Nucleoid是一个低编码框架,它跟踪JavaScript中给定的语句,并在图表中创建变量,对象和功能等之间的关系。因此,就像node.js中的任何其他代码一样编写,运行时将您的业务逻辑转换为通过管理JS状态以及存储在内置数据存储中的全部工作应用程序,以便您的应用程序不需要外部应用程序数据库或其他任何东西。
const nucleoid = require("nucleoidjs");
const app = nucleoid();
class Item {
constructor(name, barcode) {
this.name = name;
this.barcode = barcode;
}
}
nucleoid.register(Item);
// 👍 Only needed a business logic and 💖
// "Create an item with given name and barcode,
// but the barcode must be unique"
app.post("/items", (req) => {
const barcode = req.body.barcode;
const check = Item.find((i) => i.barcode === barcode);
if (check) {
throw "DUPLICATE_BARCODE";
}
return new Item(name, barcode);
});
app.listen(3000);
这几乎是如此,这要归功于核苷运行时,只有使用此ð,您成功地使用了业务逻辑ð
成功地坚持了第一个对象
什么是链链数据存储?
核苷项目的一个重要目标是在同一运行时组合逻辑和数据。 Nucleoid具有内置的链链数据存储,并通过区块链风格的加密持续进行顺序交易。每个事务彼此顺序加密,数据存储将这些哈希保存在托管文件中。每个交易均以子毫秒为单位完成,哈希的任何更改都会引发错误,以确保对象的最终状态,并且如果没有订购的哈希和初始键,就无法看到对象。
。即使包含多个语句,每个调用运行时的调用也被视为交易,如果丢弃了错误,则将交易倒退。
nucleoid.run(() => {
a = 1;
b = a + 2;
c = b + 3;
});
运行时返回这样的东西;结果(如果有),时间戳和交易哈希。
{
"date": 1672179318252,
"time": 1,
"hash": "d3af6bdae8e8ff1eeb1f0f1ea8aaf02e:8b23f8ec493a16cee484f44a6e09a543a62b5e535b8c16ad5f8484766eed686d"
}
重要的不同是,链上数据存储没有存储价值,而是持续的交易,例如在CQR,Event Store等。预计运行时会在内存中累积值。该算法提供快速阅读和快速写的,具有更大的空间复杂性,并且需要在启动时的内存中计算值作为权衡。
例如,此表是作为交易的一部分内置在内存中的:
内存中的值
| 状态 | |
|---|---|
var a |
1 |
var b |
3 |
var c |
6 |
数据存储中的交易
但实际数据存储看起来像这样(虽然这是解码的事务对象):
{ "s": "var a = 1" ... }
{ "s": "var b = a + 2" ... }
{ "s": "var c = b + 3" ... }
哈希是如何生成的?
运行时使用硬编码的创世记作为链中的第一个哈希。当它收到更多的交易时,数据存储使用了先前的哈希以及链中下一个哈希的关键。它使用带有可配置算法的Node.js内置加密软件包。
托管文件中的链上数据的示例~/.nuc/data/:
ff2024a65a339abd3c77bb069da38717:10812ca4ed497e3167684f9b0316b5cf72992adffd9ed8bd97e08f321e117daf367b012
a1a521479a43e1b16ce0ecc1671fbd8d:1ceb5211efadecc791c22a010752ecdf626764a71c4bc80c74f9d3ba6adb88d2e7cedcf
20033f1556383ce5b911436aa76381a8:543a50ae5072aa64acb0ef7c307aa53f3aaea042023704362305bedfafd721c9f918740
ee8a894958d4bb372d1a9e63335ccee7:4834d1e04e6b234135ae896c0057186df4c820b9b25fa6ce153e03f89c63b905208ba07
dc2d6d47071db41845fa8631b131bef5:0ec5427dd957ccb46fbd6884290eb0de9696102405fc606d2acf56e059ed3e827610e6a
3ef42a5927c4e231f17323619d6a60d1:e793031d12c9e5b10708c62d49a56c77fd9ef463606609036d22af83490106c213224e5
3a016c3e71238462f8b42ebb733e5856:cb1595d06424c7e1ec3c353f5eee2d6cf1b804306dcdadb09a6be9a066b89581270464d
可伸缩性
核苷遵循单线程多进程范式。 Sharding处理程序采用JavaScript功能,并允许开发人员创建自己的可扩展性策略。该功能接收其他数据,例如请求标头,车身等,并且还带有核苷运行时以及内置数据存储,因此碎片函数可以持续使用用户数据,以便像Cassandra一样支持memtable。
。
npx nucleoidjs start --cluster
此npx命令启动了专门的核苷实例,就像集群的前门一样。默认的分片函数从REST中获取Process标题,并在进程列表中查找IP和端口信息,并且可以使用process1 = new Process("127.0.0.1", 8448)的调用终端添加群集实例。
可以更改默认函数,其中包括在~/.nuc/handlers/cluster.js中包含一个函数,并从函数中返回流程ID。例如:
// cluster.js
const jwt = require("jsonwebtoken");
function run(req, fn) {
const bearer = req.headers["authorization"];
const token = bearer.split();
const decoded = jwt.verify(token, "secret");
return decoded.company_id; // This returns company id as a process id
}
module.export = run;
基准
这是我们在核苷IDE中的样本顺序应用与MySQL和使用express.js和续集库的Postgr的比较。
。https://nucleoid.com/ide/sample
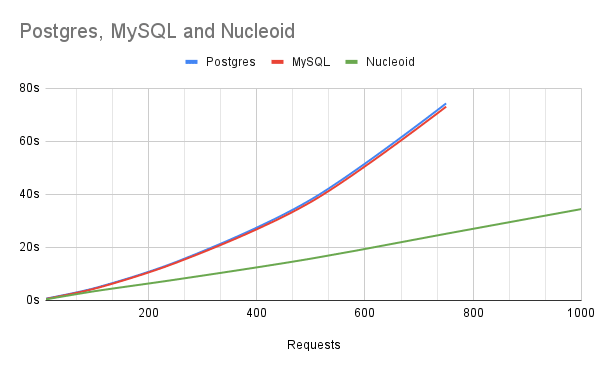
Performance benchmark在AWS EC2实例的T2.Micro中运行,并且两个数据库都有没有索引和默认配置的专用服务器。对于平均复杂性应用,由于链上数据存储,内存计算模型以及限制IO过程,核苷的性能接近线性。
感谢声明性编程,我们采用了全新的数据和逻辑方法。由于我们仍在发现这种强大的编程模型可以做什么,请加入我们的任何类型的贡献!
在https://github.com/NucleoidJS/Nucleoid上了解更多信息
![]()