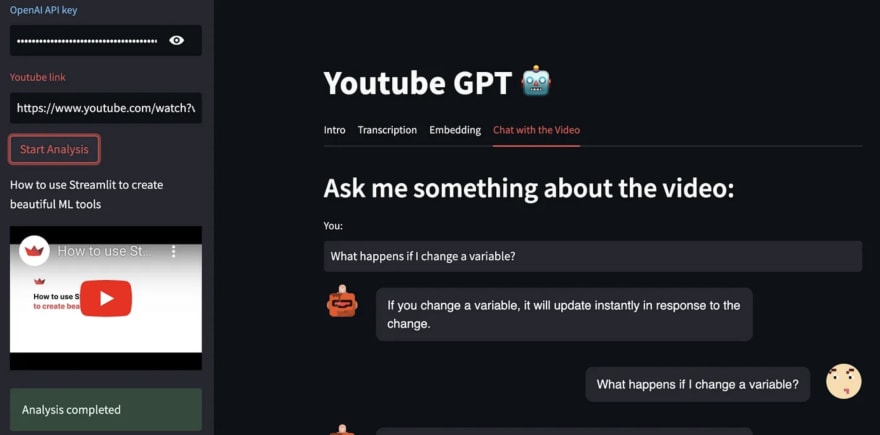
使用YouTube GPT,您可以通过粘贴视频链接来从YouTube上的视频中提取所有信息。
您将获得转录,每个细分市场的嵌入,并通过聊天向视频提出问题。
所有代码都是在Code GPT
的帮助下编写的
特征
- openai hisper 的视频转录
- 用OpenAI API嵌入成绩单( text-embedding-ada-002 )
- 使用 spartlit-chat与视频聊天
例子
在此示例中,我们将使用Pycoach的此视频
https://youtu.be/lKO3qDLCAnk
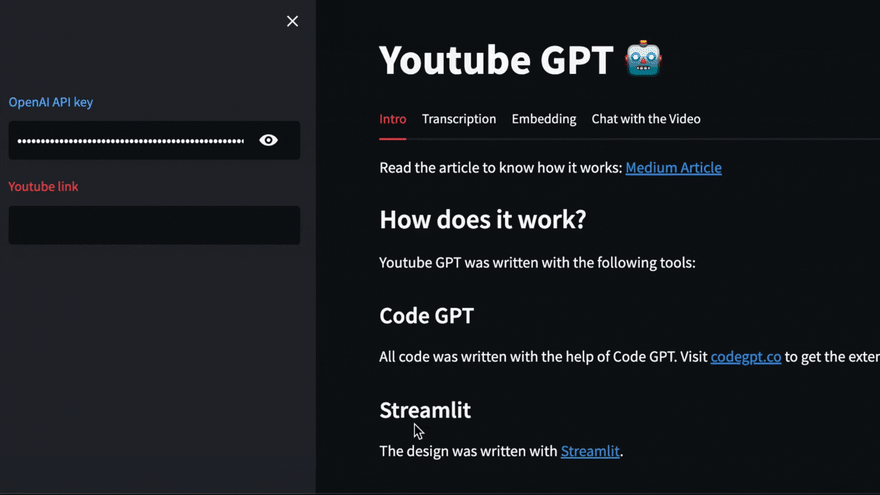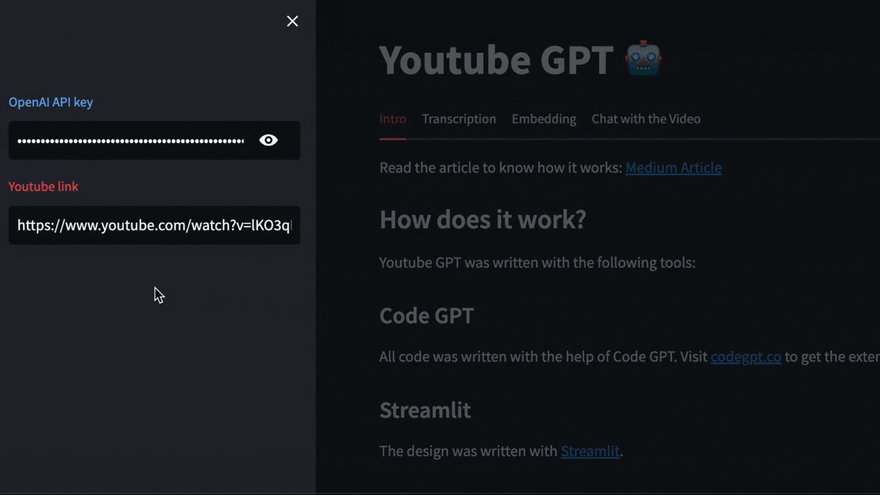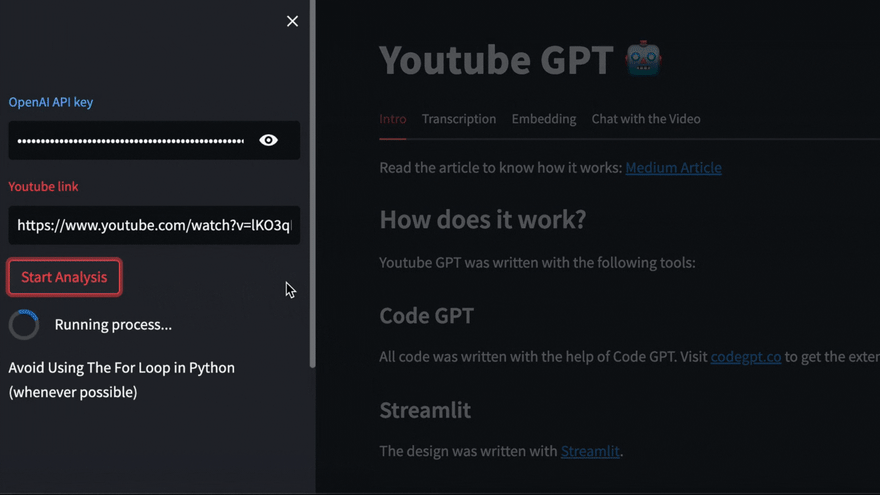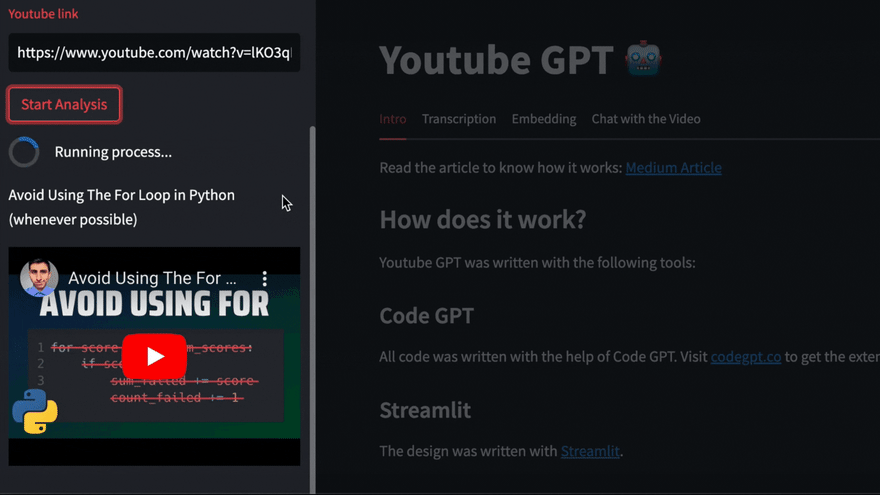
