我过去计划要做的是学习如何以编程方式将人声与曲目分开,而不是依赖软件即服务以执行与轨道的人声分离。本文展示了如何使用我最喜欢的图书馆Librosa将歌曲的人声与乐器分开。您可以检查Google Colab Notebook here。
当我想分开歌曲的单个曲目时,这个想法引发了这个想法,所以我去了Product Hunt并发现了melody ml。这一发现开始了学习音乐硕士的冲动,因此发现了python图书馆。
。顺便说一句,我用完了 ram ,这使我的笔记本


 吨型@tonypoppinss
吨型@tonypoppinss 有些东西崩溃了! waaaaaaaa10:34 AM- 2023年1月31日
有些东西崩溃了! waaaaaaaa10:34 AM- 2023年1月31日


安装和导入依赖项
pip install librosa matplotlib IPython
import librosa
from librosa import display
import numpy as np
import IPython.display as ipd
import matplotlib as plt
加载并显示歌曲。
我想知道咆哮或大喊歌曲的一部分会出现。
y, sr = librosa.load('My Last Serenade.wav')
ipd.Audio(data=y[90*sr:110*sr], rate=sr)
我们在歌曲合唱中切成20秒的片段。我们使用ipd.Audio (tbh,这有点疲惫)显示音频。照片如下所示,因为我找不到在此处上传音频的方法。

我们将复杂值的频谱图D分为其大小(S)和相(P)组件,将时间戳转换为帧,绘制数据,然后显示数据的完整光谱图
S_full, phase = librosa.magphase(librosa.stft(y))
idx = slice(*librosa.time_to_frames([90*110], sr=sr))
fig, ax = plt.pyplot.subplots()
img = display.specshow(librosa.amplitude_to_db(S_full[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax)
fig.colorbar(img, ax=ax)
划线说明
S_full, phase = librosa.magphase(librosa.stft(y))-我们通过计算离散的傅立叶变换(DFT)(y)在时频域中代表信号,使用短时傅立叶变换使用短时傅立叶变换(y)(y)(y)(y)(y)(y)(y)(y)(y) )
idx = slice(*librosa.time_to_frames([90*110], sr=sr))-切片a歌曲的一部分,然后使用librosa的 time_to_frames 函数将其转换为stft帧
img = display.specshow(librosa.amplitude_to_db(S_full[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax)-通过将幅度频谱图转换为幅度的DB尺度频谱图,显示歌曲20秒切片部分的光谱图,然后比较轨道的幅度和相位,并返回包含元素的新数组 - 明智的最大值然后绘制 y 和 x axis
下面是频谱的图像:
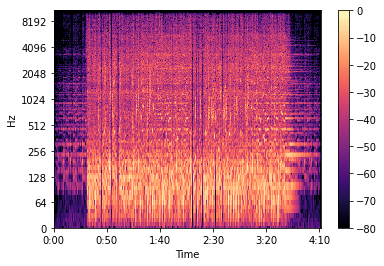
分解频谱图
S_filter = librosa.decompose.nn_filter(S_full, aggregate=np.median, metric='cosine', width=int(librosa.time_to_frames(2, sr=sr)))
S_filter = np.minimum(S_full, S_filter)
划线说明
S_filter = librosa.decompose.nn_filter(S_full, aggregate=np.median, metric='cosine', width=int(librosa.time_to_frames(2, sr=sr)))-我们通过其最近的邻居过滤人声,汇总其中位数,使用余弦相似性比较其框架,并包含这些帧要分开2秒,并抑制了Spectrum
S_filter = np.minimum(S_full, S_filter)-我们在S_full和S_filter变量的内存中获取计算的数据以获取最小值。
显示音频的背景和前景频谱
margin_i, margin_v = 3, 11
power = 3
mask_i = librosa.util.softmask(S_filter, margin_i * (S_full - S_filter), power=power)
mask_v = librosa.util.softmask(S_full - S_filter, margin_v * S_filter, power=power)
S_foreground = mask_v * S_full
S_background = mask_i * S_full
划线说明
margin_i, margin_v = 3, 11-我们使用边距减少声音和仪器面具中的声音损失
power = 3-返回以数值稳定方式计算的软面膜
S_foreground = mask_v * S_full和S_background = mask_i * S_full-用输入频谱将蒙版乘以分离组件
绘制全光谱,背景和前景频谱
fig, ax = plt.pyplot.subplots(nrows=3, sharex=True, sharey=True)
img = display.specshow(librosa.amplitude_to_db(S_full[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax[0])
ax[0].set(title='Full Spectrum')
ax[0].label_outer()
display.specshow(librosa.amplitude_to_db(S_background[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax[1])
ax[1].set(title='Background Spectrum')
ax[1].label_outer()
display.specshow(librosa.amplitude_to_db(S_foreground[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax[2])
ax[2].set(title='Foreground Spectrum')
ax[2].label_outer()
fig.colorbar(img, ax=ax)

从蒙版频谱图中恢复前景音频并播放音频
y_foreground = librosa.istft(S_foreground * phase)
ipd.Audio(data=y_foreground[90*sr:110*sr], rate=sr)
划线说明
y_foreground = librosa.istft(S_foreground * phase)-逆向短时傅立叶变换
ipd.Audio(data=y_foreground[90*sr:110*sr], rate=sr)-播放曲目的人声
结论
这似乎一开始很容易,当我阅读文档时,但是根据代码进行挖掘使我意识到这个想法更加复杂。但是,让我继续的是,当我在文档的一个部分中阅读最近的邻居,这使我意识到我将来将在此图书馆中获得机器学习。
