
介绍
您是否刚刚开始使用特定的数据集或基于现有数据集监视活动和报告,您需要考虑的第一件事是您处理的数据的质量。连续性是衡量时间序列数据质量的最关键因素之一。时间序列系统通常服务于需要迫切需要消耗,处理和采取数据的数据的用例。
以公共交通工具为例。出于与乘客安全性和服务及时性有关的原因,车辆需要各种传感器 - GPS,接近传感器,压力传感器,发动机诊断传感器等。连续使用来自这些传感器的数据有助于公共交通服务保证及时性,安全性和可靠性。但是,来自这些传感器的数据中断将意味着存在问题。
大多数数据访问框架,包括查询语言和可导入的库,允许您过滤并查看缺少数据的列或行。与谈论时间序列数据相比,数据连续性和完整性的概念无关紧要。根据定义,时间序列数据需要连续。但是,连续体的粒度在不同的要求方面可能有所不同。
当您必须在关系数据库中测试数据以完成完整性时,通常必须编写复杂的SQL查询与中间或临时表配对以查找丢失的数据。在某些情况下,这些查询可能是乏味和不表现的。 QuestDB是一个时间序列数据库,可让您以表格形式存储和消耗数据,但这不是您所说的传统关系数据库。为了满足时间序列的工作负载,QuestDB使用SQL扩展扩展标准SQL功能。这些扩展之一是koude0扩展程序,它使您可以轻松查找并处理丢失的数据。
本教程将带您了解如何使用QuestDB's SQL extensions查找数据中的空白,而无需任何复杂的查询或开销。
数据集
为了证明在时间序列数据中查找差距,我们将使用trades数据集,该数据集可以在QuestDB Demo网站上易于获取。 trades数据集包含从2022年3月8日到至今的实时匿名交易数据,以美元为美元。这是trades数据集的表结构:
CREATE TABLE 'trades' (
symbol SYMBOL capacity 256 CACHE,
side SYMBOL capacity 256 CACHE,
price DOUBLE,
amount DOUBLE,
timestamp TIMESTAMP
) timestamp (timestamp) PARTITION BY DAY;
有关数据集的更多详细信息以及用于将数据摄入QuestDB的过程,您可以通过this article进行。现在您已经了解了trades数据集的结构和内容,让我们尝试弄清楚是否缺少任何内容。
查找丢失的数据
使用QuestDB
如前所述,您可以使用SQL扩展名在QuestDB中找到丢失的数据。您需要知道的三个关键字(或sql键盘)是QuestDB所独有的:
- koude0允许您根据时间范围创建组和数据桶。
-
koude6允许您在使用
SAMPLE BY时指定填充行为,从而允许您在数据上执行时间序列插值。 - koude8允许您根据时区或偏移将时间存储库与日历日期对齐。
您可以使用上述SQL扩展的组合找到缺少数据。首先,让我们使用这些扩展名来查看基本查询,以在今年12月到今年的12月进行日常交易,使用以下查询:
SELECT timestamp,
