将被刮擦
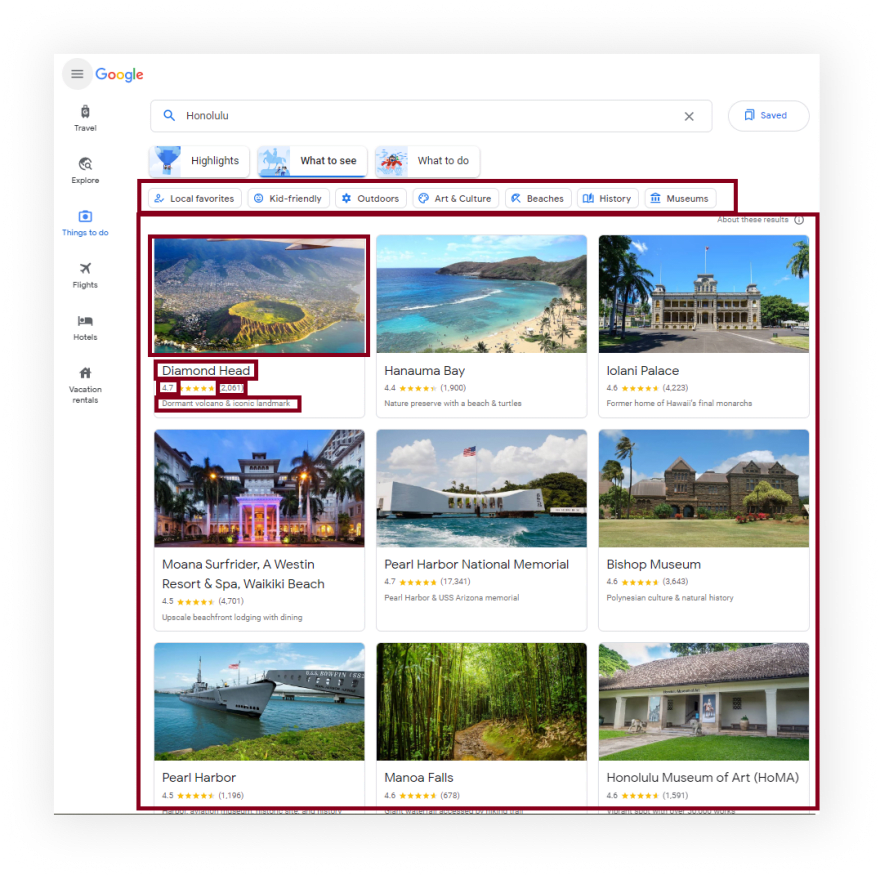
如果您不需要解释,请看一下the full code example in the online IDE
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
const searchQuery = "Honolulu";
const URL = `https://www.google.com/travel/things-to-do`;
async function getPlaces(page) {
const height = await page.evaluate(() => document.querySelector(".zQTmif").scrollHeight);
const scrollIterationCount = 10;
for (let i = 0; i < scrollIterationCount; i++) {
await page.mouse.wheel({ deltaY: height / scrollIterationCount });
await page.waitForTimeout(2000);
}
return await page.evaluate(() =>
Array.from(document.querySelectorAll(".f4hh3d")).map((el) => ({
thumbnail: el.querySelector(".kXlUEb img")?.getAttribute("src") || "No thumbnail",
title: el.querySelector(".GwjAi .skFvHc")?.textContent.trim(),
description: el.querySelector(".GwjAi .nFoFM")?.textContent.trim() || "No description",
rating: parseFloat(el.querySelector(".GwjAi .KFi5wf")?.textContent.trim()) || "No rating",
reviews:
parseInt(
el
.querySelector(".GwjAi .jdzyld")
?.textContent.trim()
.replace(/[\(|\)|\s]/gm, "")
) || "No reviews",
}))
);
}
async function getThingsToDoResults() {
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector("[type='text']");
await page.click("[type='text']");
await page.waitForTimeout(1000);
await page.keyboard.type(searchQuery);
await page.waitForTimeout(1000);
await page.keyboard.press("Enter");
await page.waitForSelector(".GtiGue button");
await page.click(".GtiGue button");
await page.waitForSelector(".f4hh3d");
await page.waitForTimeout(2000);
const options = Array.from(await page.$$(".iydyUc"));
const places = {
all: await getPlaces(page),
};
for (const option of options) {
await option.click();
await page.waitForSelector(".f4hh3d");
await page.waitForTimeout(2000);
const optionName = await option.$eval(".m1GHmf", (node) => node.textContent.trim());
places[`${optionName}`] = await getPlaces(page);
}
await browser.close();
return places;
}
getThingsToDoResults().then(console.log);
准备
首先,我们需要创建一个node.js* project并添加koude0包koude1,koude2和koude3以控制铬(或chrome或firefox,但现在我们仅在DevTools Protocol上使用铬在headless或无头模式中。
为此,在我们项目的目录中,打开命令行并输入:
$ npm init -y
,然后:
$ npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth
