在这篇文章中,我们将学习如何使用Python Tkinter制作一个简单的GUI CLI Translator应用程序,类似于此博客文章的封面。
在开始之前,请安装Python和PIP,如果您还没有。然后,阅读我们将使用的包装的文档。
该项目已经在Python_Tkinter_Example存储库上完成。如果您想先自行测试,请在下面使用以下这些命令。
$git clone https://github.com/steadylearner/Python_Tkinter_Example.git
$cd Python_Tkinter_Example
$python3 -m venv app
$source app/bin/activate
$pip install -r requirements.txt
$python main.py
您还需要在计算机上安装FFMPEG。否则,找到这样的命令使其在您的机器上工作。
$brew install ffmpeg --force
$brew link ffmpeg
然后,您可以查看它是否使用$ffmpeg -h命令安装。
测试这些命令,您将看到Python GUI应用程序。您可以在输入文本表单上键入要翻译的内容,它将在下面的翻译文本表单中显示翻译的文本。
您可以清除剪贴板中的文本,将文本复制到剪贴板,然后使其与按钮重复说话。
您还可以使用顶部的菜单将您的麦克风,文本文件或音频文件作为文本输入。如果需要,您还可以保存翻译的文本或音频文件。
您还可以编辑表单设置,以便如何适用于您的首选语言和声音,类似于下图。
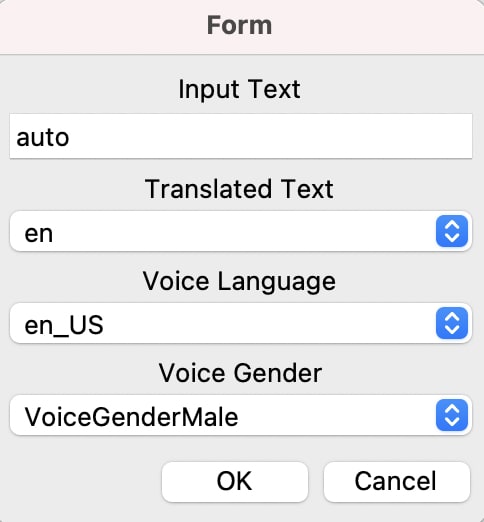
您可以在settings.py上找到它们的默认值。
TRANSLATED_TEXT_OPTIONS = [
"en",
]
VOICE_LANGUAGE_OPTIONS = [
"en_US",
]
VOICE_GENDER_OPTIONS = ["VoiceGenderMale", "VoiceGenderFemale", "None"]
您可以更新translated_text_options,voice_language_options和这些值并不总是很好地工作。因此,您需要在机器上测试自己。
这些将足以测试应用程序。
在我们开始查看应用程序如何使用详细信息之前,请先阅读这些。
阅读此帖子后,它将帮助您制作自己的组件和菜单。
此TKInter应用程序的输入点将是main.py文件。这将是此AP的最重要部分。
首先,您可以在末尾看到代码段。
if __name__ == "__main__":
if len(read_settings("form")) == 0:
upsert_settings(
"form",
{
"input_text": "auto",
"translated_text": "en",
"voice_language": "en_US",
"voice_gender": "VoiceGenderMale",
},
)
window.mainloop()
在这里,我们使用Python tinydb保存应用程序设置,您还可以使用另一个简单的数据库选项。包括在这里使用python。
if len(read_settings("form")) == 0:
upsert_settings(
"form",
{
"input_text": "auto",
"translated_text": "en",
"voice_language": "en_US",
"voice_gender": "VoiceGenderMale",
},
)
我们将表单设置保存到db.json,除非它已经在设置上。然后,我们使用window.mainloop() part启动应用程序。
tinydb相关代码片段保存在database.py
from tinydb import TinyDB, Query
db = TinyDB("db.json")
query = Query()
settings = db.table("settings")
def read_settings(name):
return settings.search(query.name == name)
def upsert_settings(name, details):
settings.upsert({"name": name, "details": details}, query.name == name)
def read_input_text_language():
return read_settings("form")[0]["details"]["input_text"]
def read_translated_text_language():
return read_settings("form")[0]["details"]["translated_text"]
def read_voice_language():
return read_settings("form")[0]["details"]["voice_language"]
def read_voice_gender():
return read_settings("form")[0]["details"]["voice_gender"]
在这里,我们将表单设置的一些读取和UPSERT功能保存到函数,以便我们可以轻松地在应用程序的其他部分重复使用。
我们只需要为表单设置保存一个条目。您可以在此处包含更多的设置,以供此处保存在此处以供自定义应用程序。
然后,有GoogleTranslator和recognizer和microphone
它们用于识别用于输入表单的音频文件中的文本,并使用麦克风变量在计算机上使用麦克风。
您可以阅读文档以查看更多详细信息。
import speech_recognition as sr
from deep_translator import GoogleTranslator
recognizer = sr.Recognizer()
microphone = sr.Microphone()
这些将是使该应用程序在后面工作的主要部分。您可以在下面的辩论函数上看到它的第一个用法。
每当用户键入某种内容时,它将输入文本转换为您在设置上设置的内容。它被拒绝了一秒钟,因为我们用于此应用程序的Google Translator服务有一定的速率限制。
这将防止在用户类型类型时发送请求并阻止应用程序工作。
input_text_value = tk.StringVar()
@debounce(1)
def on_input_text_value_update(event):
input_text_value.set(input_text.get("1.0", tk.END))
translated = GoogleTranslator(
source=read_input_text_language(), target=read_translated_text_language()
).translate(input_text_value.get())
if read_voice_gender() != "None" and len(translated) != 0:
q.put(translated)
translated_text.config(state="normal")
translated_text.replace("1.0", tk.END, translated)
translated_text.config(state="disabled")
