很多时候,我们的典型服务器响应是JSON或XML的形式。这为我们的用例服务了很多次,但是有时需要以文件的形式提供数据。
在本文中,我们将探索如何将模型数据转换为文件,并将其作为Django Rest框架(DRF)中的响应发送。我们将通过建立一个简单的项目来做到这一点。
先决条件
您应该拥有一些基本的Django和Django Rest框架知识。您还应该已经在系统上安装了Python。
该项目,设置和安装
我们将构建一个简单的学生管理应用程序。该应用的目的将是:
-
允许用户输入学生数据
-
下载所有可用数据作为CSV,Excel或TXT文件。
创建项目并安装依赖项
我们将安装Django和DRF开始。为此,首先,创建您的虚拟环境并激活它。
python3 -m venv studentappenv
source studentappenv/bin/activate
现在安装Django和DRF。我们还将安装openpyxl,这是一个Python软件包,在与数据和Excel文件进行交互时有助于。
pip install django djangorestframework openpyxl
接下来,创建Django项目并创建一个应用程序。
django_admin startproject student_management .
python manage.py startapp student_data
更新您的设置。
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'student_data', #new line
]
让我们创建我们的模型。前往student_data/models.py
from django.db import models
class StudentData(models.Model):
STUDENT_GENDER = ((1, 'Male'), (2, 'Female'), (3, 'Other'))
STUDENT_LEVEL = ((1, 'Junior'), (2, 'Senior'))
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
age = models.IntegerField()
gender = models.IntegerField(choices=STUDENT_GENDER)
level = models.IntegerField(choices=STUDENT_LEVEL)
一个非常简单的模型,该模型存储基本的学生信息。这将足以满足我们的需求。
接下来,我们创建我们的序列化器。在student_data文件夹中创建一个新文件serializers.py并在内部添加以下内容。
from rest_framework import serializers
from .models import StudentData
class StudentDataSerializer(serializers.ModelSerializer):
class Meta:
model = StudentData
fields = ' __all__'
def to_representation(self, instance):
data = super().to_representation(instance)
data['gender'] = instance.get_gender_display()
data['level'] = instance.get_level_display()
return data
这也是我们StudentData模型的基本序列化器。我们覆盖我们的to_representation,以更改服务器将如何返回gender和level字段的值。而不是返回像'gender': '1'这样的东西,我们将获得'gender': 'Male'。
现在,我们拥有模型和序列化器,让我们创建我们的观点。在student_data/views.py中,添加以下代码行:
from django.utils import timezone
from rest_framework.response import Response
from rest_framework.viewsets import ModelViewSet
from rest_framework.decorators import action
from .models import StudentData
from .serializers import StudentDataSerializer
class StudentDataViewset(ModelViewSet):
serializer_class = StudentDataSerializer
queryset = StudentData.objects.all()
@action(detail=False, methods=["get"])
def download(self, request):
queryset = self.get_queryset()
serializer = StudentDataSerializer(queryset, many=True)
return Response(serializer.data)
这是我们的观点,它将处理POST的请求来创建我们的学生数据。我们还定义了一个新的Viewset Action download,我们将用于下载文件响应。现在,它将仅作为JSON响应返回数据,我们将尽快对其进行调整以满足我们的需求。
让我们连接我们的URL路径。在student_data文件夹中创建一个urls.py文件。
# student_data/urls.py
from .views import StudentDataViewset
from django.urls import path, include
from rest_framework import routers
router = routers.DefaultRouter()
router.register("", StudentDataViewset, basename="student-data")
urlpatterns = [
path("", include(router.urls)),
]
将其连接到student_management文件夹的主URL文件。
# student_management/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('student-data/', include('student_data.urls')),
]
运行makemigrations and Migrate
python manage.py makemigrations
python manage.py migrate
使用python manage.py runserver启动服务器。
在http://127.0.0.1:8000/student-data/上提出一些POST请求,以用一些数据填充我们的数据库。