COUNT(*) trades_in_december_2022
FROM 'trades'
WHERE timestamp IN '2022-12'
SAMPLE BY 1d
ALIGN TO CALENDAR;
在选择图表视图中选择绘制选项时,运行此查询为我们提供以下输出:
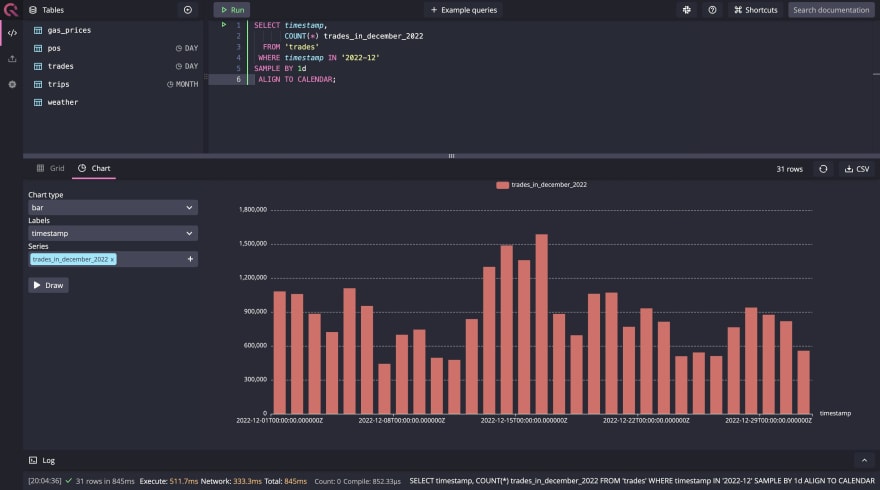
请注意,在任何数据库上都可以在低粒度上运行如此简单的聚合查询。当数据过于颗粒状时,尤其是在实时的情况下,它才会成为其他数据库的问题。现在很明显如何使用所需的SQL扩展名,让我们继续进行查询,以查找丢失的数据。
在查询中,我们将找到trades数据集的体积加权平均价格(VWAP)指标。关键的想法是获取所有时间戳,我们没有数据从数据集的开始日期开始计算所有比特币交易的VWAP。在下面的查询中,您可以使用SAMPLE BY 1s语句以1秒的方式对交易进行采样:
WITH extract AS (
SELECT timestamp,
ROUND(SUM(price * amount) / SUM(amount),2) AS vwap_price,
ROUND(SUM(amount),2) AS volume
FROM trades
WHERE symbol = 'BTC-USD'
AND timestamp > DATEADD('d', -1, NOW())
SAMPLE BY 1s
ALIGN TO CALENDAR)
SELECT timestamp,
vwap_price,
volume
FROM extract
WHERE vwap_price IS NULL
OR vwap_price = 0;
但是,查询不会导致任何内容,如下图所示:

为什么?因为QuestDB如果没有基于SAMPLE BY聚合器的时间戳或时间戳范围的数据,则不会返回任何内容。为了使结果中缺少丢失的数据,您需要使用这样的FILL关键字:
SAMPLE BY 1s FILL(NULL)
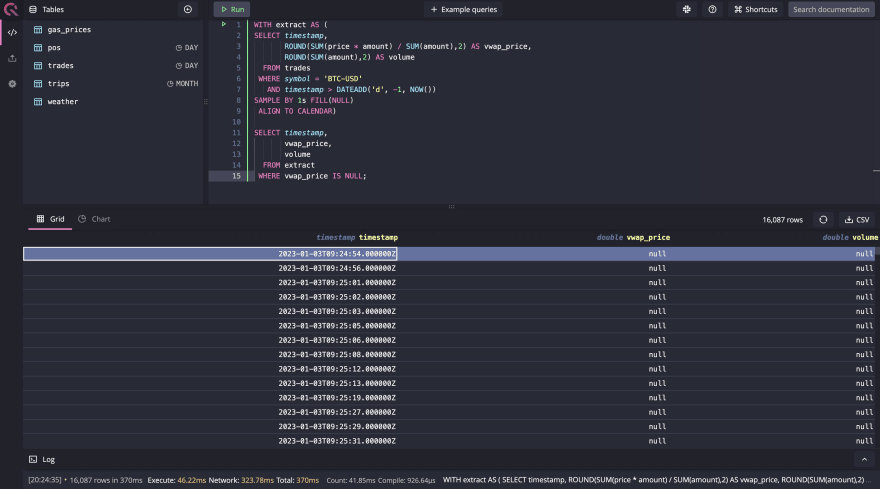
使用此功能,您可以使用NULL强制填写vwap_price的所有零值记录。查找丢失数据的完整查询将如下所示:
WITH extract AS (
SELECT timestamp,
ROUND(SUM(price * amount) / SUM(amount),2) AS vwap_price,
ROUND(SUM(amount),2) AS volume
FROM trades
WHERE symbol = 'BTC-USD'
AND timestamp > DATEADD('d', -1, NOW())
SAMPLE BY 1s FILL(NULL)
ALIGN TO CALENDAR)
SELECT timestamp,
vwap_price,
volume
FROM extract
WHERE vwap_price IS NULL;
运行查询时,您将获得所有丢失数据的1S窗口,如下图所示:
