csv(逗号分隔值)可以将其视为数据库,并且以表格式存储数据。据我所知,CSV无处不在。从报告到机器学习到存储数据集及其他。
相信与否,大多数公司仍然使用CSV作为“ DB”。然后,当我们谈论数据并且您是一位热情的数据分析师时,我们必须使用SQL(在BI工具中)进行分析,因此,如果您在AWS环境中工作,请遵循此步骤。

1-准备CSV文件
如果您在本地上已经有CSV文件,请跳过。
- 因为我们将使用Python,请在您的本地安装python
- 安装 faker 库获取虚拟数据
- 用
'first_name', 'last_name', 'age'作为标头准备CSV - 现在,打开文件夹,应该在其中创建
dummy-data.csv
import csv
from faker import Faker
fake = Faker()
number_of_records = 8000
with open('dummy-data.csv', mode='w+') as file:
file_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
file_writer.writerow(['first_name', 'last_name', 'age'])
for _ in range(number_of_records):
file_writer.writerow([fake.first_name(), fake.last_name(), fake.numerify("@#")])
2-在Amazon S3中创建一个水桶
如果您已经有一个水桶并使用现有的
,请跳过- 转到AWS Console-> search
S3->单击Create Bucket - 填写必要字段 - >创建存储桶

- 创建了新的存储桶。现在,您可以决定是否在存储桶内创建一个新文件夹。对我来说,我想拥有一个单独的文件夹以用于虚拟数据;因此,我创建了
dummy_data文件夹 - 单击
Create folder
- 填写必要字段 - >创建文件夹
- 在存储桶中创建了新文件夹
- 现在,将.csv文件拖动到页面上
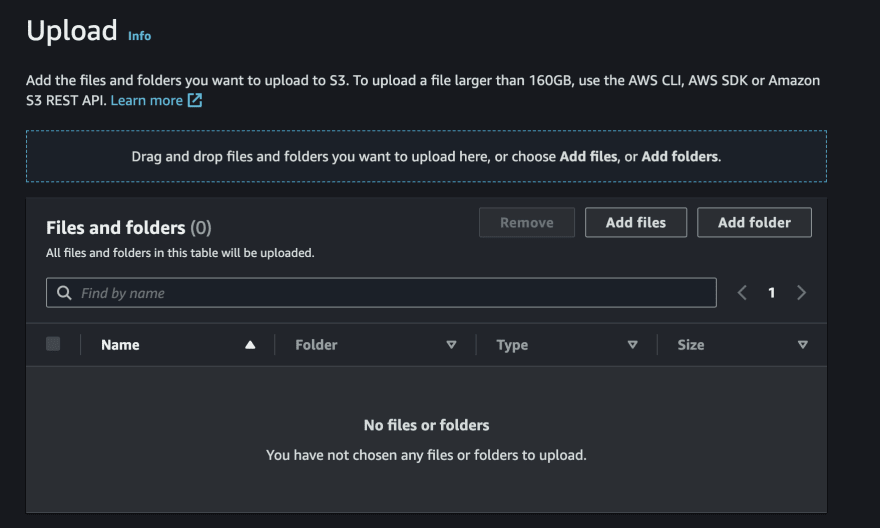
- 您可以刷新或返回到遗愿文件夹以查看导入的CSV文件

- 请不要忘记复制文件夹的S3 URI创建雅典娜表
3-在AWS Athena中创建桌子
- 在雅典娜创建桌子;您需要定义表的结构,以便雅典娜表能够知道CSV文件中的数据结构。
- AWS管理控制台
- aws cli
- 在这篇文章中,我正在使用AWS管理控制台。像S3服务一样,您可以打开AWS控制台并搜索雅典娜。
- 使用以下查询填充表
CREATE EXTERNAL TABLE dummy_person (
first_name string,
last_name string,
age string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '"',
'escapeChar' = '\\'
)
LOCATION '[S3 URI]'
TBLPROPERTIES ("skip.header.line.count"="1");
创建表。

运行SQL查询以检查数据已填充
select * from dummy_person
此刻,您已经可以看到数据

接下来,您可以将雅典娜连接到BI工具,并开始开发仪表板ð