添加视频URL,然后单击“开始分析”
Pytube和Openai Whisper
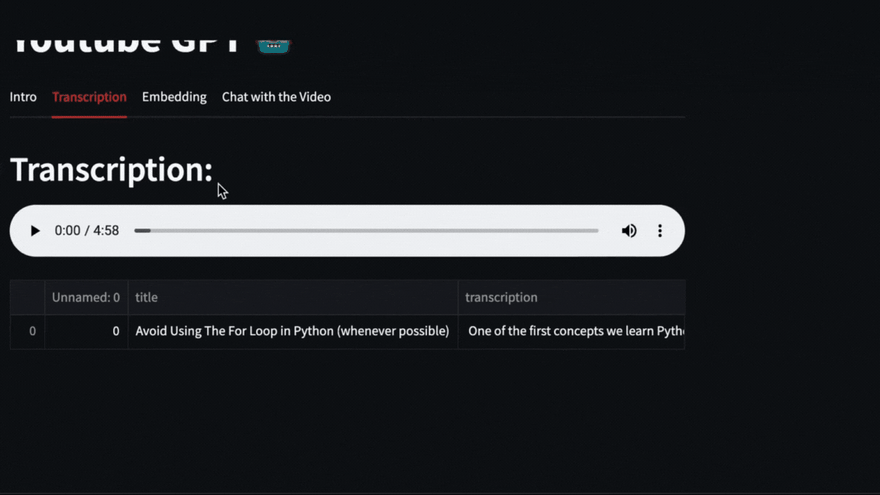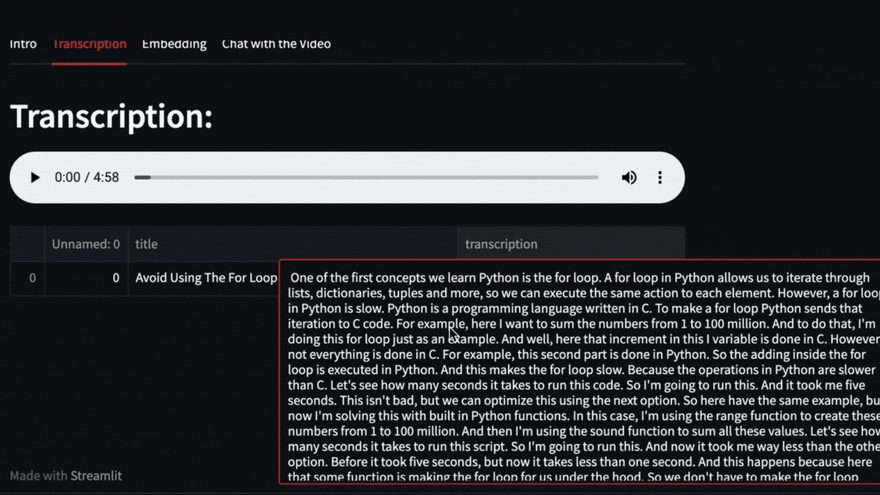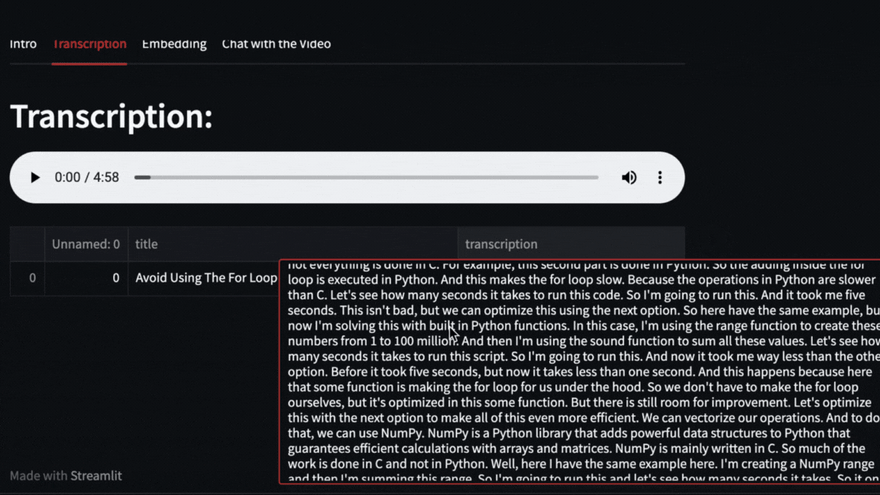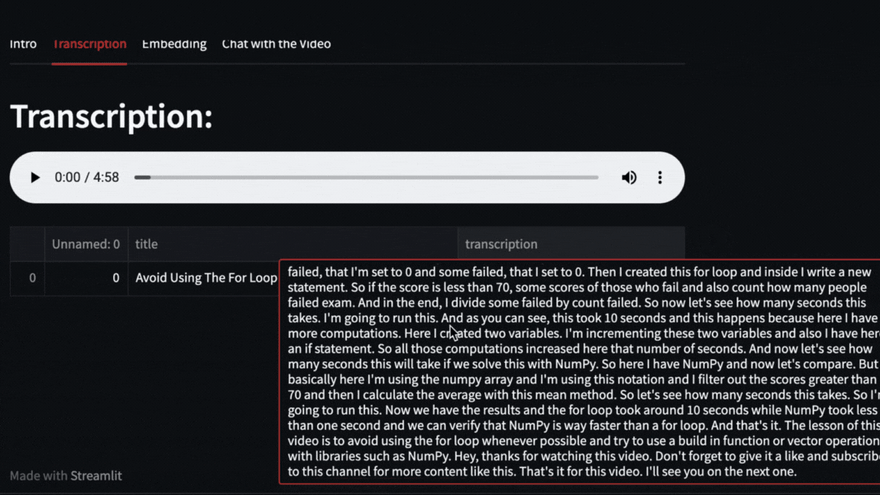
该视频将使用Pytube下载,然后Openai Whisper将负责转录和细分视频。
# Get the video
youtube_video = YouTube(youtube_link)
streams = youtube_video.streams.filter(only_audio=True)
mp4_video = stream.download(filename='youtube_video.mp4')
audio_file = open(mp4_video, 'rb')