input_text.bind("<KeyRelease>", on_input_text_value_update)
在这里,我们使用input_text_value.set(input_text.get("1.0", tk.END))将输入文本形式值保存到input_text_value = tk.StringVar()并读取它的翻译值。
带有线程的队列与q.put(translated)一起使用,因为没有它的pyttx使用扬声器的代码无法正常工作。
import pyttsx3
import threading
import queue
from tkinter import messagebox
from database import (
read_voice_language,
read_voice_gender,
)
class TTSThread(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self.queue = queue
self.daemon = True
self.engine = pyttsx3.init()
self.start()
def run(self):
self.engine.startLoop(False)
t_running = True
while t_running:
if self.queue.empty():
self.engine.iterate()
else:
data = self.queue.get()
# print("data")
# print(data)
if data == "exit":
t_running = False
else:
if self.change_voice(read_voice_language()) == True:
# self.engine.setProperty('rate', 10)
self.engine.say(data)
self.engine.endLoop()
def change_voice(self, language):
gender = read_voice_gender()
# print("gender")
# print(gender)
lang_correct = False
gender_correct = False
for voice in self.engine.getProperty("voices"):
if language in voice.languages:
lang_correct = True
if gender == voice.gender:
gender_correct = True
self.engine.setProperty("voice", voice.id)
break
else:
gender_correct = False
messagebox.showerror(
message="Gender '{}' not found for {}, update it at languages settings if you don't want to see this error".format(
gender, language
)
)
break
# print("")
if lang_correct == False and gender_correct == False:
messagebox.showerror(
message="Language '{}' not found, update Translated Voice if you don't want to see this error".format(
language, gender
)
)
# Both should be True to speak
return lang_correct and gender_correct
# create a queue to send commands from the main thread
q = queue.Queue()
tts_thread = TTSThread(q) # note: thread is auto-starting
在这里,我们在计算机中使用来自TKINTER的MessageBox在计算机中不可用的任何表单设置选项都向用户显示有用的错误消息。
您可以在表单设置上使用其他选项对其进行测试,您将看到与此类似的错误。

messagebox.showerror(
message="Language '{}' not found, update Translated Voice if you don't want to see this error".format(
language, gender
)
)
那么,如果read_voice_gender() != "None"是True,或者如果输入文本中没有文本,则我们不会将队列发送给扬声器以讲翻译后的文本。否则,您会听到机器的声音。这包括在内,因为并非总是有一个语言的声音。如果您不想看到警告,则可以将Voice_gender_options设置为无。
translated_text.config(state="normal")
translated_text.replace("1.0", tk.END, translated)
translated_text.config(state="disabled")
要保存翻译文本,默认情况下翻译的_text是不可编辑的,但是,在这里我们首先保存翻译文本,并在上面的代码片段中再次使其不正确。
在此之前,我们学会了如何使您的输入文本翻译并听到。它用于GUI应用程序,但您也可以在Web应用程序或其他项目中使用它。
我们仍然有一些布局的部分。
window = tk.Tk()
window.title(APP_TITLE)
window.rowconfigure(0, weight=1)
window.columnconfigure(1, weight=1)
menubar = Menu(window)
window.config(menu=menubar)
translation_form = tk.Frame(window)
translation_form.grid(row=0, column=1, sticky="nsew")
input_text_label = tk.Label(
translation_form, text="Input Text", anchor="w", font=LABEL_FONT, padx=10, pady=10
)
input_text_label.grid(row=0, column=1, sticky="ew")
input_text = tk.Text(translation_form, font=TEXT_FONT, height=15)
input_text.grid(row=2, column=1, sticky="ew")
input_text_value = tk.StringVar()
首先,我们使用window = tk.Tk()启动应用程序,并使用window.title(APP_TITLE)设置标题。您可以在settings.py上编辑应用程序标题以使用另一个标题。窗口这是您的GUI应用程序的顶级组件。 winfo_toplevel()很容易访问,我们将稍后看到。您无需将其传递给其他组件即可通过使用其他组件。
然后,我们设置了Menubar并分配到窗口。
menubar = Menu(window)
window.config(menu=menubar)
您可以看到您可以在此处包含sub menubars。
