关于SurreAldB的一句话
当应用程序在嵌入式设备上运行时,使用“离线”模型时,您需要先使用嵌入式(本地)数据库。当用户可以访问Internet时,您可以与远程数据库同步。一个人可以使用单个文件数据库SQLite,但可能很难与后端同步。这是SurreAldB发挥作用。这是一个轻巧的云本地数据库,声称可以轻松同步到后端。
SurroeAldB本质上是一个符合密钥/值的数据库。它可以在内存或本地持久性或远程连接中运行。 REDIS是这种内存数据库,主要用于缓存,用于PubSub和Streams(类似队列)。 SurseAldB是不同的。您可以从后端或浏览器中运行它。它提供了非常接近SQL的DSL,并允许您编写JavaScript功能。
默认情况下,它是示意性的;您可以插入任何密钥/值。当您想要更多的控件时,您可以将表变成架构表。
如果您本地运行服务器,则需要启动服务器。它也可以运行“无服务器”,这意味着您可以在云中达到服务。默认情况下,它指向https://cloud.surrealdb.com。该服务器在“/sql”上提供REST API和唯一的端点。
您需要做的就是将POST请求发送到主体中的查询。
websockets未记录为at the moment,也没有如何保护数据。
也值得注意的是,有一些功能可以处理Geojson数据。这是一个重要的主题,因为处理地理位置的许多应用程序都是嵌入式应用程序。但是,空间索引似乎没有实现(尚未实现?)(CF PostGis using GIST)。
A word on SurrealDB
Start a local SurrealDB server
Interact with the server
Schemaless tables
- First CREATE
- Transaction
- Timestamps
- Record links
- Query nested records without "join"
- Type functions
- Parameters and subqueries
Events
Register User
Elixir package SurrealEx setup
启动本地surreaLDB服务器
您可以运行Docker映像。我们通过超级用户凭据,并使用以下方式运行一个内存数据库
docker run --rm -p 8000:8000 surrealdb/surrealdb:latest start \
--log debug --user root --pass root memory
另外,您安装了SursteLDB并运行:
surreal start --log debug --user root --pass root memory
您应该得到以下提示:
.d8888b. 888 8888888b. 888888b.
d88P Y88b 888 888 'Y88b 888 '88b
Y88b. 888 888 888 888 .88P
'Y888b. 888 888 888d888 888d888 .d88b. 8888b. 888 888 888 8888888K.
'Y88b. 888 888 888P' 888P' d8P Y8b '88b 888 888 888 888 'Y88b
'888 888 888 888 888 88888888 .d888888 888 888 888 888 888
Y88b d88P Y88b 888 888 888 Y8b. 888 888 888 888 .d88P 888 d88P
'Y8888P' 'Y88888 888 888 'Y8888 'Y888888 888 8888888P' 8888888P'
[2023-02-18 20:12:12] INFO surrealdb::iam Root authentication is enabled
[2023-02-18 20:12:12] INFO surrealdb::iam Root username is 'root'
[2023-02-18 20:12:12] INFO surrealdb::dbs Database strict mode is disabled
[2023-02-18 20:12:12] INFO surrealdb::kvs Starting kvs store in memory
[2023-02-18 20:12:12] INFO surrealdb::kvs Started kvs store in memory
[2023-02-18 20:12:12] INFO surrealdb::net Starting web server on 0.0.0.0:8000
[2023-02-18 20:12:12] INFO surrealdb::net Started web server on 0.0.0.0:8000
与服务器互动
卷曲
您可以通过有效载荷,两个标头(命名空间的ns,数据库的db)和基本身份验证发送到端点:
data = "create tab:john name='john'"
curl -k -L -s --compressed POST \
--header "Accept: application/json" \
--header "NS: test" \
--header "DB: test" \
--user "root:root" \
--data "${DATA}" \
http://localhost:8000/sql
SurreAldB Cli
如果您安装了SursteLDB,则可以使用CLI在其中设置 namepace 和 database name 的基本身份验证。然后,您可以直接键入查询:
$ surreal sql --conn http://localhost:8000 \
--user root --pass root --ns testns --db testdb
> INFO FOR tb;
[{"time": "1.47255ms", "status": "OK", ...]