# whisper load base model
model = whisper.load_model('base')
# Whisper transcription
output = model.transcribe("youtube_video.mp4")
嵌入“ text-embedding-ada-002”
我们获得了 text-embedding-ada-002的向量

# Embeddings
segments = output['segments']
for segment in segments:
openai.api_key = user_secret
response = openai.Embedding.create(
input= segment["text"].strip(),
model="text-embedding-ada-002"
)
embeddings = response['data'][0]['embedding']
meta = {
"text": segment["text"].strip(),
"start": segment['start'],
"end": segment['end'],
"embedding": embeddings
}
data.append(meta)
pd.DataFrame(data).to_csv('word_embeddings.csv')
Openai GPT-3
我们对矢量化文本提出了一个问题,我们对上下文进行搜索,然后将上下文的提示发送到模型“ text-davinci-003”

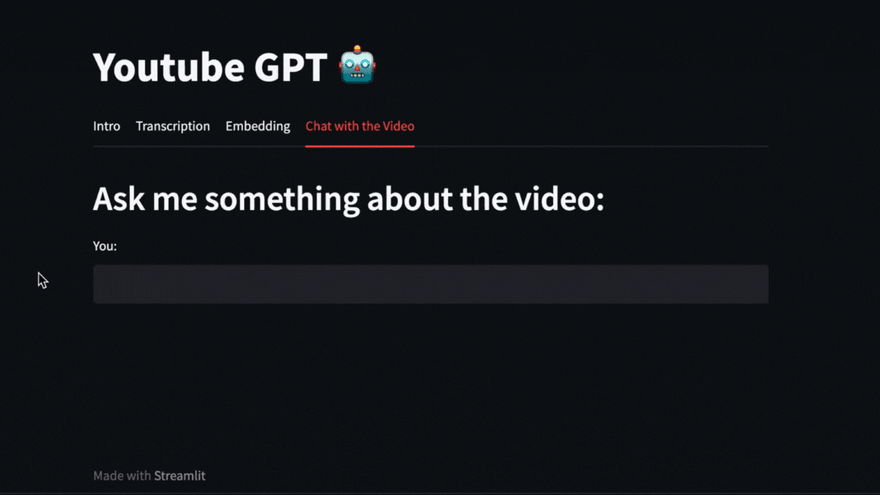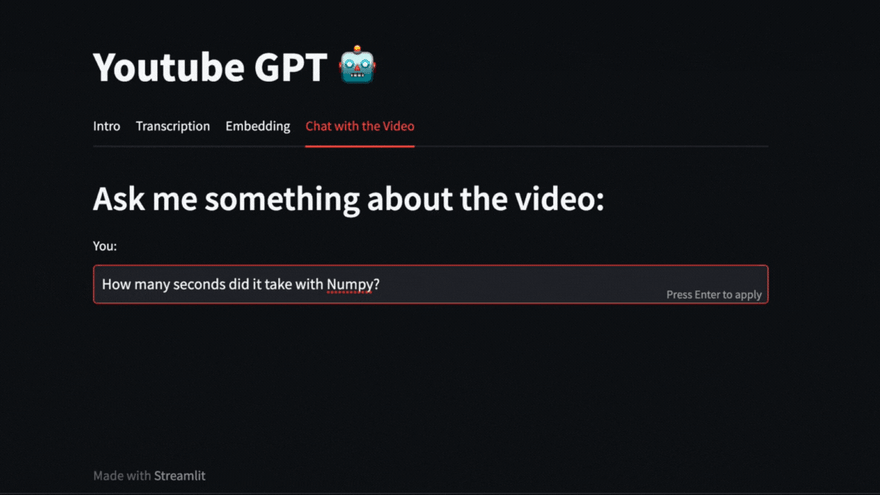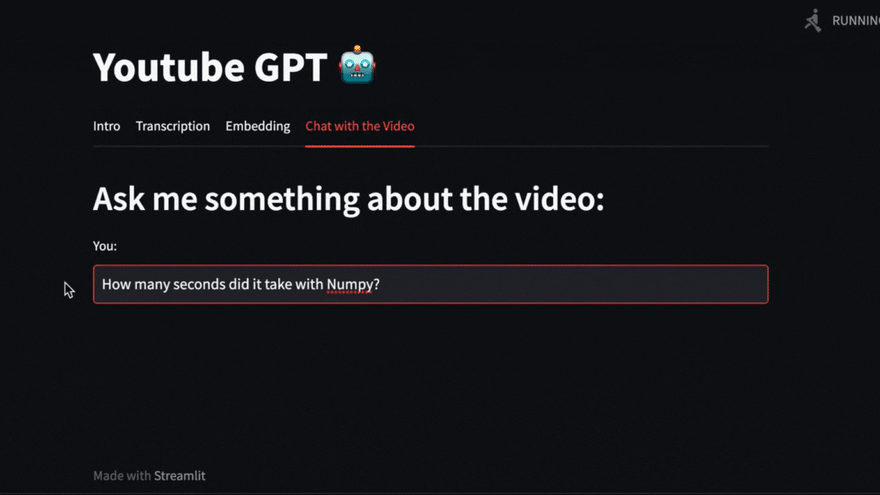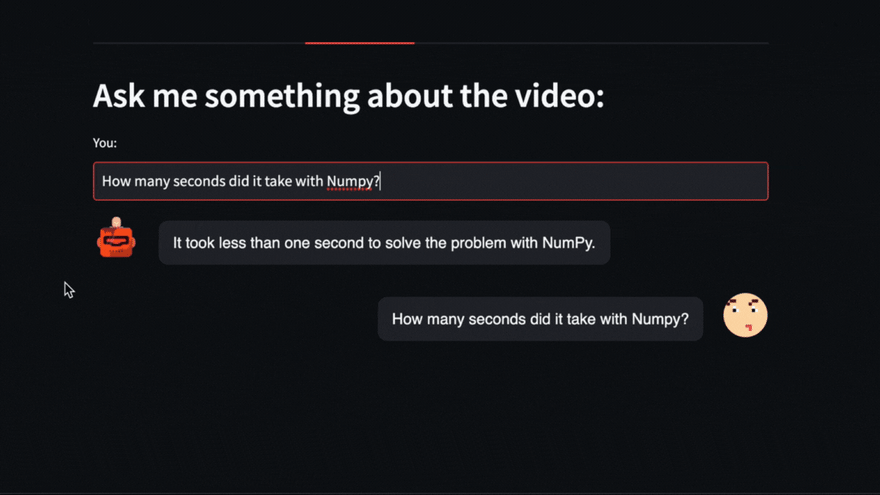
我们甚至可以提出有关视频中发生的事情的直接问题。例如,我们在这里询问Pycoach在视频中所做的Numpy进行了多长时间。
本地运行
github:https://github.com/davila7/youtube-gpt
- 克隆存储库
git clone https://github.com/davila7/youtube-gpt
cd youtube-gpt
- 安装依赖项
这些依赖项必须与要求一起安装.txt文件:
- 简化
- stramlit_chat
- matplotlib
- Plotly
- Scipy
- sclearn
- 熊猫
- numpy
- git+https://github.com/openai/whisper.git
- Pytube
- openai-whisper
pip install -r requirements.txt
- 运行精简服务器
streamlit run app.py
即将到来的功能ð
- 嵌入式语义搜索
- 带有情感分析的图表
- 与Pinecone连接