 |
|---|
| arquitectura del tall de python + kinesis firehose + s3 |
在此研讨会中,我们将学习如何使用Kinesis Data Firehose和S3处理AWS处理CSV文件。此外,我们将使用Python作为来自外部计算机的数据源将数据发送到消防流。
以前的要求:
- 一个AWS帐户,可访问Kinesis Data Firehose和S3。
- python 3.x安装在家中。
- 安装了Liberias Boto3和Pandas
步骤1:配置S3桶
我们必须做的第一件事是创建一个S3存储桶,我们将存储数据。为此,我们转到AWS控制台并选择S3。然后,我们单击“创建桶”植物体,然后按照说明命名存储桶并建立配置选项。
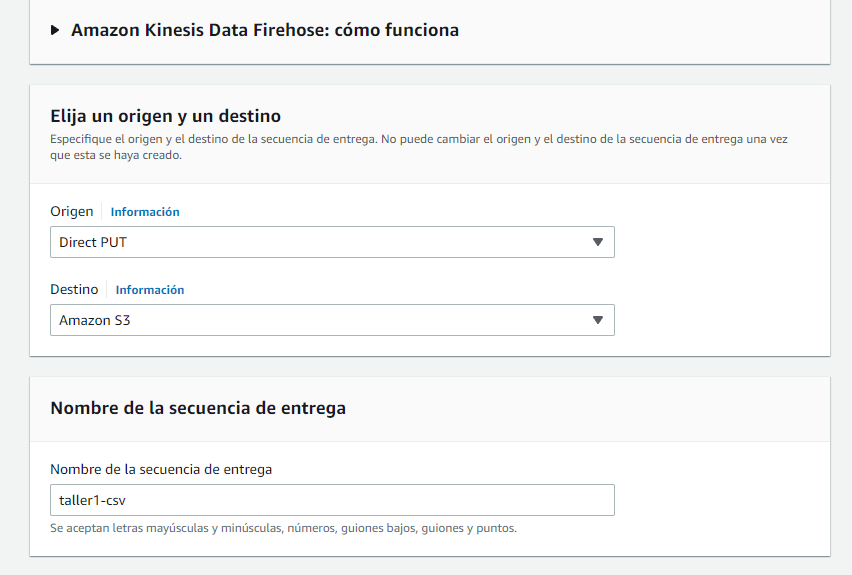
步骤2:配置运动式数据firehos
下面,我们创建了一个运动型数据FireHos,该流程将从我们的数据源接收数据,并将其存储在我们的S3存储桶中。为此,我们进入AWS控制台,然后选择“运动式数据firehos”。然后,我们单击“创建消防流”,然后按照说明命名我们的流程并建立配置选项。
用于配置选项:
-
我们将选择直接put
-
命运S3
-
输入序列名称该示例的任何名称都将放置Workshop1-CSV。放置的名称将成为服务的标识,该服务将接收我们稍后发送的图。
-
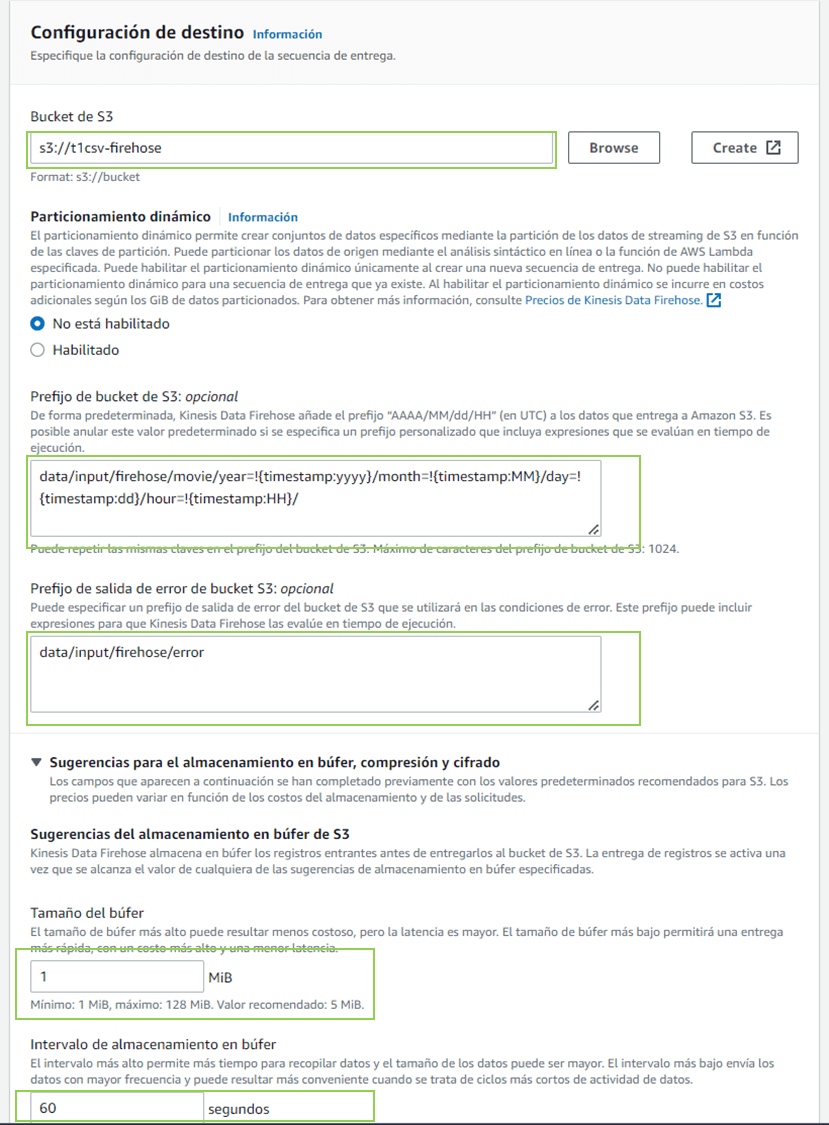
s3
桶前缀 data/input/firehose/movie/year =!{timestamp:yyyy}/month =!{timestamp:mm}/day =!{timestamp:dd}/hour =!{timestamp:hh}/p> -
存储桶错误输出前缀S3
数据/输入/firehose/错误
前缀在接收图或陷入错误时创建不存在的必要文件夹。
-
BOZFER 1 MIB(数据)
的大小
-
60秒Balfer中的存储间隔
用于Bozefer的配置,以便处理图,两个选项的大小或间隔
步骤3:配置数据源
在配置数据源之前,我们需要能够从外部计算机连接到AWS服务,我们需要为此创建一个访问密钥,必须执行以下步骤:
-
单击页面右上角的用户名,然后选择“我的安全凭据”(我的安全凭据)。
如果需要,请再次输入用户名并再次使用AWS用户名。 -
在“访问密钥”选项卡中。 单击“下载密钥文件”植物(下载键文件)以在.csv文件中下载访问密钥。您也可以将访问密钥和秘密密钥复制并粘贴到安全的地方。
-
请确保安全保存访问密钥的文件,因为它不会再次显示。如果您丢失了访问密钥,则应创建一个新的。
import boto3
import time
import json
import pandas as pd
AWS_ACCESS_KEY = #credenciales
AWS_SECRET_KEY = #credenciales
REGION_NAME = #Region
DeliveryStreamName = 'taller1-csv' #paso 2
firehose = boto3.client('firehose',aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=REGION_NAME
)
record = {}
bad_lines = []
column_names = ["MovieID", "YearOfRelease", "Title" ]
df = pd.read_csv("movie_titles.csv", encoding = "ISO-8859-1" , names=column_names , error_bad_lines=False)
for index, row in df.iterrows():
record = {'MovieID':row[0],
'YearOfRelease':row[1],
'Title':row[2]
}
response = firehose.put_record(
DeliveryStreamName = DeliveryStreamName,
Record = {
'Data': json.dumps(record)
}