> CREATE ...
http客户端
您可以使用任何HTTP客户端来发布查询,并使用正确的标题和基本身份验证。
例如,在http client HTTPoison中的长生不老药中:
url = "http://localhost:8000/sql"
headers = [
{"accept", "application/json"},
{"Content-Type", "application/json"},
{"NS", "testns"},
{"DB", "testdb"}
]
auth = [hackney: [basic_auth: {"root", "root"}]]
query = "create table:test set name='hello world';"
HTTPoison.post!(url, query, headers, auth)
|> Map.get(:status_code)
您可以得到响应:
HTTPoison.post!(url, "select * from test;", headers, auth)
|> Map.get(:body)
|> Jason.decode!()
图案表
首先创建
SurreAldB中的每个单独的语句都在其自身交易中运行。
每个行都相对识别到表。到创建使用“ surql” DSL的行,我们在格式<table>:<id> and set 带有<key>=<value>的列表。
您可以将Surql查询传递到CLI或HTTP客户端或软件包。
CREATE dev:nelson SET name = 'nelson', status= 'founder';
[{"time":"4.1355ms","status":"OK","result":[{"id":"dev:nelson","name":"nelson","status":"founder"}]}]
当我们通过ID(:nelson)时,交易只能运行一次。当您不指定id时,SurreAldB将为您分配一个。请注意,您现在可以多次运行多次以下的创建查询,但是您可能不想要这个。
CREATE dev SET name = 'again', status='founder'
[{"id":"dev:kdofs33s4izrt04djc8s","name":"again","status":"founder"}]}]
您也可以使用INSERT INTO并传递json对象(您可以在其中指定id),也可以使用更多的sql,例如INSERT INTO ... VALUES:
INSERT INTO dev {id: 'bob_id', name: 'bob', status: 'trainee' };
INSERT INTO dev (id, name, status, id) VALUES ('mike', 'founder', 'mike');
我们检查表:
SELECT * FROM dev;
[{"id":"dev:bob_id","name":"bob","status":"trainee"},
{"id":"dev:kdofs33s4izrt04djc8s","name":"again","status":"founder"},
{"id":"dev:mike","name":"founder","status":"mike"},
{"id":"dev:nelson","name":"nelson","status":"founder"},
{"id":"dev:ssd3lt188dndo0a2afne","name":"again","status":"founder"}]
交易
您可以使用交易进行一组更改。您可以使用CREATE并传递params,也可以运行INSERT INTO并通过JSON对象。
BEGIN TRANSACTION;
CREATE dev:lucio SET name = 'lucio', status = 'dev';
INSERT INTO dev {name: 'nd', id: 'nd', status: 'trainee'};
COMMIT TRANSACTION;
多个插入物
您通过了一系列元组。您可以通过ID,或者如果您不需要立即检索它们,则可以为您执行超现实。
INSERT INTO dev [{name: 'Amy'}, {name: 'Mary', id: 'Mary'}];
第一行具有自动分配ID:
[{"id":"dev:mdfeausb4gata00vcxav","name":"Amy"},
{"id":"dev:Mary","name":"Mary"}]
这就是您可以序列化为SurseAldB A CSV文件的方式:
INSERT INTO users (id, name) VALUES ('a','a'),('b','b'),...
