本文旨在伴随此视频:https://www.youtube.com/watch?v=yeML0vX0yLw
在本文中,我们想为您提供一个分步教程,在该教程中,我们建立了一个松弛的机器人,向我们发送有关股票新闻情感的每日信息。为此,我们需要一个可以:
的工具- 自动从新闻来源获取数据
- 从我们的ML模型中检索API调用以获取预测
- 将我们丰富的数据发送到Slack
我们将在Kern AI工作流程中构建Web刮板,在炼油厂标记我们的新闻文章,然后用Gates AI丰富数据。之后,我们将再次使用Workflow通过Webhook发送到Slack的预测和丰富数据。如果您想自行关注或探索这些工具,则可以在此处加入我们的候补名单:https://www.kern.ai/
让我们深入研究该项目!
在工作流程中刮擦数据
要开始,我们首先需要获取数据。当然,有一些可公开可用的数据集用于可用的股票新闻。但是我们有兴趣仅为特定公司建立情感分类器,理想情况下,我们希望新闻文章不太老,因此无关紧要。
我们在工作流程中启动项目。在这里,我们可以添加一个Python节点,我们可以通过该节点执行自定义Python代码。在我们的情况下,我们使用它来刮擦一些新闻文章。

有很多访问新闻文章的方法。我们决定使用Bing News API,因为它每月提供多达1000次免费搜索,并且相当可靠。但是,当然,您可以随心所欲地完成此部分!
为此,我们使用一个Python yield节点,该节点接收一个输入(刮擦结果),但可以返回多个输出(在这种情况下,每个发现的记录):
def node(record: dict):
from bs4 import BeautifulSoup
import requests
import time
from datetime import datetime
from uuid import uuid4
search_term = "AAPL" # You can make this a list and iterate over it so search multiple companies!
subscription_key = <YOUR_AZURE_COGNITIVE_KEY>
search_url = "https://api.bing.microsoft.com/v7.0/news/search"
headers = {"Ocp-Apim-Subscription-Key" : subscription_key}
params = {"q": search_term, "textDecorations": True, "textFormat": "HTML", "mkt": "en-US"}
response = requests.get(search_url, headers=headers, params=params)
response.raise_for_status()
search_results = response.json()
headers = ["name", "description", "provider", "datePublished", "url"]
record = {}
for i in headers:
if i == "provider":
providers = [article[i][0] for article in search_results["value"]]
names = []
for index in range(len(providers)):
for key in providers[index]:
if key == "name":
names.append(providers[index][key])
record[i] = names
else:
part_of_response = [article[i] for article in search_results["value"]]
record[i] = part_of_response
record["topic"] = [search_term] * len(record["name"])
# Scraper the collected urls
texts = []
for url in record["url"]:
try:
req = requests.get(url)
text = req.content
soup = BeautifulSoup(text, 'html')
results = soup.find_all('p')
scraped_text = [tag.get_text() for tag in results]
scraped_text_joined = " ".join(scraped_text)
texts.append(scraped_text_joined)
time.sleep(0.5)
except:
texts.append("Text not available.")
record["text"] = texts
for item in range(len(record)):
yield {
"id": str(uuid4()),
"name": record["name"][item],
"description": record["description"][item],
"provider": record["provider"][item],
"datePublished": record["datePublished"][item],
"url": record["url"][item],
"topic": record["topic"][item],
"text": record["text"][item],
}
之后,我们可以将数据存储在共享商店中。有两个商店节点,一个“共享商店发送”以将数据接收到商店和一个“共享商店读取”节点,您可以从中访问存储的数据并将其馈送到其他节点中。
我们可以在工作流的“商店”部分中创建共享商店。在商店部分中,您还将找到许多其他酷炫的商店,例如OpenAI的电子表格或LLM!