*如果您没有安装node.js,则可以download it from nodejs.org并遵循安装documentation。
ð注意:另外,您可以使用puppeteer无需任何扩展即可,但是我强烈建议将其与puppeteer-extra一起使用puppeteer-extra-plugin-stealth,以防止您使用无头铬或正在使用web driver的网站检测。您可以在Chrome headless tests website上检查它。下面的屏幕截图显示了差异。

目前,我们完成了项目的设置node.js环境,然后转到分步代码说明。
Process
我们需要从HTML元素中提取数据。通过SelectorGadget Chrome extension,获得合适的CSS选择器的过程非常容易,该过程能够通过单击浏览器中的所需元素来获取CSS选择器。但是,它并不总是完美地工作,尤其是当JavaScript大量使用该网站时。
如果您想了解更多有关它们的信息,我们在Serpapi上有专门的Web Scraping with CSS Selectors博客文章。
下面的GIF说明了使用Selectorgadget选择结果的不同部分的方法。

代码说明
声明koude1从puppeteer-extra Library和koude9控制Chromium浏览器,以防止网站检测到您正在使用puppeteer-extra-plugin-stealth库中使用web driver:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
接下来,我们“说” puppeteer使用StealthPlugin,编写搜索查询和搜索URL:
puppeteer.use(StealthPlugin());
const searchQuery = "Honolulu";
const URL = `https://www.google.com/travel/things-to-do`;
接下来,我们编写一个函数以获取页面的位置:
async function getPlaces(page) {
...
}
在此功能中,我们将使用下一个方法和属性获取必要的信息:
- koude13;
- koude14;
- koude15;
- koude16;
- koude17;
- koude18;
- koude19;
- koude20;
- koude21;
- koude22;
- koude23;
- koude24;
首先,我们需要滚动页面以加载所有缩略图。为此,我们获取页面卷轴,定义scrollIterationCount(如果并非所有缩略图已加载,则需要更大的值),然后在koude26循环中滚动页面:
const height = await page.evaluate(() => document.querySelector(".zQTmif").scrollHeight);
const scrollIterationCount = 10;
for (let i = 0; i < scrollIterationCount; i++) {
await page.mouse.wheel({ deltaY: height / scrollIterationCount });
await page.waitForTimeout(2000);
}
然后,我们从页面中获取并返回所有位置信息(使用koude13方法):
return await page.evaluate(() =>
Array.from(document.querySelectorAll(".f4hh3d")).map((el) => ({
thumbnail: el.querySelector(".kXlUEb img")?.getAttribute("src") || "No thumbnail",
title: el.querySelector(".GwjAi .skFvHc")?.textContent.trim(),
description: el.querySelector(".GwjAi .nFoFM")?.textContent.trim() || "No description",
rating: parseFloat(el.querySelector(".GwjAi .KFi5wf")?.textContent.trim()) || "No rating",
reviews:
parseInt(
el
.querySelector(".GwjAi .jdzyld")
?.textContent.trim()
.replace(/[\(|\)|\s]/gm, "") // this RegEx matches "(", or ")", or any white space
) || "No reviews",
}))
);
接下来,我们编写一个函数来控制浏览器,并从每个类别中获取信息:
async function getThingsToDoResults() {
...