时间戳
我们可以使用futures。这是一个将在对记录访问的每个访问时都会动态计算的值。
例如,我们创建一个具有ID的记录,A(固定)“ Create_at”字段和A future 字段“ Updated_at”:
CREATE dev:1 SET
name='one',
created_at=time::now(),
updated_at=<future>{time::now()};
UPDATE dev:1 SET name='new one';
[{"created_at":"2023-02-21T20:42:07.978776Z",
"id":"dev:1","name":"new one",
"updated_at":"2023-02-21T20:42:36.468812Z"}]}]
记录链接
您可以使用 dot “。” 格式传递嵌套对象。请注意,我们如何将“ evepentper”表的记录链接传递到“ WebApp”表中。
CREATE app_table:surreal SET
app_name = 'surrealistic.com',
agency.team = [dev:nelson, dev:lucio, dev:nd],
agency.name = 'dwyl.com';
您可以等效地以JSON格式传递数据:
INSERT INTO app_table {
id: 'unreal',
app_name: 'unreal',
agency: {
name: 'dwyl.com',
team: [dev:nelson, dev:lucio]
}
};
UPDATE app_table:unreal SET app_name='unreal.com';
查询嵌套的记录,没有“加入”
我们可以在没有加入的情况下获得链接数据 dot .符号:
SELECT agency.team.*.name AS team, agency.team.*.status AS status
FROM app_table:surreal;
[{"team":["nelson","lucio","nd"],
"status":["founder","dev","trainee"]}}}]
我们可以通过使用Nested WHERE:
获得具有状态为“ DEV”的Devs的名称
SELECT app_name,agency.team[WHERE status='dev'].name AS dev
FROM app_table
WHERE agency.name = 'dwyl.com';
[{"app_name": "surrealistic.com", "dev": "lucio"},
{"app_name": "unreal.com", "dev": "lucio"}]
聚合查询
用array functions返回App_table行中的DEV数量。
SELECT * from array::len(app_table:unreal.agency.team);
[{"time":"218.125µs","status":"OK","result":[2]}]
您也可以使用count()。返回开发者的数量及其名称:
SELECT
app_name,
agency.name AS agency,
agency.team.*.name AS members,
count(agency.team) AS team_count
FROM app_table;
[{"agency":"dwyl.com","app_name":"surrealistic.com","members":["nelson","lucio","nd"],"team_count":3},
{"agency":"dwyl.com","app_name":"unreal.com","members":["nelson","lucio"],"team_count":2}]
类型功能
您可以使用将字符串转换为所需类型的type functions:
SELECT count() AS total, app_name
FROM type::table('app_table')
GROUP BY app_table;
[{"app_name":"surrealistic.com","total":2}]
您可以使用通用type:thing并传递对象和标识符:
