介绍
每个开发人员在职业生涯的某个时候都使用网络刮擦作为必要的工具。因此,开发人员必须了解网络刮刀以及如何创建它们。
在此博客中,我们将使用Fiber和Colly Frameworks涵盖WEB刮擦的基础知识。 Colly是一个用GO编写的开源网络刮擦框架。它提供了一种简单而灵活的API,用于执行Web刮擦任务,使其成为GO开发人员的流行选择。 Colly使用GO的并发功能有效处理多个请求并从网站上提取数据。它提供了广泛的自定义选项,包括设置请求标题,处理cookie,关注重定向的能力,以及更多
我们将以一个简单的示例从网站提取数据,然后转到更高级的主题,例如自定义刮擦过程和设置请求标头。在此博客结束时,您将对如何使用GO构建网络刮板并能够从任何网站提取数据有深入的了解。
先决条件
要继续进行教程,首先您需要安装Golang和光纤。
安装:
入门
让我们通过使用以下命令创建主要项目目录Go-Scraper开始。
(ð¥请小心,有时我通过在代码中发表评论来完成解释)
mkdir Go-Scraper //Creates a 'Go-Scraper' directory
cd Go-Scraper //Change directory to 'Go-Scraper'
现在初始化一个mod文件。 (如果您发布模块,则必须是通过GO Tools下载模块的路径。这将是您的代码存储库。)
go mod init github.com/<username>/Go-Scraper
安装光纤框架运行以下命令:
go get -u github.com/gofiber/fiber/v2
安装Colly Framework运行以下命令:
go get -u github.com/gocolly/colly/...
现在,让我们制作要实现刮擦过程的main.go。
在main.go文件中,第一步是使用fiber.New()方法初始化新的光纤应用程序。这将创建一个将处理HTTP请求和响应的光纤框架的新实例。
接下来,我们通过调用app.Get("/scrape", ...)方法来定义Web刮板的新端点。这将在/scrape路线上创建一个新的GET端点,该路由将用于触发Web刮擦过程。
package main
import (
"fmt"
"github.com/gofiber/fiber/v2"
)
func main() {
app := fiber.New() // Creating a new instance of Fiber.
app.Get("/scrape", func(c *fiber.Ctx) error {
return c.SendString("Go Web Scraper")
})
app.Listen(":8080")
}
运行go运行main.go命令后,终端将看起来像这样,

让我们使用colly.NewCollector()方法创建一个Colly Collector的新实例。收藏家负责访问网站,提取数据并存储结果。
collector := colly.NewCollector(
colly.AllowedDomains("j2store.net"),
)
collector.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
Colly Framework中的colly.AllowedDomains属性用于限制允许Web刮板访问的域。该属性用于防止刮板访问不需要的网站。对于此博客,我们将使用包含示例数据的this网站,并且域是j2store.net。
可以通过多种方式配置Colly Collector来自定义Web刮擦过程。在这种情况下,我们使用collector.OnRequest(...)方法定义了请求处理程序。每次向网站提出请求时,该处理程序都会被称为该处理程序,并且只需记录访问的URL。
现在,要从网站提取数据,我们将使用collector.OnHTML(...)方法为特定的HTML元素定义处理程序。
这是网站上的示例数据的外观,