再次,不可否认的是,在较低的粒度维度(例如1D或1M)上汇总的一次性临时查询可能在其他数据库中不难做到。但是,如果您想继续大规模运行这些查询,它们可以在传统的关系数据库中创建性能问题。如果您想每天找到丢失的数据,则可以在其他数据库中获得类似的结果,如下图所示:
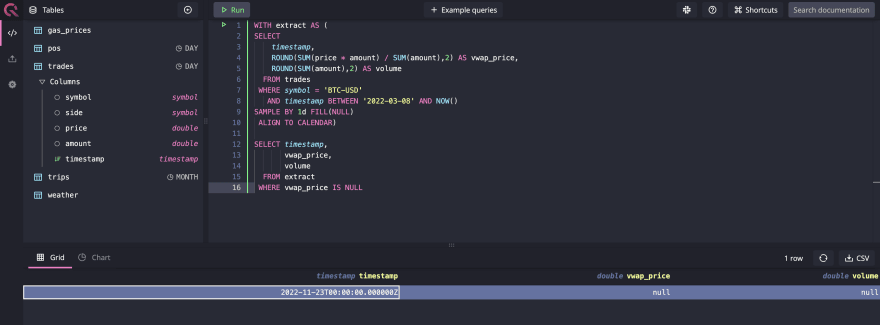
如果您必须在PostgreSQL数据库中执行相同的操作,则需要运行generate_series()功能以生成一堆数据,然后与trades DataSet一起加入。为了简单起见,让我们假设两个系统生成的时间戳格式都相同。要识别PostgreSQL中的差距,您需要编写类似的内容:
WITH all_seconds AS (
SELECT *
FROM generate_series('2022-12-17 00:00:00', '2022-12-17 23:59:59',
INTERVAL '1 second') dummy_timestamp)
SELECT *
FROM (SELECT s.dummy_timestamp,
ROUND(SUM(t.price * t.amount) / SUM(t.amount),2) AS vwap_price,
ROUND(SUM(t.amount),2) AS volume
FROM all_seconds AS s
LEFT JOIN trades AS t
ON s.dummy_timestamp = t.timestamp
GROUP BY s.dummy_timestamp)
WHERE t.vwap_price IS NULL
PostgreSQL的优点是拥有一个支持各种虚拟数据生成用例的发电机函数,如上所述。并非所有数据库都有此功能。例如,在MySQL中,您必须使用递归通用表表达式(CTE)来完成工作。在其他一些数据库中,它可能更麻烦。
如何找到缺少的数据帮助?
识别丢失的数据至关重要,因为它可以极大地影响每个消耗数据的系统或人员的准确性和可靠性。当涉及到时间序列数据库时,许多用例都会想到,尤其是那些涉及边缘计算设备和物联网设备(例如传感器和检测器)的用例。
以传感器的示例来发送有关工业机械中关键系统的数据,例如振动,振动,扭矩,压力等。来自许多这些传感器的数据不仅有助于提高机器效率,而且有助于检测可能的机器故障的早期迹象。
在许多情况下,此数据也可能有助于提高安全性和可靠性。如果破坏了时间序列数据的连续流,即缺少数据,那么实时数据降低了上述好处,并且可能会造成比预期的损害更多的损害这些系统。这就是为什么识别丢失数据的真正价值,而QuestDB使其非常容易。
结论
继续我们的SQL扩展主题,该教程带您通过使用SAMPLE BY,FILL和ALIGN BY CALENDAR的关键字来找到缺少的数据,并具有简单且性能高的查询。本文还探讨了识别丢失数据的一些好处,尤其是在时间序列数据集中。现在,是时候让您试一试了。在demo website上有一个系统为您准备。乘车!