SELECT * FROM type::thing('app_table', 'unreal');
[{"agency":{"name":"dwyl.com","team":["dev:nelson","dev:lucio"]},
"app_name":"unreal.com","id":"app_table:unreal"}]
参数和子征值
我们可以使用参数运行查询。给定WebApp,获取具有状态“ DEV”的团队成员的名称:
LET $status='dev'
LET $dev_team = (SELECT agency.team[WHERE status=$status] FROM app_table:unreal);
SELECT name, status from $dev_team;
[{"name": "lucio", "status": "dev"}]
图形连接
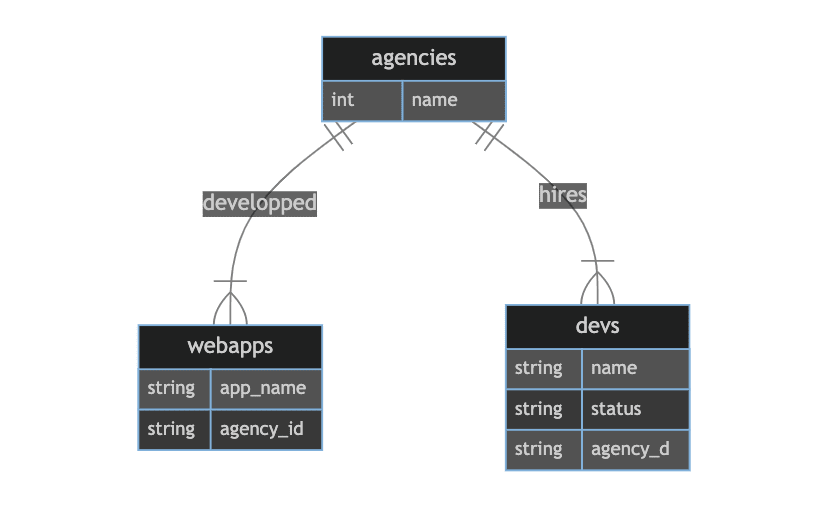
假设我们在代理商和WebApp之间有一个1-N的关系,以及代理商和开发人员之间的1-N关系。在传统数据库中,我们将在表WebApp(webApp allats_to agence)中有一个外键“ agention_id”,而开发表中的外键“ agence_id”(dev allates_to agence)。
使用SursteLDB,我们可以使用2种方法:
- 将[WebApp_ids]和一系列[dev_ids]的数组设置为表机构的字段,
- 或设置节点之间的连接。
链接记录数组
第一种方法的ERD如下所示:
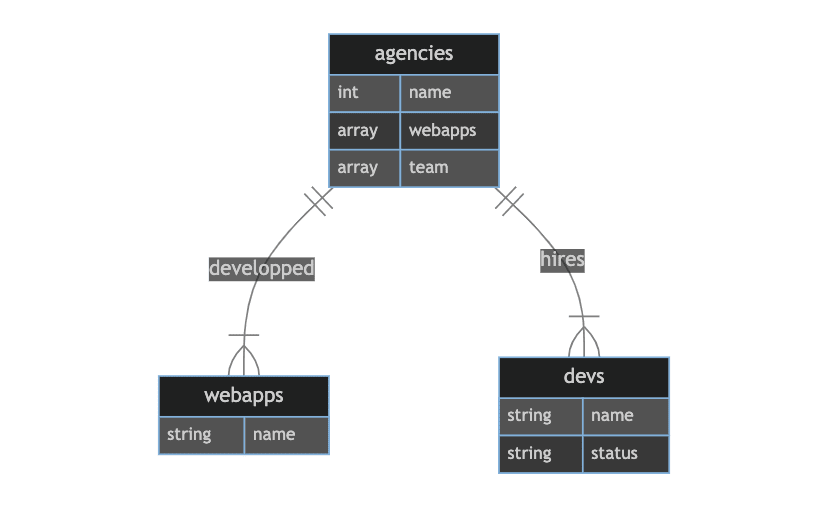
我们添加了一个字段“团队”和WebApps,该字段分别存储了所采用的Devs的所有引用和由代理商开发的WebApps。
BEGIN TRANSACTION;
create webapp:app1 set name = 'app1';
create webapp:app2 set name = 'app2';
create webapp:app3 set name = 'app3';
create developper:nelson set name = 'nelson', status = 'founder';
create developper:nd set name = 'nd', status = 'trainee';
create developper:lucio set name = 'lucio', status = 'dev';
create agency:dwyl1 set name = 'dwyl', project = [], team = [];
create agency:unreal1 set name = 'unreal', project = [], team = [];
update agency:dwyl1 set projects += [webapp:1, webapp:3];
update agency:unreal1 set projects += [webapp:2];
update agency:dwyl1 set team += [developper:nelson, developper:lucio];
update agency:unreal1 set team += [developper:nd];
COMMIT TRANSACTION;
,我们可以每个代理机构获得团队成员名称(通过省略ID),因为我们与记录链接有一个关系1-N:
SELECT name AS company, team.*.name AS employees FROM agency:dwyl1;
[{"company":"dwyl","employees":["nelson","lucio"]}]}]
相反,找到开发人员工作的代理商。我们使用了CONTAINS operator。
SELECT name AS company FROM agency WHERE team CONTAINS developper:nd;
[{"company":"unreal"}]}
连接
与连接的第二种方法如下所示。我们将2个动词“ works_for”和“开发”设置2个连接。这将生成其他2个表。
[dev:id]->works_for->[agency:id][agency:id]->developped->[webapp:id]
