nodejs是快速设置HTTP服务器(例如HTTP服务器)的绝佳工具,这要归功于它与其他库(如SSR)的网络框架和NOSQL数据库(如MongoDB)的集成。
。但是,由于其解释的性质,JavaScript并不是记忆密集型任务的正确工具。诸如Golang(例如Golang)的其他编译语言在某些任务中获得了优化,因为它们已针对它们进行了优化。如果我们能在两全其美的情况下,这将是很棒的,不是吗?输入 WebAssembly 。
简短免责声明
本文中解释的示例 - 大多数特定特定特定的库在此时间点 - 基于一些实验库,这些库会在将来发生变化。这并不意味着您不能在生产中使用它们,但是您应该意识到,这些库的API不能保证在将来的发行版中向后兼容,并且在更新GO或NODEJS的版本时可能需要额外的重构工作。
一些背景
JavaScript是一种解释的语言。这意味着,由于其动态键入性质,应用程序无法在运行时使用哪种类型的数据进行假设:传递给函数的变量可能是字符串,对象甚至函数。
虽然动态键入为开发人员提供了很大的灵活性,但执行代码的解释器无法提前优化代码。这就是为什么像浏览器中使用的JavaScript引擎执行 just-time(jit)优化的原因。
JIT本质上是对代码及其使用的特定类型的缓存策略。由于对代码的解释和执行,JIT编译器将跟踪代码中使用的类型,将其转换为字节码(低级别指令),并使用此代码下次调用该代码的优化版本。
虽然JIT执行许多其他特定的改进,但总的来说,这是其目标:将JavaScript代码编译为优化的说明。多亏了JIT汇编,像浏览器这样的引擎可以在几乎本机代码速度(几乎)上执行解释的代码。这是编译语言(如GO)的优势:它们的强烈键入性质(除其他特定语言的特征外)允许编译器提前执行所有优化,从而导致应用程序只需要执行字节。
。WebAssembly
WebAssembly(WASM)是一项规范,它允许我们编写可以提前完全编译和优化的代码,并在通常使用浏览器或服务器端解释的引擎中使用的环境中使用编译的代码。
WASM功能
- 快速。 WASM编译的代码几乎与本质上编译的应用程序一样快。这使我们能够运行内存密集型应用程序,这些应用程序通常不可能在浏览器或IoT设备等低资源客户端中运行。
- 安全。 WASM模块只能访问一组线性内存,并从该应用程序的其余部分进行沙盒。这降低了有恶意代码访问数据或资源不应该的风险。
- 便携式。 WASM用作容器(或VM),它允许其编译可以在多个架构中运行的字节码:浏览器,移动设备和后端服务器;只要它支持WASM规范,它就可以执行WASM代码。
- 灵活。 WASM本身是一个汇编目标。这意味着,您可能可以使用任何编程语言编写代码,并生成几乎可以在任何地方运行的字节码。
WASM限制
相同的隔离和灵活性提供了大多数WASM的优势是其大多数局限性的原因:
- WASM不提供默认的内存管理(例如垃圾收集)机制。这意味着,目前,每个WASM模块都需要使用其内存管理代码运输。 (这是Rust shines for WASM modules(作为内存管理的语言))) 的原因之一
- WASM模块与应用程序的其余部分之间的通信需要以非常简单的类型(字节,INT和Floats)进行。不支持复杂的类型 。这就是为什么大多数WASM编译器还提供一些 GLUE 编码来对复杂类型(如字符串或数组)之间的映射。 Web Assembly System Interface (WAS)是一个旨在解决最后限制的前进标准。成熟后,几乎可以轻松地与几乎每个环境进行互操作。 WASI已经在某些WSAM编译器和运行时间中可用。
用例:日志尾巴
大多数WASM示例都是简单的“ Hello World”。对于这篇文章,我认为看到一个更具体的用例很有用,这是我过去发现的问题。
想象您有一个已部署的应用程序,该应用程序正在将输出记录到文本文件中。我们想将本文件中的每一行实时解析,并将其写入其,并将其发送到以进行解析,显示和/或存储的地方。像Logstash这样的现有工具已经提供了此功能,但是我们想自己写一些东西,使我们可以控制解析过程。
首先,让我们创建一个名为logger.js的简单nodejs脚本,以模拟该日志文件的创建:
const fs = require('fs')
const util = require('util')
var logFile = fs.createWriteStream('test.log', { flags: 'a' })
function log() {
// console.log(...arguments);
logFile.write(util.format.apply(null, arguments) + '\n')
}
function randomElement(arr) {
return arr[Math.floor(Math.random() * arr.length)]
}
function randomTime() {
const time = [1000, 100, 3000, 0]
return randomElement(time)
}
function randomLevel() {
const levels = ['WARN', 'INFO', 'ERROR']
return randomElement(levels)