}
首先,在此功能中,我们需要使用带有当前options的puppeteer.launch({options})方法来定义browser,例如headless: true和args: ["--no-sandbox", "--disable-setuid-sandbox"]。
这些选项意味着我们将headless模式和数组与arguments一起使用,我们用来允许在线IDE中启动浏览器流程。然后我们打开一个新的page:
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
接下来,我们将等待选择器的时间更改为60000毫秒(1分钟)的默认值(1分钟),以使用koude34方法,请使用koude36方法访问URL:
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
然后,我们等到"[type='text']"选择器加载(koude38方法),单击此输入字段并键入searchQuery(koude40方法),按“ Enter”按钮(koude41方法),然后单击“请参阅所有顶部瞄准器”按钮:
await page.waitForSelector("[type='text']");
await page.click("[type='text']");
await page.waitForTimeout(1000);
await page.keyboard.type(searchQuery);
await page.waitForTimeout(1000);
await page.keyboard.press("Enter");
await page.waitForSelector(".GtiGue button");
await page.click(".GtiGue button");
await page.waitForSelector(".f4hh3d");
await page.waitForTimeout(2000);
然后,我们定义places对象,并将信息从页面添加到all键:
const places = {
all: await getPlaces(page),
};
接下来,我们需要从页面中获取所有categories,并通过单击每个类别获取每个类别的所有位置信息,然后设置为带有类别名称的places对象键:
const categories = Array.from(await page.$$(".iydyUc"));
for (const category of categories) {
await category.click();
await page.waitForSelector(".f4hh3d");
await page.waitForTimeout(2000);
const categoryName = await category.$eval(".m1GHmf", (node) => node.textContent.trim());
places[`${categoryName}`] = await getPlaces(page);
}
最后,我们关闭浏览器,然后返回收到的数据:
await browser.close();
return places;
现在我们可以启动我们的解析器:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
输出
{
"all": [
{
"thumbnail": "https://encrypted-tbn1.gstatic.com/licensed-image?q=tbn:ANd9GcSNARkYcqi7DBwaNx9w-qMSlFVL_nYNTuu0bX8zgIswYAjlyIx9oIpilLInYWdr7xWXGdy2zSTyhYnO_GjbBYhOJQ",
"title": "Tonggs Beach",
"description": "Surfing and beach",
"rating": 4.4,
"reviews": 68
},
{
"thumbnail": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcRMnzB_-HjKVPLtoD-QSTeLiLbxb87JCCaKmiI_179MO1zj1uRo30CQ41icaJrOEihrQQYwXFpvojMpEg",
"title": "Kaluahole Beach",
"description": "Beach",
"rating": 2.5,
"reviews": 2
},
...and other places
],
"History": [
{
"thumbnail": "https://encrypted-tbn2.gstatic.com/licensed-image?q=tbn:ANd9GcRlsOO0zJJJhXHxJdoms3a0VSDHdTSOlARXlcyBI7THZ64LnuaSAuBdlvYYxliXdo8fO666Fu3QSisgG-cWt9pt-Q",
"title": "Pearl Harbor Aviation Museum",
"description": "Exhibits on WWII aviation in the Pacific",
"rating": 4.6,
"reviews": 4
},
{
"thumbnail": "https://encrypted-tbn1.gstatic.com/licensed-image?q=tbn:ANd9GcSgKRnVx6y-cH0Jq-h64UDAc50iwHHMOaARxnQN8xH2n_CBGIMSgQM0QGTs_qZWY65VS0sOtmgLEN9rI87k03MQiA",
"title": "Bishop Museum",
"description": "Polynesian culture & natural history",
"rating": 4.6,
"reviews": 3
},
...and other places
],
...and other categories
}
如果您想在此博客文章中添加其他功能,或者您想查看Serpapi,write me a message的某些项目。
添加一个Feature Requestð«或Bugð