现在,使用GET请求测试http://127.0.0.1:8000/student-data/download/端点,以查看响应类型。您将获得JSON数据作为与我们从POST请求中看到的相似的响应。这是因为DRF设置了一个全局默认渲染器rest_framework.renderers.JSONRenderer,该渲染器将返回application/json媒体类型中的服务器响应。
我们将创建自己的渲染器,将我们的数据转换为我们想要的响应格式。
在student_data文件夹中创建一个renderers.py文件。
# student_data/renderers.py
import io
import csv
from rest_framework import renderers
STUDENT_DATA_FILE_HEADERS = ["id", "first_name", "last_name", "age", "gender", "level"]
class CSVStudentDataRenderer(renderers.BaseRenderer):
media_type = "text/csv"
format = "csv"
def render(self, data, accepted_media_type=None, renderer_context=None):
csv_buffer = io.StringIO()
csv_writer = csv.DictWriter(csv_buffer, fieldnames=STUDENT_DATA_FILE_HEADERS, extrasaction="ignore")
csv_writer.writeheader()
for student_data in data:
csv_writer.writerow(student_data)
return csv_buffer.getvalue()
这将是将我们的数据转换为CSV格式的渲染器。让我们分解此代码。
-
我们设置了一个包含我们所有模型字段的
STUDENT_DATA_FILE_HEADERS列表。 -
我们的
CSVStudentDataRendererclass子类BaseRenderer并定义了media_type和format属性。我们有许多不同的媒体类型,您可以在IANA defined media types (mime types)上找到这些类型。 -
我们定义了大量工作的渲染方法。里面:
-
我们创建一个名为
csv_buffer的字符串缓冲区。 -
我们创建了一个
csv.DictWriter的实例,并作为参数传递给我们的缓冲区。 -
我们称为
csv_writer.writeheader(),将STUDENT_DATA_FILE_HEADERS中的值写为我们CSV文件的第一行。 -
我们使用
csv助手模块将数据写入缓冲区位置中的逗号分隔值。 -
我们用
csv_buffer.getvalue()检索写入缓冲区的内容
让我们下一步为Excel和文本文件添加渲染器。更新renderers.py文件。
import io
import csv
import openpyxl # new
from rest_framework import renderers
STUDENT_DATA_FILE_HEADERS = ["id", "first_name", "last_name", "age", "gender", "level"]
...
# ------ NEW LINES --------
class TextStudentDataRenderer(renderers.BaseRenderer):
media_type = "text/plain"
format = "txt"
def render(self, data, accepted_media_type=None, renderer_context=None):
text_buffer = io.StringIO()
text_buffer.write(' '.join(header for header in STUDENT_DATA_FILE_HEADERS) + '\n')
for student_data in data:
text_buffer.write(' '.join(str(sd) for sd in list(student_data.values())) + '\n')
return text_buffer.getvalue()
class ExcelStudentDataRenderer(renderers.BaseRenderer):
media_type = "application/vnd.ms-excel"
format = "xls"
def render(self, data, accepted_media_type=None, renderer_context=None):
workbook = openpyxl.Workbook()
buffer = io.BytesIO()
worksheet = workbook.active
worksheet.append(STUDENT_DATA_FILE_HEADERS)
for student_data in data:
worksheet.append(list(student_data.values()))
workbook.save(buffer)
return buffer.getvalue()
这个想法与我们的CSVStudentDataRenderer相同。我们定义了我们预期文件的正确的media_type和format。然后,我们创建一个缓冲区,将标题和模型数据写入其中。之后,我们返回缓冲区的内容。对于我们的ExcelRenderer,我们使用openpyxl库来简化缓冲区写作过程。
现在我们有了渲染器,让我们更新我们的视图以使用它。更新您的student_data/views.py文件。
from django.utils import timezone
from rest_framework.response import Response
from rest_framework.viewsets import ModelViewSet
from rest_framework.decorators import action
from .models import StudentData
from .renderers import CSVStudentDataRenderer, ExcelStudentDataRenderer, TextStudentDataRenderer
from .serializers import StudentDataSerializer
class StudentDataViewset(ModelViewSet):
serializer_class = StudentDataSerializer
queryset = StudentData.objects.all()
@action(detail=False, methods=["get"], renderer_classes=[CSVStudentDataRenderer, ExcelStudentDataRenderer, TextStudentDataRenderer])
def download(self, request):
queryset = self.get_queryset()
now = timezone.now()
file_name = f"student_data_archive_{now:%Y-%m-%d_%H-%M-%S}.{request.accepted_renderer.format}"
serializer = StudentDataSerializer(queryset, many=True)
return Response(serializer.data, headers={"Content-Disposition": f'attachment; filename="{file_name}"'})
新更改的三个主要收获是:
-
我们在
@action装饰器中定义了renderers_classes参数。选择渲染器时,download端点将使用它。它将如何决定?我们将在一分钟内谈论。 -
我们根据当前时间创建一个独特的文件名,并附加渲染器的格式,该格式用于服务于特定响应,在
request.accepted_renderer.format中找到。 -
我们设置了一个
content-dispostion标头,让客户知道应将响应视为应根据filename值下载的附件。
让我们回到邮递员测试我们的download端点。

我将CSV文件下载到我的系统上。

太好了。这意味着Django决定使用我们的CSVRenderer,但是它是如何决定的? Django具有一种内容谈判机制,它用来确定如何向客户提供响应。它查看了请求中的Accept标头,并试图将其映射到可用的渲染器。如果它无法将其映射到任何特定的特定映射,则Django在renderers_classes列表中选择了第一个渲染器。这就是为什么我们会收到一个CSV文件以返回。
让我们编辑我们的Accept请求标题并指定Excel媒体类型(application/vnd.ms-excel),然后重试该请求。
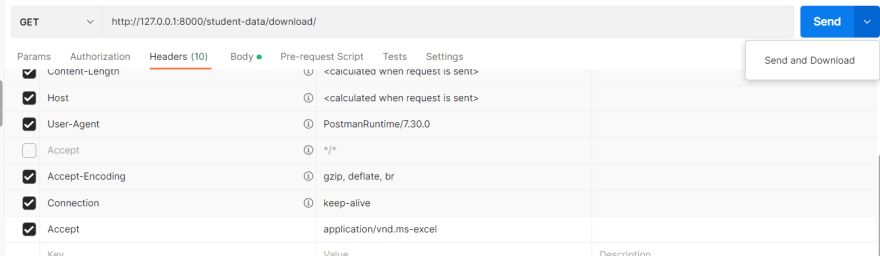
我现在下载了一个Excel文件。

,如果我们将Accept标头更新为text/plain,我们将下载一个txt文件,因为django选择了文本渲染器类。
就是这样。
结论
在本文中,我们学会了如何为Excel,CSV和文本等特定媒体类型和格式创建自己的自定义渲染器。我们还看到了如何使用Accept请求标题来帮助我们的应用程序选择正确的渲染器。
如果您发现这篇文章有用或学到了新知识,请考虑放心并关注我以保持最新的任何帖子!
!您也可以在akinsola232的Twitter上和Ademola的LinkedIn上找到我。
直到下次,愉快的编码!
levi