}
let i = 0
function startLogger() {
log(`${randomLevel()} Log number ${i++}`)
setTimeout(() => {
startLogger()
}, randomTime())
}
startLogger()
首先,我们使用fs.createWriteStream创建一个NodeJS ReadStream,以“附加”模式打开test.log文件。然后,我们开始使用setTimeout递归循环。这模拟了以可变速率在文件中登录文本的应用程序。在每次迭代中:
- 我们打印一些从
{'WARN', 'INFO', 'ERROR'}到日志文件的随机日志级别的简单文本。 - 我们从
{1000, 100, 3000, 0}随机选择毫秒的数量来等待下一个迭代。
在GO中读取日志文件
我们将在Go中写下我们的模块。 GO提供本机WASM编译,而无需安装其他库或编译器。
启用复杂类型的输出
正如我之前提到的,WASM模块无法输出复杂的类型,因此,如果我们希望能够发送数字或字节以外的其他内容,我们需要一些“胶水”代码,这些代码将诸如字符串和slices之类的映射类型处理为字节。 GO存储库提供了非常方便的koude6,它将允许我们的WASM模块与外界通信。
wasm_exec.js脚本有一些局限性:
- 它是在浏览器上使用的。我们可以通过对脚本进行一些小的更改来使其与Nodej兼容,从而解决这一事实。我们将在下一篇文章中定义这些更改。
- 它不支持自定义数据结构。这是有道理的,因为我们的WASM模块必须导出某种模式,因此无论谁消耗模块的人都知道如何解析输出。但是,
wasm_exect.js确实支持切片和地图,这使我们能够将我们的GO定义结构填充到map[string]interface{}之类的对象中。
我们当前的示例与其他更简单的示例不同,因为我们不仅会从WASM模块中输出单个结果。我们希望能够将解析的日志发送回nodejs,并将其附加到日志文件中。
我们可以使用polling反复调用WASM模块检索最新日志,但这不是一种最佳方法,因为它需要微调即可实时获取日志而无需过多的内存消耗。
>一种更好的方法是使用回调:我们在nodejs中定义了一个函数,每次解析新日志并准备消耗新日志时都可以从WASM模块调用。
GO代码
首先,我们创建一个新的GO模块:
go mod init wasm-test.com
在创建go.mod文件的同一文件夹中,我们创建wasm.go。
首先,我们将定义输出的类型。为了方便起见,我们将创建一种名为ParsedLogs的新类型,这只是map[string]interface{}的别名。
type ParsedLogs = map[string]interface{}
现在,让我们定义一个只有一个责任的函数:将输出发送回NODEJS。但是,由于我们想测试一切都在不需要编译和部署模块的情况下工作,因此,目前,我们的回调只会将解析的日志打印到控制台中:
func ModuleOutput(parsedLogs ParsedLogs) {
fmt.Println(parsedLogs)
}
type OutputCallback = func(parsedLogs ParsedLogs)
OutputCallback是我们仅出于方便而创建的另一个别名,因此当我们将函数作为参数传递给主过程时,我们不必使用冗长的func(parsedLogs ParsedLogs)。
现在,我们定义了两个函数:main,这是模块的切入点,而Execute将包含实际的日志解析逻辑:
func Execute(callbackFn OutputCallback) {
//... call callbackFn to send parsed logs
}
func main() {
Execute(ModuleOutput)
}
读取日志文件
是时候扩展Execute功能来读取我们的日志文件了。在此示例中,我们将对日志文件进行硬编码,但是您可以将其作为参数传递,或从a global function defined in NodeJS中检索。
func Execute(callbackFn OutputCallback) {
file, err := os.Open("./test.log")
if err != nil {
log.Fatal(err)
}
defer file.Close()
acc := NewAccumulator()
defer close(acc.out)
go func() {
for {
select {
case str := <-acc.out:
l := parse(str)
callbackFn(l.ToMap())
case <-time.After(2 * time.Second):
acc.Flush()
}
}
}()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
if err == io.EOF {
time.Sleep(500 * time.Millisecond)
continue
}
log.Fatal(err)
}
acc.Append(line)
}
}