)
print('Dato de movie enviado a Kinesis Data Firehose : \n' + str(record))
time.sleep(.5)
步骤4:将数据发送到运动型数据FireHos
的流程
现在,我们可以执行我们的Python脚本,并将数据发送到Kinesis Data Firehose的流程。数据将根据先前步骤中建立的配置进行转换并存储在我们的S3存储桶中。
步骤5:验证存储在S3
中的数据
最后,我们可以验证我们的数据是否已正确存储在我们的S3存储桶中。我们可以从AWS控制台访问我们的存储桶,并验证CSV文件已成为所需的格式。
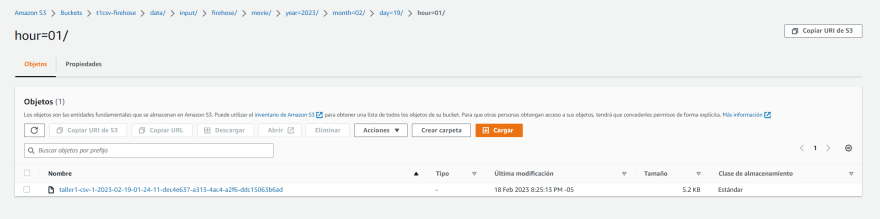
结论³n
在此研讨会中,我们已经学会了如何使用带有Kinesis Data Firehose和S3的AWS处理CSV文件。此外,我们已经使用Python作为数据源将数据发送到FireHos流。 AWS提供了广泛的服务和工具来处理和分析数据,这使得与大量云数据一起使用变得容易且可扩展。
** Despligue Con Cloud Formation **
Description: Stack Lab Firehose
Parameters:
NombreBucket:
Description: bucketS3
Type: String
Default: aws-firehose
Resources:
deliverystream:
DependsOn:
- deliveryPolicy
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamName: taller1-csv
ExtendedS3DestinationConfiguration:
BucketARN: !Join
- ''
- - 'arn:aws:s3:::'
- !Ref s3bucket
BufferingHints:
IntervalInSeconds: '60'
SizeInMBs: '1'
CompressionFormat: UNCOMPRESSED
Prefix: data/input/firehose/movie/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/
ErrorOutputPrefix: data/input/firehose/error
RoleARN: !GetAtt deliveryRole.Arn
s3bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Join [ -, [ !Ref NombreBucket, !Ref AWS::AccountId , 'movie' ] ]
deliveryRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Sid: ''
Effect: Allow
Principal:
Service: firehose.amazonaws.com
Action: 'sts:AssumeRole'
Condition:
StringEquals:
'sts:ExternalId': !Ref 'AWS::AccountId'
deliveryPolicy:
Type: AWS::IAM::Policy
Properties:
PolicyName: firehose_delivery_policy
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- 's3:AbortMultipartUpload'
- 's3:GetBucketLocation'
- 's3:GetObject'
- 's3:ListBucket'
- 's3:ListBucketMultipartUploads'
- 's3:PutObject'
Resource:
- !Join
- ''
- - 'arn:aws:s3:::'
- !Ref s3bucket
- !Join
- ''
- - 'arn:aws:s3:::'
- !Ref s3bucket
- '*'
Roles:
- !Ref deliveryRole