在本文中,我们将介绍以下
- kafka及其用例简介
- 设置KAFKA服务器
- 手动设置
- Docker设置
- 安装Python Kafka库(例如Kafka-Python)
- 向Kafka主题制作消息
- 消费来自Kafka主题的消息
- 高级kafka功能(例如自定义序列化/避免序列化,消息键等)
- 错误处理和故障排除
- 结论和进一步学习的资源
1. Kafka及其用例简介
Apache Kafka是一个分布式流媒体平台,可让您发布并订阅与消息队列或企业消息传递系统相似的记录流。它的关键特征之一是它可以处理大量并发读取和写入的能力,非常适合从多个来源处理大量数据。
KAFKA的一些常见用例包括:
实时数据管道:实时收集和处理数据,例如日志数据,传感器数据和社交媒体供稿。
流处理:分析和处理数据流的生成,例如检测数据中的模式或异常。
事件驱动的体系结构:构建对特定事件响应的构建系统,例如发送消息或触发工作流程。
如果有不止一个,卡夫卡经纪人和客户如何跟踪所有卡夫卡经纪人? Kafka团队决定将 Zookeeper 用于此目的。
Zookeeper用于Kafka世界中的元数据管理。例如:
- Zookeeper跟踪哪些经纪人是Kafka群集的一部分
- Zookeeper被Kafka经纪人使用来确定哪个经纪人是给定分区和主题的领导者,并执行领导者选举
- Zookeeper存储主题和权限的配置
- Zookeeper在更改时向Kafka发送通知(例如,新主题,经纪人DIE,经纪人出现,删除主题等) )
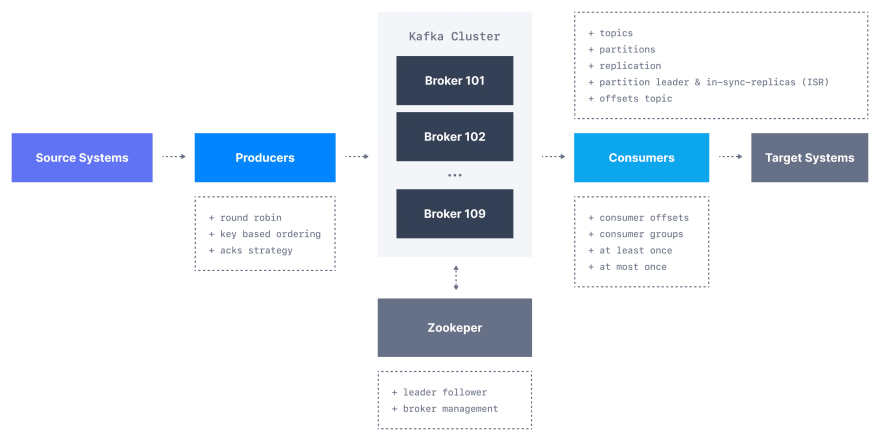
在本教程中,您将学习如何使用Kafka-Python库与Kafka群集进行交互。我们将首先设置一个Kafka群集,然后使用Python代码进行生产和消费消息。
2.0。设置KAFKA服务器(选项1)
设置KAFKA服务器可能会有些涉及,但是设置后,它可以在安装有Java运行时环境(JRE)的任何机器上运行。这是设置KAFKA服务器的一般步骤:
Kafka有两种选择:一个Apache foundation的选择,另一个是Confluent作为包装。对于本教程,我将选择Apache Foundation提供的教程。
- 从Apache Kafka下载最新版本的Kafka。
- 将下载的文件提取到您的计算机上的目录
-
导航到提取的文件夹目录
cd <BASE_DIRECTORY>/kafka_<version> -
通过从kafka目录运行以下命令来启动Zookeeper服务器:
bin/zookeeper-server-start.sh config/zookeeper.properties -
通过从KAFKA目录运行以下命令来启动KAFKA服务器:
bin/kafka-server-start.sh config/server.properties
默认情况下,服务器将在port 9092和port 2181上的Zookeeper服务器上收听。您可以通过修改server.properties和zookeeper.properties文件来更改这些设置。
如果要创建一个多节点KAFKA群集,则需要在单独的计算机上设置并配置其他Kafka经纪人。每个经纪人都需要自己的独特经纪人ID,您需要配置群集,以便经纪人可以相互通信。
您还可以在AWS,GCP或Azure等云提供商上运行Kafka。您可以使用他们的托管Kafka服务或在其虚拟机上启动Kafka群集。
值得注意的是,在生产中运行KAFKA服务器需要大量的配置和监视,因此建议使用托管服务或使用Confluent平台,该平台是Apache Kafka的更完整的分布,其中包含其他功能和管理工具。
2.1。使用Docker设置Kafka服务器(选项2)
使用Docker设置KAFKA服务器可能是快速旋转KAFKA群集以进行测试或开发目的的方便方法。这是使用Docker设置KAFKA服务器的一般步骤:
- 如果尚未安装在计算机上安装Docker。
- 安装docker-compose
-
创建一个
docker-compose.yml文件,并添加以下zookeeper和kafkgaconfig