这里有很多事情发生,所以让我们分解。
首先,我们打开日志文件,确保我们推迟其close函数:
file, err := os.Open("./test.log")
if err != nil {
log.Fatal(err)
}
defer file.Close()
然后,我们创建一个Accumulator -a尚未定义的结构的实例,但是将在打印时照顾汇总日志 - :
acc := NewAccumulator()
defer close(acc.out)
现在,代码的其余部分并行执行两件事:
- 在循环中,它一次读取日志文件,一次将其发送到
Accumulator。 - 在另一个循环中,它检查了
Accumulator的内容,如果已处理已处理的日志,它将以分析日志为参数调用输出回调。
违反直觉,可以在功能末尾看到第一个循环:
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
if err == io.EOF {
time.Sleep(500 * time.Millisecond)
continue
}
log.Fatal(err)
}
acc.Append(line)
}
我们创建一个文件读取器,在无限循环中,我们一次读取文件一行。如果文件读取器到达文件的末尾(当ReadString返回io.EOF作为错误时发生),我们只需暂停该过程半秒,然后再次检查文件是否具有新的日志条目。对time.Sleep的呼叫至关重要,否则,该循环将在全速度下执行,消耗比所需的更多内存。
当读者输出新行时,我们只将其添加到Accumulator。
我们在goroutine内执行第二个循环,这将使我们能够并行运行另一个无限循环。
go func() {
for {
select {
case str := <-acc.out:
l := parse(str)
callbackFn(l.ToMap())
case <-time.After(2 * time.Second):
acc.Flush()
}
}
}()
在此循环中,我们检查了Accumulator的属性out,这是一个GO通道。如果频道有一个新的日志条目,我们将使用parse函数进行处理 - 我们将定义下一步,然后将处理的结果发送到输出回调。
我们将解释select块中的第二个case在以下部分中所做的事情。
累加器
要注意的一件事是,某些日志条目不适合一行。如果我们试图隔离文本文件中的每一行,我们将无法解析其中的一些行,因为它们是上一行的延续。为了解决这一挑战,我们将每行累积到strings.Builder的实例中。
我们看到独立日志条目包含一个日志级别,例如WARN或ERROR。这有助于我们确定一行是新日志条目的开始还是上一行的一部分。
Accumulator结构基本上是围绕strings.Builder的包装器:
var r, _ = regexp.Compile("(WARN|ERROR|INFO) (.+)")
type Accumulator struct {
sb strings.Builder
out chan string
}
func NewAccumulator() Accumulator {
return Accumulator{sb: strings.Builder{}, out: make(chan string, 10)}
}
func (a *Accumulator) Append(str string) {
if r.MatchString(str) {
a.Flush()
}
a.sb.WriteString(str)
}
func (a *Accumulator) Flush() {
if a.sb.Len() > 0 {
res := a.sb.String()
go func(res string) {
a.out <- res
}(res)
a.sb = strings.Builder{}
}
}
我们使用Append函数为Accumulator添加了一条新行。在此功能中,我们检查日志是否包含ERROR,WARN或INFO的单词;如果它们不匹配,我们将它们附加到字符串构建器上。但是,如果它们匹配,我们将调用Flush函数。
Flush函数检查字符串构建器是否为空。如果不是这样,它将将其转换为字符串,并将其发送到out GO通道。然后,它通过创建一个新实例来清除字符串构建器,从而使其准备从日志文件开始接收新行。
现在,请记住,我们还在无限循环中调用Accumulator.Flush,该循环读取out频道的输出:
select {
case str := <-acc.out:
l := parse(str)
callbackFn(l.ToMap())
case <-time.After(2 * time.Second):
acc.Flush()
}
这是因为累加器本身仅在收到新的文本行时调用Flush。如果我们仅在Append中调用Flush,则Accumulator将等待输出最新的日志条目,直到日志文件具有新内容为止,这将导致始终缺少输出的最后一个条目。
例如,如果我们的日志文件仅包含以下行:
WARN - Hello
,然后添加了第二行:
WARN - Hello
ERROR - Something awful happened!