订单并不重要,因为在第一种情况下,它是1-1,在第二种情况下是1-N。事实证明,我们可以扭转我们将看到的链接。连接使用RELATE @from->verb->@to

BEGIN TRANSACTION;
CREATE agency:dwyl2 SET name = 'dwyl';
CREATE agency:unreal2 SET name = 'unreal';
RELATE developper:lucio->works_for->agency:dwyl2 CONTENT {owner: false, created_at: time::now()};
RELATE developper:nelson-> works_for->agency:dwyl2 CONTENT {owner: true, created_at: time::now()};
RELATE developper:nd->works_for->agency:unreal2 CONTENT {owner: true, created_at: time::now()};
RELATE agency:dwyl2->developped->webapp:app1;
RELATE agency:unreal2->developped->webapp:app2;
RELATE agency:dwyl2->developped->webapp:app3;
COMMIT TRANSACTION;
我们可以窥视协会表“ works_for”:
SELECT * FROM developped;
我们有一个协会[dev:id]->works_for->[agency:id]。我们可以查询给定 dev:id :
的 agenth.name
SELECT name, ->works_for->agency.name AS employer FROM developper:nelson;
[{"employer":["dwyl"],"name":"nelson"}]
我们现在希望所有为特定代理商工作的开发人员。我们只是恢复的关系:获取全部 dev:id from 代理:id :
SELECT name, <-works_for<-developper.name AS employees FROM agency:dwyl2;
[{"employees":["nelson","lucio"],"name":"dwyl"}]
同样,我们可以检查与[agency:id]->developped->[webapp:id]协会开发的机构开发的WebApps名称。
SELECT ->developped->webapp.name AS agency FROM agency:dwyl2;
[{"agency":["app1","app3"]}]
要查询开发给定的WebApp的代理商,我们扭转了查询:
SELECT <-developped<-agency.name AS agency FROM webapp:app2;
[{"employees":["nelson","lucio"],"name":"dwyl"}]
如果我们想要在给定的WebApp上使用的开发人员,我们可以运行 subqueries
LET $agency=(SELECT <-developped<-agency.id AS id FROM webapp:app1);
SELECT <-works_for<-developper.name AS employees FROM $agency;
[{"employees":[["nelson","lucio"]]}]
架构表
如果我们要执行固定的结构,我们可以使用DEFINE TABLE ... SCHEMAFULL定义模式。
我们将在下面检查此执行。
ERD显示一个带有3个表的ONE_TO_MANY_THROUGH关系。应用程序有很多用户,并且使用有一个细节。我们在应用程序和用户之间设置了1-N关系,用户和详细信息之间的1-1。我们详细阐述了2个示例:
- 一个带有3个表的表格,我们传递了一系列参考(应用程序< - [用户:id])和对另一个表的引用(用户< - 详细信息:id),
- 和一个带有2个表的表格,我们传递了参考文献数组(apps < - [用户:id])和一个对象(users.details {}),镜像Thrid Table。
如何通过一系列参考?