version: '3.7' services: zookeeper: image: confluentinc/cp-zookeeper:latest container_name: zookeeper environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 ports: - 22181:2181 restart: on-failure kafka: image: confluentinc/cp-kafka:latest container_name: kafka depends_on: - zookeeper ports: - 29092:29092 environment: KAFKA_BROKER_ID: 1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 restart: on-failure -
通过运行以下命令:
启动Zookeeper&Kafka容器docker-compose up -d此命令将启动一个名为“ Kafka”的新容器,并将主机计算机的
29092映射到容器的端口'29092'。它还将“ kafka”容器链接到“ Zookeeper”容器,以便Kafka容器可以连接到Zookeeper容器。 -
检查日志以查看Zookeeper容器已成功启动
docker logs zookeeper ## Output -> ## ... ## 2023-01-25 13:22:48 [2023-01-25 10:22:48,634] INFO binding to port 0.0.0.0/0.0.0.0:32181 (org.apache.zookeeper.server.NIOServerCnxnFactory) ## ... -
检查日志以查看Kafka服务器已成功启动
docker logs zookeeper ## Output -> ## .... ## [2023-01-25 13:00,295] INFO [Kafka Server 1], started (kafka.server.KafkaServer) ## [2023-01-25 13:31:00,295] INFO [Kafka Server 1], started (kafka.server.KafkaServer) ## ...
值得注意的是,上述设置是用于开发和测试目的,在生产中运行KAFKA服务器需要大量的配置和监视,因此建议使用AWS MSK,GCP或Azure或使用Conflunent的托管服务更高级功能和管理工具的平台。
简单的Python项目
注意: 确保在下面的步骤中获得正确的kafka版本。您可以使用以下命令
获得此BU
docker exec kafka kafka-topics --version # with docker setup
bin/kafka-topics.sh --version # If you used the manual setup
输出应该是这样的:
7.3.1-ccs (Commit:8628b0341c3c46766f141043367cc0052f75b090)
3.1。安装Python Kafka库(例如Kafka-Python)
确保已安装了kafka-python库,可以通过PIP安装它:
pip install kafka-python
3.2。为Kafka主题制作消息
创建一个名为producer.py的新文件,并添加以下代码:
import os
import time
import json
from kafka import KafkaProducer
KAFKA_BOOTSTRAP_SERVERS = os.environ.get("KAFKA_BOOTSTRAP_SERVERS", "localhost:29092")
KAFKA_TOPIC_TEST = os.environ.get("KAFKA_TOPIC_TEST", "test")
KAFKA_API_VERSION = os.environ.get("KAFKA_API_VERSION", "7.3.1")
producer = KafkaProducer(
bootstrap_servers=[KAFKA_BOOTSTRAP_SERVERS],
api_version=KAFKA_API_VERSION,
)
i = 0
while i <= 30:
producer.send(
KAFKA_TOPIC_TEST,
json.dumps({"message": f"Hello, Kafka! - test {i}"}).encode("utf-8"),
)
i += 1
time.sleep(2)
producer.flush()