只需单击“添加存储”,然后给它一个合适的名称。之后,您可以在工作流中的节点中添加创建的存储。

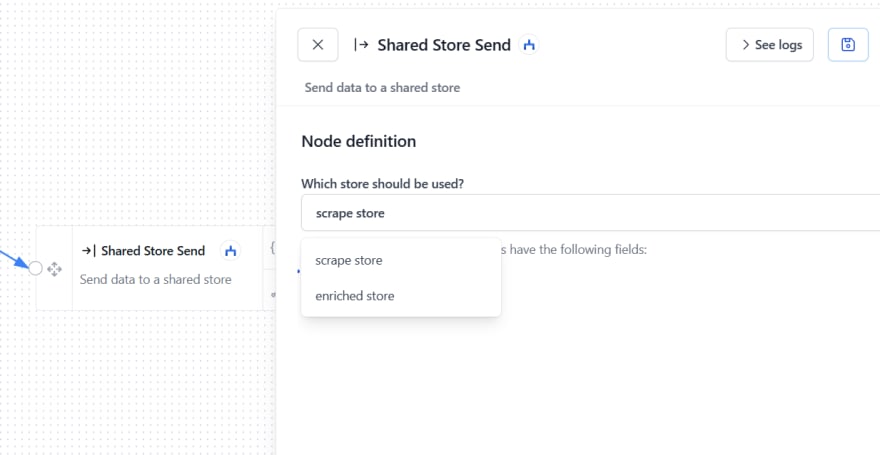
既然我们已经删除了一些数据,我们可以继续标记并处理它!
用大门丰富新传入数据

我们运行了网络刮板并收集了一些数据,我们就可以将共享商店与炼油厂同步。这将把我们所有的刮擦数据加载到炼油厂项目中。一旦我们再次运行刮板,新记录将自动加载到炼油厂项目中。
炼油厂是我们以数据为中心的文本数据IDE,我们可以使用它来快速,轻松地标记和处理我们的文章。

例如,我们可以创建启发式方法或称为活跃学习者的东西,以加快和半自动性标记过程。单击here以获取有关如何使用炼油厂标记和处理数据的快速入门教程。
一旦项目的结果令人满意,可以通过我们的第二个新工具(称为大门)通过API访问炼油厂模型的所有启发式方法。
在我们可以访问炼油厂项目之前,我们必须先去门,在那里打开我们的项目,然后在配置中启动我们的模型和/或启发式。

完成此操作后,我们将能够在Workflow中的门AI节点中选择跑步的模型。

门直接集成到工作流程中,我们不需要API代币来执行此操作。但是,当然,门API在工作流程之外也可用,为此,我们需要一个API令牌。但是,我们将在另一篇博客文章中介绍这一点。
我们通过大门传递了数据后,我们将词典作为一个响应,其中包含每个主动学习者和启发式方法的所有做出的预测和置信值。我们还返回了所有输入值,因此,如果您仅对结果感兴趣,我们必须进行一些过滤。下面的Python代码接收到门的响应,仅返回预测和主题。您可以为此使用普通的python节点。
def node(record: dict):
return {
"id": record["id"],
"prediction": record["prediction"]["results"]["sentiment"]["prediction"],
"stock": record["topic"],
}
之后,我们将过滤和丰富的结果存储在单独的商店中!
汇总情感
现在,我们得到了所有新闻文章,充满了情感预测。唯一剩下的就是汇总预测并将其发送出去。您可以通过电子邮件执行此操作,也可以将结果发送到Google表。在我们的示例中,我们将使用Webhook将汇总结果发送到专用的Slack频道。
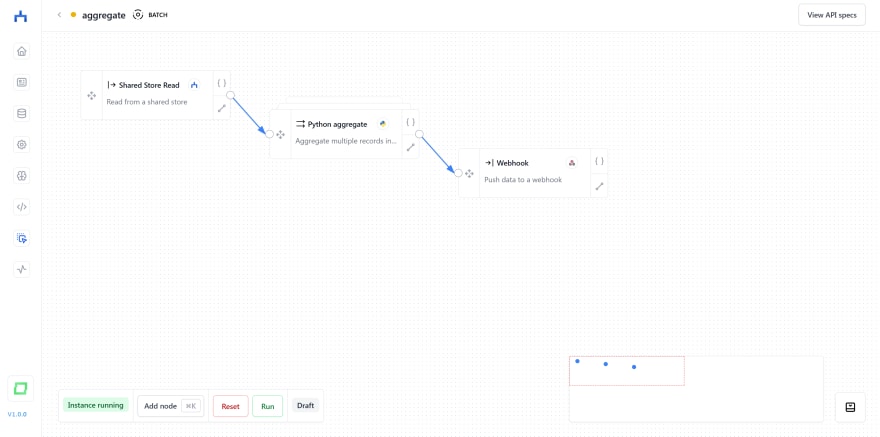
在我们的示例中,我们只是计算正面,中性和负面文章的数量,但是您也可以发出文章或文章文本片段的信心。为此,我们使用一个Python聚合节点,该节点可输入多个记录,但仅发送一个输出。这是此节点的代码:
def node(records: list[dict]):
from datetime import datetime
from uuid import uuid4
positive_count = 0
neutral_count = 0
negative_count = 0
for item in records:
if item["prediction"] == "rather positive":
positive_count += 1
elif item["prediction"] == "neutral":
neutral_count += 1
elif item["prediction"] == "rather negative":
negative_count += 1
return {
"id": str(datetime.today()),
"text": f"Beep boop. This is the daily stock sentiment bot. There were {positive_count} positive, {neutral_count} neutral and {negative_count} news about Apple today!"
}
然后,我们创建一个Webhook商店,添加Slack Channel的URL,然后将节点添加到我们的工作流程中。之后,我们可以运行工作流程,它应该向我们发送Slack消息!

这个简单的用例仅刮擦您可以使用KERN AI平台的表面,您可以自由自定义项目和工作流程满足您的需求!
如果您有任何疑问或反馈,请随时将其放在下面的评论部分中!