由于我们将在每个表中都有嵌套的数据,因此我们创建一个应该为另一个表的引用的字段。为此:
- 创建一个type
array的team在表“应用程序”中, - 并声明
record(users)类型的team.*,它引用了表“用户”的行。
对于表用户,我们与表详细信息有1-1关系。在上面提到的第一个情况下,我们添加了类型record(details)字段。在第二种情况下,我们声明了TYPE object的字段,并在表“用户”中声明了镜像未使用的“详细信息”表的嵌套字段。
我们还使用INDEX来执行唯一性。我们还展示了字段约束和默认值(带有VALUE $value)
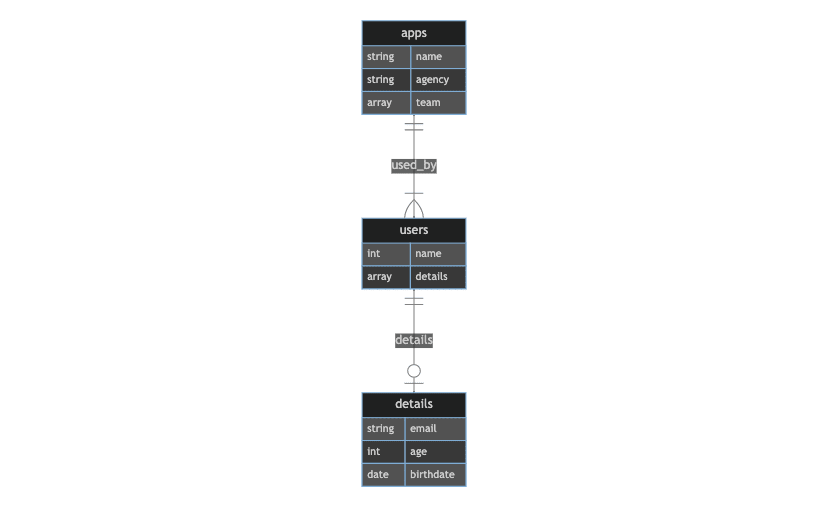
第3张桌子
Conn.sql("
BEGIN TRANSACTION;
DEFINE TABLE details SCHEMAFULL;
DEFINE FIELD email ON details TYPE string;
DEFINE FIELD age ON details type int ASSERT is::numeric($value) and $value>18;
DEFINE FIELD birthdate ON details TYPE string;
DEFINE TABLE users SCHEMAFUL;
DEFINE FIELD name ON users type string;
DEFINE FIELD details ON users TYPE record(details);
DEFINE INDEX users ON TABLE users COLUMNS name UNIQUE;
DEFINE TABLE apps SCHEMAFULL;
DEFINE FIELD name ON apps TYPE string;
DEFINE FIELD agency ON apps TYPE string VALUE $value OR 'dwyl';
DEFINE FIELD team ON apps TYPE array;
DEFINE FIELD team.* ON apps TYPE record(users);
DEFINE INDEX name ON TABLE apps COLUMNS name UNIQUE;
COMMIT TRANSACTION;
")
我们可以INSERT INTO(并设置:id)或CREATE SET。我们可以通过嵌套链接。 sursealdb understands dates。
BEGIN TRANSACTION;
INSERT INTO details {id: 'john', email: 'john@com', age: 20, birthdate: '2023-03-01'};
INSERT INTO users {name: 'john', id: 'john', details: details:john};
CREATE details:lucio SET email='lucio@com', age = 20, birthdate = '2023-03-01';
INSERT INTO users { id: 'lucio', name: 'lucio', details: details:lucio};
INSERT INTO users {name: 'nelson', id: 'nelson'};
INSERT INTO apps {id: 'test', agency: 'dwyl', team: []};
COMMIT TRANSACTION;
SELECT * FROM apps;
防止不良插入
让我们在“详细信息”表中插入“不良”记录:我们得到一个错误:
INSERT INTO details {gender: 'f', occupation: 'eng', age: 'twenty', id: 'wrong'};
[{"time":"427.541µs","status":"ERR",
"detail":"Found 0 for field `age`, with record `details:wrong`,
but field must conform to: is::numeric($value) AND $value > 18"}]
插入嵌套数组
让我们创建一个新的“开发”,并将他添加为团队成员:我们使用array:concat(doc)或简单的+=。
之前:
SELECT team from apps:test;
让我们更新并检查是否仅接受“用户”类型的数据:
UPDATE apps:test SET team += [users:nelson, users:lucio, 'ok'], bad = 'input';
之后:
SELECT team FROM apps:test;
没有“加入”的嵌套查询
让我们为代理商“ Dwyl”开发的所有应用程序的用户名称:
SELECT team.*.name FROM apps WHERE agency = 'dwyl'
[{"team":{"name":["nelson","lucio"]}}]
第二种情况:2张桌子
,我们没有定义第三个表“详细信息”,而是将TYPE object的对象作为表“用户”的字段,并将字段定义为嵌套属性(例如,details.owner)。由于我们定义了一个架构表,因此仍未过滤输入。例如,我们不能在talbe“用户”上的“详细信息”对象中传递额外属性。
BEGIN TRANSACTION;
DEFINE TABLE users1 SCHEMAFUL;