menubar.add_cascade(
label="File",
menu=FileMenu(window, q, input_text, translated_text, recognizer, microphone),
underline=0,
)
settings = Menu(menubar, tearoff=0)
settings.add_command(label="Form", command=lambda: show_form_settings_dialog(window))
![]()
FileMenu这是一个组件,您可以看到它在内部使用window, q, input_text, translated_text, recognizer, microphone变量。
class FileMenu(Menu):
def __init__(self, master, q, input_text, translated_text, recognizer, microphone):
super().__init__(master)
self.q = q
self.input_text = input_text
self.translated_text = translated_text
self.recognizer = recognizer
self.microphone = microphone
use_sub_menu = Menu(self, tearoff=0)
use_sub_menu.add_command(
label="Mic for Input Text", command=self.use_mic_for_input_text
)
use_sub_menu.add_command(
label="Text File for Input Text", command=self.use_text_file_for_input_text
)
use_sub_menu.add_command(
label="Audio File for Input Text",
command=self.use_audio_file_for_input_text,
)
self.add_cascade(label="Use", menu=use_sub_menu)
save_sub_menu = Menu(self, tearoff=0)
save_sub_menu.add_command(
label="Translated Text to a text file",
command=self.save_translated_text_to_text_file,
)
save_sub_menu.add_command(
label="Translated Text to an audio file",
command=self.save_translated_text_to_audio_file,
)
self.add_cascade(label="Save", menu=save_sub_menu)
self.add_separator()
self.add_command(label="Close", command=self.master.destroy)
def use_mic_for_input_text(self):
"""Use a mic for input text"""
what_you_said = recognize_speech_from_mic(self.recognizer, self.microphone)
if what_you_said["error"]:
messagebox.showerror(title="Error", message=what_you_said["error"])
return
if not what_you_said["success"]:
messagebox.showerror(
title="Error", message="I couldn't read that. What did you say?"
)
return
if what_you_said["transcription"] == None:
messagebox.showerror(
title="Error", message="Please, say something next time."
)
else:
text = what_you_said["transcription"]
translated = GoogleTranslator(
source=read_input_text_language(),
target=read_translated_text_language(),
).translate(text)
self.q.put(translated)
if len(self.input_text.get("1.0", END)) > 0:
self.input_text.insert(END, f" {text}")
self.translated_text.insert(END, f" {translated}")
else:
self.input_text.insert(END, f"{text}")
self.translated_text.insert(END, f"{translated}")
def use_text_file_for_input_text(self):
"""Use a text file for input text."""
filepath = askopenfilename(
filetypes=[("Text Files", "*.txt"), ("All Files", "*.*")]
)
if not filepath:
# messagebox.showerror(title="Error", message="Use the correct filepath for the text file")
return
self.input_text.delete("1.0", END)
self.translated_text.delete("1.0", END)
with open(filepath, mode="r", encoding="utf-8") as input_file:
text = input_file.read()
self.input_text.insert(END, text)
translated = GoogleTranslator(
source=read_input_text_language(),
target=read_translated_text_language(),
).translate(text)
self.q.put(translated)
self.translated_text.config(state="normal")
self.translated_text.replace("1.0", END, translated)
self.translated_text.config(state="disabled")
self.master.title(f"{APP_TITLE} - {filepath}")
# self.winfo_toplevel().title(f"{APP_TITLE} - {filepath}")
def use_audio_file_for_input_text(self):
"""Use an audio file for input text."""