这是一些产品图像,其名称和价格。我们只是在提取他们的名字,图像URL和价格。
因此,让我们创建一个包含这三个字段的结构项目,即名称,价格,图像URL。数据类型定义为字符串。当我们将返回JSON中的所有数据时,添加了JSON字段。
type item struct {
Name string `json:"name"`
Price string `json:"price"`
ImgUrl string `json:"imgurl"`
}
现在,让我们在OnHTML()回调上工作。
collector.OnHTML("div.col-sm-9 div[itemprop=itemListElement] ", func(h *colly.HTMLElement) {
item := item{
Name: h.ChildText("h2.product-title"),
Price: h.ChildText("div.sale-price"),
ImgUrl: h.ChildAttr("img", "src"),
}
items = append(items, item)
})
在此,在onhtml()函数中,首先,我们添加了一些内部引号,这些内容是父元素,它是一个CSS选择器,在此div标签中,添加了所有产品。您可以通过检查元素在页面上看到它,并像我在下图中所做的那样悬停在产品上。这意味着每当此父元素到来时,都必须调用此onHTML回调。
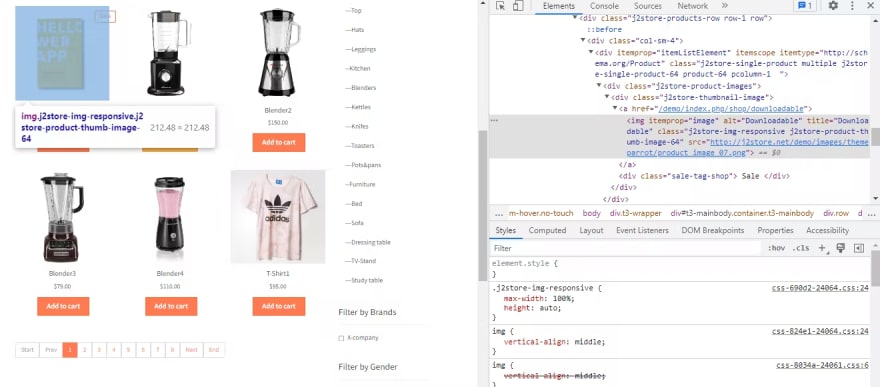
我们已经使用了子元素来获取所需的数据,即名称,价格和iMgurl。您可以像我们为父元素所做的那样看到这些子元素。
最后,将产品详细添加到items中。
现在,main.go看起来像,
package main
import (
"fmt"
"github.com/gocolly/colly"
"github.com/gofiber/fiber/v2"
)
type item struct {
Name string `json:"name"`
Price string `json:"price"`
ImgUrl string `json:"imgurl"`
}
func main() {
app := fiber.New()
app.Get("/scrape", func(c *fiber.Ctx) error {
var items []item
collector := colly.NewCollector(
colly.AllowedDomains("j2store.net"),
)
collector.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
collector.OnHTML("div.col-sm-9 div[itemprop=itemListElement] ", func(h *colly.HTMLElement) {
item := item{
Name: h.ChildText("h2.product-title"),
Price: h.ChildText("div.sale-price"),
ImgUrl: h.ChildAttr("img", "src"),
}
items = append(items, item)
})
collector.Visit("http://j2store.net/demo/index.php/shop") // initiate a request to the specified URL.
return c.JSON(items) //we return the extracted data to the client by calling the c.JSON(...) method.
})
app.Listen(":8080")
}
现在,运行命令go run main.go并在浏览器上前往http://127.0.0.1:8080/scrape。
您会看到以下数据,

现在,此数据来自第一页,但是网站上有多个页面,因此我们必须处理所有页面。 Colly框架对此非常有效。我们需要再添加一个onHTML回调以移至下一页。
collector.OnHTML("[title=Next]", func(e *colly.HTMLElement) {
next_page := e.Request.AbsoluteURL(e.Attr("href"))
collector.Visit(next_page)
})
[title = next]是下一个按钮的CSS选择器。您可以通过与以前相同的方式来看到这一点。现在,HREF标签中添加的URL不是绝对URL,因此我们使用了绝对函数将相对URL转换为绝对URL。
现在,运行命令go run main.go并在浏览器上前往http://127.0.0.1:8080/scrape。

您将看到所有页面中的所有产品详细信息。
这是使用Fiber和Colly Frameworks中的Web刮板的基本实现。
结论
您可以在此处找到本教程的完整代码存储库。
现在,我希望您必须拥有坚实的基础,以建立更复杂和复杂的网络刮擦项目。现在,您可以尝试刮擦动态网站以及数据存储(SQL或NOSQL),图像和文件下载,分布式刮擦等。
要获取有关Golang概念,项目等的更多信息,并且在教程上保持最新信息确实关注Siddhesh on Twitter和GitHub。
在此之前继续学习,请继续建造ðð