DEFINE FIELD name ON users1 type string;
DEFINE FIELD details ON users1 TYPE object;
DEFINE FIELD details.age ON users1 TYPE int;
DEFINE FIELD details.owner ON users1 TYPE bool;
DEFINE INDEX users1 ON TABLE users1 COLUMNS name UNIQUE;
DEFINE TABLE apps1 SCHEMAFULL;
DEFINE FIELD name ON apps1 TYPE string;
DEFINE FIELD agency ON apps1 TYPE string;
DEFINE FIELD team ON apps1 TYPE array;
DEFINE FIELD team.* ON apps1 TYPE record(users1);
DEFINE INDEX name ON TABLE apps1 COLUMNS name UNIQUE;
COMMIT TRANSACTION;
INSERT INTO users1 {
id: 1,
name: 1,
details: {
age: 20,
owner: false,
test1: 'bad'
}
};
INSERT INTO users1 {
id: 2,
name: 2,
details: {
age: 20,
owner: true
}
};
INSERT INTO apps1 {
name: 'app1',
agency: 'surreal',
team: [users1:1, users1:2, 'toto']
};
事件
让我们创建一个事件查询示例。当我们更改字段时,说表格详细信息的出生日期,我们想创建一个记录此新日期的新表。我们可以使用DEFINE EVENT:
DEFINE EVENT passed_birthdates ON TABLE details
WHEN $before.birthdate < $after.birthdate
THEN (
CREATE passed_birthdates SET birthdate = $after.birthdate
);
我们更新表“详细信息”的2行我们更改了生日:
BEGIN TRANSACTION;
UPDATE details:john SET birthdate='2023-03-02';
UPDATE details:lucio SET birthdate='2023-03-02';
COMMIT TRANSACTION;
我们检查字段中的更改是否触发了动作,以创建一个新表格,其中记录具有带有新日期的字段。
SELECT * FROM passed_birthdates;
我们有两个事件:
[{"time":"213.625µs","status":"OK","result":
[{"birthdate":"\"2023-03-02T00:00:00Z\"","id":"passed_birthdates:6i4cdsmue06v2rbfiwdt"},
{"birthdate":"\"2023-03-02T00:00:00Z\"","id":"passed_birthdates:i5ly5nxb1y3lo4knzkms"}]}]
注册用户
通过JWT提供注册
您可以使用有用的软件包SurrealEx(请参阅Elixir设置)
Elixir软件包SURSALEX设置
实验的活页:
![]()
您有两种设置包装SurrealEx的方法。首先,您设置了一个配置文件如下。
#config.exs
import Config
config :surreal_ex, Conn,
interface: :http,
uri: "http://localhost:8000",
ns: "testns",
db: "testdb",
user: "root",
pass: "root"
对于LiveBook,将下面的文件放入您的根目录中,然后在LiveBook的Mix.install中添加键config_path: "config.exs"。
Mix.install(
[{:surreal_ex, "~> 0.2.0"}],
config_path: "config.exs"
)
您可以使用模块SurrealEx.Config。让我们定义一个模块Conn包装配置。
defmodule Conn do
@config [
interface: :http,
uri: "http://localhost:8000",
ns: "test",
db: "test",
user: "root",
pass: "root"
]
use SurrealEx.Conn
def setup do
@config
|> SurrealEx.Config.for_http()
|> SurrealEx.Config.set_config_pid()
end
end
您描述了config:uri,(名称空间,数据库)和基本验证,然后将其传递给使用SurrealEx.Conn行为的Conn模块。
您运行设置:
Conn.setup()
cfg = SurrealEx.Config.get_config(Conn)
我们现在可以使用SursteLDB。用Conn.sql(query)包装时,上面的每个查询都可以运行。
如果您注册了用户,则会获得令牌,并可以使用Conn.sql(query, token)保护查询。
还有其他有趣的例程,特别是允许查询的SurrealEx.HTTP。