这并不像其他所有ChatGpt博客,但是在这里我们将尝试了解promptify将如何与LLM(大型语言模型)一起使用,例如Chatgpt,例如执行 ner nertity识别(NER)与直接使用chatgpt相比,这种方法如何强大。
有趣的外卖
- 如何使用提示用于及时工程
- 简单命名实体识别(NER)使用Promtify+Chatgpt
- 自定义标签使用ProMTIFY+CHATGPT 用于指定实体识别(NER)
- 使用ProMTIFY+CHATGPT 一击命名实体识别(NER)
- 使用promtify+chatgpt 的域知识命名实体识别(NER)
让我们开始...
什么是及时的工程和提示
提示工程是一种自然语言处理(NLP)概念,涉及发现/创建输入,从而产生理想或有用的结果。提示等同于告诉魔术灯中的精灵该怎么做。在这种情况下,魔术灯是 chat-gpt ,准备回答我们的任何问题, promtify 用于以这种方式构建和构建我们的问题像chatgpt这样的llms更好地理解问题并提供理想的结果。
什么命名实体识别(NER)
实体可以定义为文本中的关键信息。一个实体可以是一个单词或一组单词。 命名实体识别(NER)可以定义为 识别的过程> 实体(关键信息)文本。
示例


在这里人,国家/势头它们所属的称为命名实体识别(NER)。
究竟要做什么?

诸如chatgpt之类的LLM的输入和输出通常是普通的非结构化文本,但是当您通过某些参数(其中许多是可选的)将其传递给Quistify(其中许多是可选的)时,Promptify发送这些LLMS a 结构化输入是等同于问一个正确结构化的问题,这将帮助这些LLM更好地理解问题。然后以 python对象。
输出 - 普通Chatgpt vs Promtify+Chatgpt
我们将要求chatgpt在纯文本上执行命名实体识别,我们还将告诉我们输入句子所属的域,然后我们将尝试使用strivefify给出相同的输入,让我们观察响应。
普通chatgpt
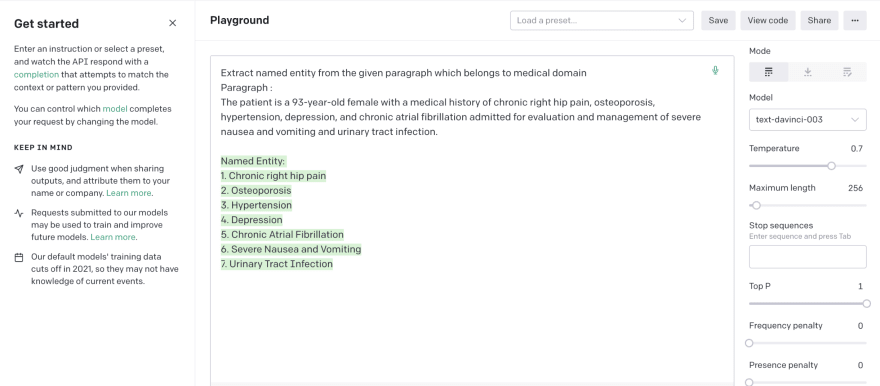
在尝试再次尝试时,输出结构很有可能会有所不同,并且在应用程序中使用此输出相对难以使用,因为该结构在每个查询时可能会有所不同。
PROMTIFY+CHATGPT