当第二行附加时,第一行将发送到nodejs。但是第二行本身将保留在Accumulator内。如果该过程停止完全发送日志,则NODEJS代码将永远不会看到第二行。
但是,由于我们的代码未接收新的日志后每2秒钟调用Flush,因此将处理第二个条目并将其发送回NODEJS。
解析日志
用于解析日志的代码非常简单。它解决了我们示例中日志条目的简单格式,但是您可以轻松地将其扩展到更复杂的模式:
我们创建了一个简单的Log结构,该结构具有函数ToMap,它返回了ParsedLogs的实例 - 我们以前为map[string]interface{}-。
type Log struct {
Level string
Msg string
}
func (l Log) ToMap() ParsedLogs {
m := make(map[string]interface{})
m["level"] = l.Level
m["msg"] = l.Msg
return m
}
然后,我们最终定义了我们在goroutine中调用的parse函数。此功能使用正则函数从条目和随后的文本中解析日志级别。它创建了一个Log的实例,并用从正则分析的值填充其属性。
func parse(str string) Log {
log := Log{}
if !r.MatchString(str) {
log.Msg = str
return log
}
groups := r.FindStringSubmatch(str)
log.Level = groups[1]
log.Msg = groups[2]
return log
}
从技术上讲,我们不需要定义一个新的结构,因为我们可以轻松地直接输出map[string]interface{}。但是,如果我们需要执行额外的解析逻辑,则额外的抽象为我们提供了占位符。
现在,我们可以通过运行logger.js和wasm.go并行测试代码工作:
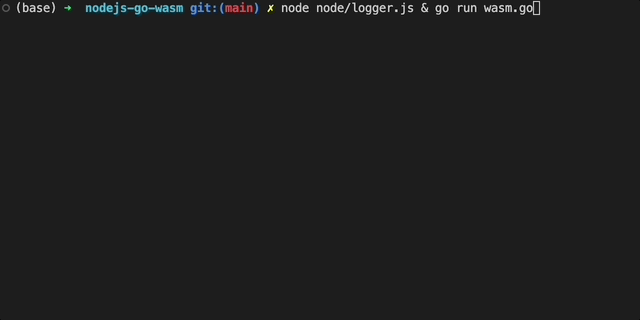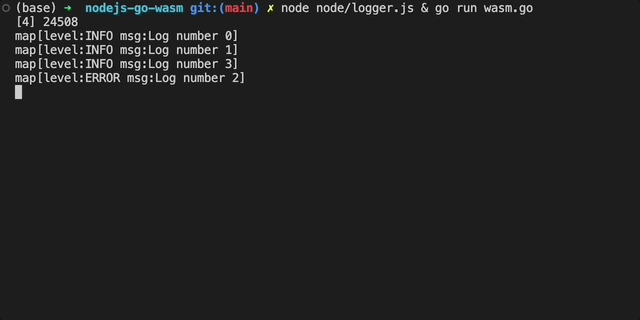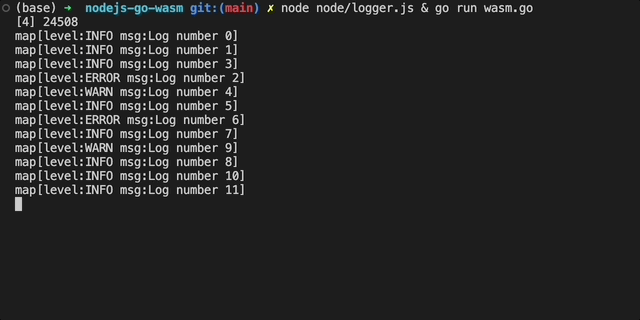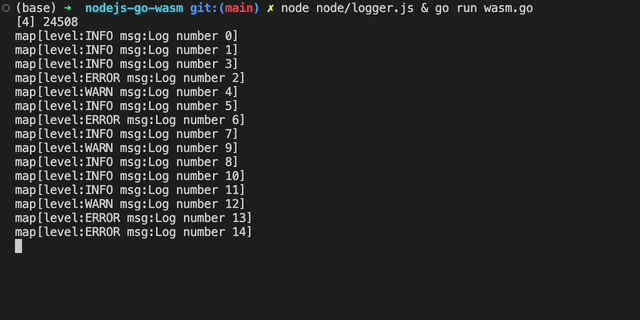
现在该更新我们的GO代码以作为WASM模块进行编译。
SYSCALL/JS模块
我们将导入GO模块"syscall/js",该文档在其文档中定义如下:
软件包JS使用JS/WASM架构时可以访问WebAssembly主机环境。它的API基于JavaScript语义。
该包装是实验性的。它的当前范围仅允许测试运行,但尚未为用户提供全面的API。它免于兼容承诺。
本质上,此库允许我们与将执行我们的WASM模块的Nodejs代码进行通信。
从syscall/js中,我们可以从nodejs内部获得 global 变量的引用。然后,我们可以在这样的nodej中定义一个函数:
globalThis.logCallback = () => {
/* ... */
}
然后,在我们的GO代码中,我们可以获取该功能的引用如下:
func ModuleOutput(parsedLogs ParsedLogs) {
