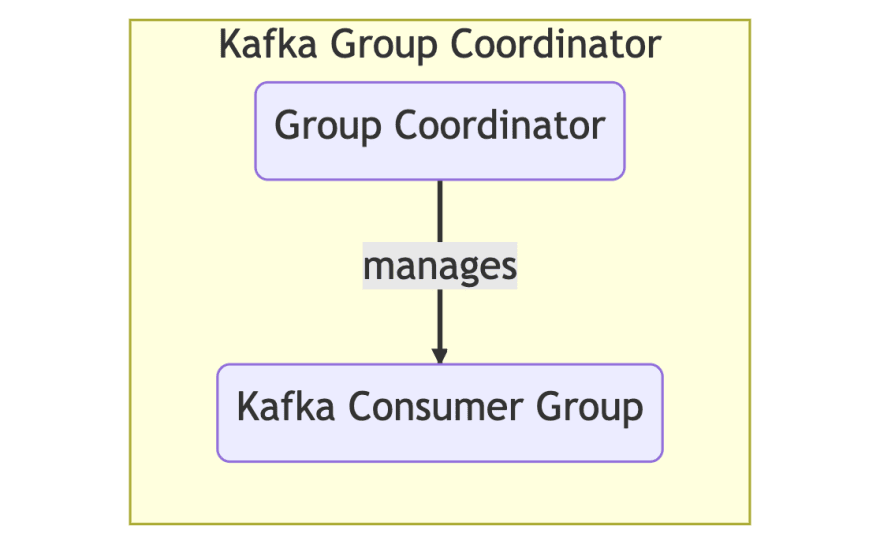
偏移:分区日志中的某个点。当消费者消费一条消息时,它会承担这种抵消,这意味着它告诉经纪人,消费者群体已经消耗了 。如果重新启动了消费者组,它将从 最高的 偏移中重新启动。
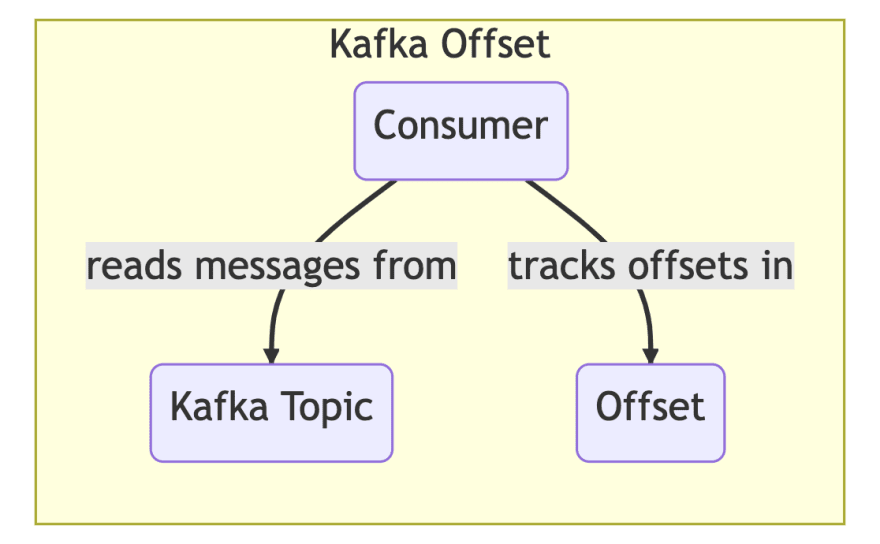
重新平衡:当消费者加入或离开消费者群体(例如在启动或关闭期间)时,该组必须“重新平衡”,这意味着组协调必须是选择和分区需要分配给消费者组的成员。

心跳:集群知道哪些消费者还活着的机制。时不时地(HeartbeatInterval),每个消费者都必须向群集领导者发送心跳请求。如果一个人在一定时期(sessiontimeout)中没有这样做,则将其视为死亡,并将从消费者组中删除,从而触发重新平衡。
参考:https://kafka.js.org/docs/introduction#glossary
总体消息流:
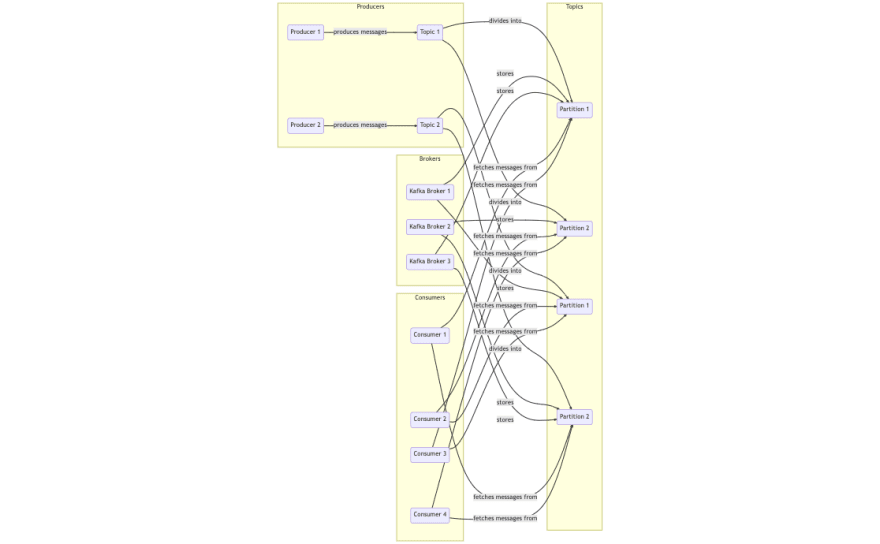
所以这是该系列的第1部分,在该系列的第2部分(即将推出)中,让我们用代码弄脏我们的手。
参考: -
https://kafka.js.org/docs/introduction
https://developer.confluent.io/learn-kafka/architecture/get-started/