实体(e)及其相应的类/类型(t)作为python对象返回。而且,您还可以观察到,通过促使更多实体被识别时。现在,相对而言,这是一个更强大的输出,可以轻松地在应用程序中使用。
现在,让我们检查一下提示的Python实现,代码实现是使用 Google Colab 来帮助解释更好的...
提示 - chatgpt
%%capture
!git clone https://github.com/promptslab/Promptify.git
!pip3 install openai
克隆提示存储库并安装OpenAI库
# Define the API key for the OpenAI model
api_key = ""
粘贴通过遵循此博客How to generate API secret key
生成的API键
# Create an instance of the OpenAI model, Currently supporting Openai's all model, In future adding more generative models from Hugginface and other platforms
model = OpenAI(api_key)
nlp_prompter = Prompter(model)
创建一个OpenAI模型的实例,然后将其传递到促进的 prompter ,现在您有了一个对象,可以使用所需的参数传递提示。
# Example sentence that is sent to GPT
sent = "The patient is a 93-year-old female with a medical history of chronic right hip pain, osteoporosis, hypertension, depression, and chronic atrial fibrillation admitted for evaluation and management of severe nausea and vomiting and urinary tract infection"
此样本输入与医疗领域有关,它与患者的医疗状况有关。
带有2行代码的命名实体识别(NER)
# Named Entity Recognition with No labels, no description, no oneshot, no examples
# Simple prompt with instructions
# domain name gives more info to model for better result generation, the parameter is optional
# Output will be python object -> [ {'E' : Entity Name, 'T': Type of Entity } ]
result = nlp_prompter.fit('ner.jinja',
domain = 'medical',
text_input = sent,
labels = None)
# Output
pprint(eval(result['text']))
在输出中
e - 实体
t - 类型/类实体属于
如果您观察到输出,则输出为 python对象,并且与CHATGPT的原始输出相比,结构是。 将LLMS与应用程序集成时,来自distify的此功能/功能可能非常有用。 域参数是可选的,并且将域传递到您的提示中会导致更好的响应。
这并不是全部关于提示....
命名实体识别(NER)的自定义标签
您还可以提供自定义标签,以便从提示中确定自定义标签及其相应的实体。
# If want to perform NER with custom tags only (handling out-of-bounds prediction) prompt
result = nlp_prompter.fit('ner.jinja',
domain = 'medical',
text_input = sent,
labels = ["SYMPTOM", "DISEASE"])
# Output
pprint(eval(result['text']))

您可以从输出中观察到属于所提供的自定义标签的实体已确定。
一镜头 - 命名实体识别(NER)
One shot learning顾名思义,是模型使用一个培训数据理解的能力。这真是令人着迷,借着像GPT这样的强大LLM,在提示的帮助下,您实际上可以做到。
one_shot_training_data = "Leptomeningeal metastases (LM) occur in patients with breast cancer (BC) and lung cancer (LC). The cerebrospinal fluid (CSF) tumour microenvironment (TME) of LM patients is not well defined at a single-cell level. We did an analysis based on single-cell RNA sequencing (scRNA-seq) data and four patient-derived CSF samples of idiopathic intracranial hypertension (IIH)"
one_shot_labelled_training_data = [[one_shot, [{'E': 'DISEASE', 'W': 'Leptomeningeal metastases'}, {'E': 'DISEASE', 'W': 'breast cancer'}, {'E': 'DISEASE', 'W': 'lung cancer'}, {'E': 'BIOMARKER', 'W': 'cerebrospinal fluid'}, {'E': 'DISEASE', 'W': 'tumour microenvironment'}, {'E': 'TEST', 'W': 'single-cell RNA sequencing'}, {'E': 'DISEASE', 'W': 'idiopathic intracranial hypertension'}]]]
result = nlp_prompter.fit('ner.jinja',
domain = 'medical',
text_input = sent,
examples = one_shot_labelled_training_data,
labels = ["SYMPTOM", "DISEASE"])
pprint(eval(result['text']))
在这里,您仅提供了标签症状和疾病的模型的标记数据
e - 该实体属于
的标签/类
W - 实体

您可以从输出中观察到属于特定标签的实体(症状,疾病),这些实体被准确地识别出一声训练数据中的特定标签(症状,疾病)及其相应的标签。
命名实体识别 - 具有领域知识
#If want to give some domain knowledge and description in prompt to enhance the output
result = nlp_prompter.fit('ner.jinja',
domain = 'clinical',
text_input = sent,
examples = one_shot_labelled_training_data,
description = "Below Paragraph is from discharge summary of a patient. The Paragraph describes the condition and symptoms of patient.",
labels = ["SYMPTOM", "DISEASE"])
pprint(eval(result['text']))
如果您有领域知识,在上述情况下,临床领域以及对数据的描述的一小部分描述,则可以在 Description 参数中传递,这将进一步提高输出。

您现在只是刮擦了LLMS与Promtify一起使用时可以做的事情的表面。还有更多博客。