logCallback := js.Global().Get("logCallback")
logCallback.Invoke(parsedLogs)
}
您会注意到的一件事是,syscall/js仅适用于WASM架构。如果我们现在尝试使用go run运行GO模块,我们将看到以下错误消息:
package command-line-arguments
imports syscall/js: build constraints exclude all Go files in /usr/local/go/src/syscall/js
我们一旦导入syscall/js,编译器就可以约束该模块的架构类型。
这就是为什么我们没有直接在Execute中调用js.Global()的原因;它使大多数代码与WASM特定依赖关系取消,这使它们更易于在非WASM应用中重复使用。
如果我们要立即执行代码,我们将必须将其编译为WebAssmebly字节码;可以使用以下命令来完成:
GOOS=js GOARCH=wasm go build -o app.wasm
通过将GOARCH环境变量设置为wasm,该模块现在将成功编译。此外,GOOS=js环境变量让编译器知道我们将在JavaScript中使用此WASM模块。
如果go build命令成功完成,则应在根文件夹中看到一个名为app.wasm的新文件。这是我们将在nodejs中导入的WASM模块。
在下一篇博客文章中,我们将探讨此过程的第二部分:将编译的WASM模块导入nodejs应用程序中。
结论
使用Nodejs和Golang的当前功能,现在可以使用WebAssembly作为创建几乎和本机代码执行的代码模块的一种方式,并且启用了历史上在存储器和执行方面一直在历史上均无历史的功能诸如JavaScript之类的解释语言的时间。
我们已经看到Golang为WASM提供了汇编支持。在此示例中,我们使用了本机GO功能,例如GO频道和Goroutines,这表明这些功能可以在WebAssembly的背景下运行良好。
在我们结束之前要注意的一件事是,在nodejs中执行wasm-更常见的浏览器,例如更常见的示例,使我们可以访问诸如fs之类的主机特定库来读取文件和内存运行时。所有这些内容在浏览器的JavaScript引擎中均未直接可用,这意味着我们在此示例中创建的WASM模块不会在此处运行。
但是,还有其他更多的充实的图书馆,例如koude75,它提供了运行时,并帮助我们围绕这些限制进行导航。 koude75 documentation提供了这些挑战的很好总结:
主要问题是,尽管GO编译器支持WebAssembly,但它不支持WASI(WebAssembly System接口)。它生成一个与JavaScript绑定的ABI,并且需要使用GO ToolChain提供的WASM_EXEC.JS文件,该文件在JavaScript主机之外不起作用。
然后,重要的是要指出我们的示例仅在nodejs中起作用。编译的WASM模块不能在其他支持WASM的环境中使用。无论如何,我们可以使用相同的代码并使用wasmer-go或koude78等工具,并且可以解决此限制。
WebAssembly作为模块化可互操作代码的标准有希望的未来。我们可以预期,规范(尤其是WASI)将来的改进将为使用WASM创建可嵌入功能的容器打开大门。