此代码创建了一个新的KAFKA生产商,该生产商已连接到由“ Bootstrap_servers”参数指定的KAFKA群集。然后,代码发送消息“您好,Kafka!”主题“测试”。我们在每次迭代中都要休息2秒。
3.3。来自Kafka主题的信息
创建一个名为consumer.py的新文件,并添加以下代码:
import os
from kafka import KafkaConsumer
from time import sleep
KAFKA_BOOTSTRAP_SERVERS = os.environ.get("KAFKA_BOOTSTRAP_SERVERS", "localhost:29092")
KAFKA_TOPIC_TEST = os.environ.get("KAFKA_TOPIC_TEST", "test")
KAFKA_API_VERSION = os.environ.get("KAFKA_API_VERSION", "7.3.1")
consumer = KafkaConsumer(
KAFKA_TOPIC_TEST,
bootstrap_servers=[KAFKA_BOOTSTRAP_SERVERS],
api_version=KAFKA_API_VERSION,
auto_offset_reset="earliest",
enable_auto_commit=True,
)
for message in consumer:
print(message.value.decode("utf-8"))
sleep(1)
此代码创建了一个新的KAFKA消费者,该消费者连接到由“ Bootstrap_servers”参数指定的KAFKA群集。然后,代码订阅了主题“测试”,并不断对新消息进行轮询。收到的每个消息都打印到控制台。我们在每次迭代中都要休息2秒。
-
运行producer.py脚本以将消息发送到Kafka主题
python producer.py -
运行consumer.py脚本以消耗卡夫卡主题的消息
python consumer.py
这将启动消费者,该消费者将不断对“测试”主题的新消息进行调查。每次收到消息时,都会打印到控制台。
6.高级卡夫卡功能
kafka提供了许多您可以在应用程序中使用的高级功能,包括:
压缩:您可以在发送到kafka之前压缩消息以节省带宽
消息键:您可以为每个消息指定一个可以用于分区消息的键
消费者群体:允许您让多个消费者从同一主题中阅读,从而实现并行处理和负载平衡
容错:Kafka设计为容忍故障,可以处理单个节点的故障而不会丢失消息或影响性能
7.错误处理和故障排除
与任何分布式系统一样,使用KAFKA时可能会出现错误。您可能遇到的一些常见错误包括:
连接错误:当生产者或消费者无法连接到kafka群集时,就会发生这些。
领导者不可用:当分区的领导者经纪人无法使用
时,会发生此错误
要对这些错误进行故障排除,您可以检查Kafka经纪人和消费者的日志,并检查错误消息。 Kafka-Python库还提供了几个例外类,您可以在代码中捕获和处理,例如Kafkaerror和kafkatimeouterror。
8.结论和进一步学习的资源
在本教程中,我们介绍了使用Kafka-Python库与Kafka群集交互的基础知识。我们已经展示了如何设置Kafka群集,制作和消费消息,并使用Kafka提供的一些高级功能。
要继续学习Kafka,您可以查看官方的Kafka documentation以及Kafka-python library的文档。还有许多在线可用的教程和博客文章涵盖了使用Kafka的不同方面。
我希望本教程有助于您开始使用Kafka和Kafka-Python库。让我知道您是否希望我还包括其他任何内容。
ps:这是指向最终项目的GitHub链接
Apache Kafka with Python
Screen.Recording.2023-01-25.at.16.55.49.mov
如何设置项目
功能
- Python 3.10
- poetry作为依赖项经理
项目设置
- 克隆存储库
git克隆https://github.com/hesbon5600/kafka-python.git
- CD进入目录
cd kafka-python
创建环境变量
在unix或macOS上,运行:
cp .env.example .env
您可以编辑其中喜欢的任何值。
注意:'='
旁边没有空间在终端
上 source .env
虚拟环境
创建:
使Env
安装依赖项:
使安装