filepath = askopenfilename(
filetypes=[("Audio Files", "*.mp3"), ("Audio Files", "*.wav")],
)
if not filepath:
# messagebox.showerror(
# title="Error", message="Use the correct filepath for the audio file")
return
# mp3
# print("filepath")
# print(filepath)
# to wav file to use sr.AudioFile
if filepath.endswith("mp3"):
filepath_without_ext = filepath.split(".")[0]
new_wav_filepath = f"{filepath_without_ext}.wav"
subprocess.call(["ffmpeg", "-y", "-i", filepath, new_wav_filepath])
audio = sr.AudioFile(new_wav_filepath)
response = messagebox.askquestion(
title=None,
message="To use the mp3 file for the app, we had to make the file with .wav extension, do you want to remove the original mp3 file?",
)
if response == "yes":
os.remove(filepath)
messagebox.showinfo(message=f"The mp3 file at {filepath} was removed")
else:
audio = sr.AudioFile(filepath)
with audio as source:
# This doesn't work here.
# recognizer.adjust_for_ambient_noise(source)
audio = self.recognizer.record(source)
try:
transcription = str(
self.recognizer.recognize_google(audio, show_all=False)
)
self.input_text.delete("1.0", END)
self.translated_text.delete("1.0", END)
self.input_text.insert(END, transcription)
translated = GoogleTranslator(
source=read_input_text_language(),
target=read_translated_text_language(),
).translate(transcription)
self.q.put(translated)
self.translated_text.config(state="normal")
self.translated_text.replace("1.0", END, translated)
self.translated_text.config(state="disabled")
self.master.title(f"{APP_TITLE} - {filepath}")
# self.winfo_toplevel().title(f"{APP_TITLE} - {filepath}")
except:
messagebox.showinfo("Something went wrong while reading the audio file")
def save_translated_text_to_text_file(self):
"""Save the translated_text as a new file."""
filepath = asksaveasfilename(
defaultextension=".txt",
filetypes=[("Text Files", "*.txt"), ("All Files", "*.*")],
)
if not filepath:
return
with open(filepath, mode="w", encoding="utf-8") as output_file:
translated = self.translated_text.get("1.0", END)
output_file.write(translated)
messagebox.showinfo(message=f"The file was saved")
self.master.title(f"{APP_TITLE} - {filepath}")
# self.winfo_toplevel().title(f"{APP_TITLE} - {filepath}")
def save_translated_text_to_audio_file(self):
"""Save the translated_text as a new file."""
# Should be wav instead of mp3
filepath = asksaveasfilename(
defaultextension=".mp3",
filetypes=[("Audio Files", "*.mp3"), ("All Files", "*.*")],
)
if not filepath:
return
with open(filepath, mode="w", encoding="utf-8") as output_file:
translated = self.translated_text.get("1.0", END)
tts = gtts.gTTS(
text=translated, lang=read_translated_text_language()
) # Include it for settings or input bar for text input or dropdown
tts.save(filepath) # mp3
messagebox.showinfo(message=f"The file was saved")
self.master.title(f"{APP_TITLE} - {filepath}")
# self.winfo_toplevel().title(f"{APP_TITLE} - {filepath}")
它具有多种方法,您可以使用文本或音频文件作为文本输入源,或将翻译的文本保存到文本或音频并稍后重复使用。
ffmpeg与subprocess一起使用将mp3文件转换为wav扩展名,因为这里使用的某些软件包允许不同的文件格式。
subprocess.call(["ffmpeg", "-y", "-i", filepath, new_wav_filepath])
请在使用$python main.py测试应用程序时使用每个选项,尤其是“输入文本”选项。
组件文件夹中还有其他文件,但它们执行所有类似的操作,因此请自己阅读并测试应用程序。
如果您愿意,可以使用$python cli.py build app命令制作二进制可执行文件。
它在后面使用pyinstaller命令,如果您想了解更多详细信息,请阅读他们的文档。
当您本地测试该应用程序时,它可能会使用机器的大量资源。但是,当您使用命令构建的二进制应用测试时,它将不会遇到这个问题。
您可以在DIST文件夹中对其进行测试,您将能够使用它而无需与您的控制台进行本地工作。
You can contact or hire me at Telegram.
谢谢,请与他人分享此帖子。