简短的介绍
在1938年之前,沙特阿拉伯的中东王国是一个尘土飞扬的沙漠国家,散布着人和动物的迁徙人群。但是,当石油袭击时,该地区及其人民目睹了巨大的转变。沙特人可能已经知道化石燃料了,但是美国石油地质学家马克斯·斯坦尼克(Max Steineke)以商业数量发现了资源。
与沙特阿拉伯的石油一样,今天的许多企业都会产生大量数据,并且大多数企业几乎不知道数据的资源是多么宝贵。许多人将数据称为new oil of the digital economy,因为如果适当利用,它可以扭转企业。一些企业是1938年以前的沙特阿拉伯 - 他们对存储在众多Excel床单中的数据以及(也许)在基于云的数据库中有一个想法,但完全没有意识到资源的商业福利。
数据分析是当今巨大的领域,这主要是由于巨大的业务分析运动,最重要的是,Python作为数据分析的方便工具的兴起。 Python是用于数据分析书呆子和数据科学家的流行脚本语言。实际上,TIOBE Index for January 2023表明,Python将数百个竞争对手视为总体上最受欢迎的编程语言,并且是2007年,2010年,2018年,2020年和2021年的年度语言。
。我与Python的第一次相遇是在2019年。我正在YouTube寻找有关R的最佳教程,这是数据分析师的另一种重要语言。对Python的热爱在第一个视频中增长了几分钟 - 我发现语法吸引人和IDE易于使用。相反,rstudio给了我惊慌的发作,语法感到失望了。
我更深入地挖掘了python,恋情继续从力量到力量增长。在此期间,我意识到,与任何其他技术技能一样,学习Python的最佳方法是通过常规项目。我还了解到,Kaggle是一个可以用来抛光数据分析和其他Python技能的数据集的大量存储库。
这个项目是未来许多项目中的第一个。它使用可从Kaggle下载的数据集(通过此link)。另外,对基思·加利(Keith Galli)的大喊大叫,我从他的阿比亚奇(YouTube video)那里汲取了关键的课程。
项目介绍:
数据集的目标是使数据分析师能够练习基本的探索性数据分析(EDA)和清洁。
我们应该在本演讲结束时回答以下问题:
- 什么是最佳销售月份,在线技术商店赚了多少?
- 技术店在哪个城市出售了最多的产品?
- 商店如果想最大化购买的商店应该显示广告?
- 商店应该向买家组成什么产品?
- 在数据的12个月中,商店销售最多的产品?
数据争吵
预赛
导入必要的库
import pandas as pd # for data wrangling
import glob # for collecting files from system into the program
import matplotlib.pyplot as plt # for visualization
plt.style.use("fivethirtyeight") # default theme for plots
将数据集加载到笔记本中
您可能已经注意到,数据可在12个文件中(2019年每个月)提供。不可能使用此类碎片文件,因此我们必须将它们合并到一个文件中。
提示:
- 使用
glob.glob()与所有文件创建一个对象,然后使用pandas.concat()串联它们
# if you created the notebook in the same directory
# as the dataset, the dataset's root path is:
root_path = "./Sales_Data"
# assign all files to one variable
files = glob.glob(f'{root_path}/*.csv', recursive=True)
将文件加载到当前工作空间中并将它们分配给变量。
# I use list comprehensions to iterate through
# the 'files' variable created earlier.
# read more on list comprehensions if you have
# trouble understanding what is happening here.
all_files = [pd.read_csv(file) for file in files]
# Concatenate the files into one huge file
# and assign it to 'df' variable
df = pd.concat(all_files, axis=0)
# to be sure all is well, print the first five
# rows of the data frame
df.head()
运行df.head():
后,您应该看到这样的东西
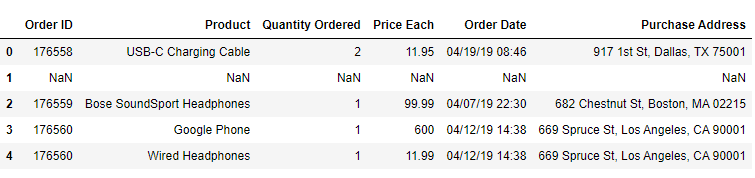
现在将数据集成功加载到笔记本中。
数据清洁
数据清洁是数据分析过程中最征税的阶段。它需要删除数据集中的错误格式,重复,不完整或损坏的数据。此步骤是必要的,主要是因为大多数数据集很混乱。
典型的数据清洁工作涉及两个主要任务:
- 研究数据集是否缺少值。
- 检查每列的数据类型。
这个article详细讨论了这些步骤。
让我们完成每个数据清洁任务:
调查数据集是否缺少值
确认数据集缺失值后,您可以选择清除包含缺失值的行或用任意值填充它们。
让我们看看我们的数据集是否缺少值:
# Check for the total number of null values
# per column
df.isnull().sum()
输出应显示以下内容:

缺少数据的统一性意味着有完全不可用的数据的完整行,这也意味着我们只丢弃所有NAN都会好起来的。
使用此命令:df.dropna()删除NAN值。
研究数据类型
接下来,让我们检查每列的数据类型,看看我们是否需要进行一些更改。为此,请使用.info()函数。它提供了数据集的摘要,即条目总数(行),列数和每个列中值的数据类型。
# Check the data type for each column
df.info()
输出应该看起来像这样:

请注意,所有列的数据类型均为object。在熊猫中,object数据类型表示混合的非数字和数字值或文本。 Python认识到字符串等值。因此,object数据类型基本上是Python String数据类型。阅读更多here。
再次查看数据,直觉应该告诉您Quantity Ordered和Price Each之类的列应具有数值值。让我们进行更改如下:
# Convert 'Quantity Ordered' and 'Price Each' column values
# to numeric (either float or int)
df['Quantity Ordered'] = pd.to_numeric(df['Quantity Ordered'])
df['Price Each'] = pd.to_numeric(df['Price Each'])
如果您与我一起编码,则编译器在运行上述代码后可能会出现错误。我的看起来很喜欢:

关于编译器错误的美丽是,他们指出了您的问题,您可以解决该问题并继续进行分析。查看错误消息,您会注意到它是一个ValueError,这意味着编译器将值转换为数字时遇到了一些意外值。错误消息的最重要部分是读取ValueError: Unable to parse string "Quantity Ordered" at position 519。
让我们解决这个问题。首先,直接直达位置(位置519)。 注意:您的位置可能有所不同,只需前往错误消息指向您的位置。
检查位置519的条目会产生以下结果:
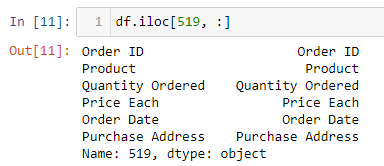
显然,将12个文件合并到一个pandas数据框架中时,数据集确实搞砸了。现在,它具有带有列名的行,即 订购ID , product 等。其次,由于不需要它们而清除这些行。
可以应用各种方法来删除行;我更喜欢创建掩码的地方(我们不需要的数据集的一片)。然后选择所有不包括不需要(或蒙版)值的值。这样:
mask = df.iloc[: , 0] != 'Order ID' # all rows in the first
# column that do not contain
# the value 'Order ID'
# slice off the unwanted values
df = df[mask]
现在,如果您尝试像以前一样转换数据类型,则编译器不应抱怨。
再次运行df.info()应该表明数据类型已更改。每列的新数据类型应如下:

请注意,两列的数据类型现在已更改为float64。成功!
因此,我们已经摆脱了丢失的值,将数据类型转换为适当的值,并删除了不需要的行。这是确保我们的数据集准备进一步操作的关键工作,以便我们可以开始回答燃烧的问题。附带说明,我们可能需要在回答问题的过程中进行更多的数据争吵,因为当我们与数据集播放时会出现更多的问题。使用数据集播放的一部分包括添加新列,该列引入了数据。
。回答问题
问题1:最佳销售月份是什么?在线技术商店赚了多少?
最佳数据分析师可以在问题中看到关键单词或短语,这将它们指向他们应采取的特定操作来解决解决方案。在此问题中,关键字/关键短语是最佳月份和销售。这意味着我们应该查看每个月的总销售额。
,但我们可能有问题。我们的数据集没有 sales 列或月列。因此,我们必须从现有列创建它们。让我们首先处理 sales 列。
通常,您通过将 数量乘以每个单元的 Price 来确定销售价值。在这种情况下,我们将做同样的事情,只是我们要乘以两列, dordity dordity 和价格。
df['Sales'] = df['Quantity Ordered'] * df['Price Each']
执行df.head()将显示数据集现在有一个额外的列,称为 sales 。

创建月列将需要更多的能量,也许需要一些Google搜索。但是担心不是因为我已经这样做了。
查看订单日期列,您会注意到每个条目都有订单的月,日,年和时间。我们可以通过将每个条目分配为前向斜杠符号/来提取月份。我们使用如图所示的pandas.Series.str.split方法(确保expand设置为True)。
df['Order Date'].str.split('/', expand=True)
执行代码后的输出将为:
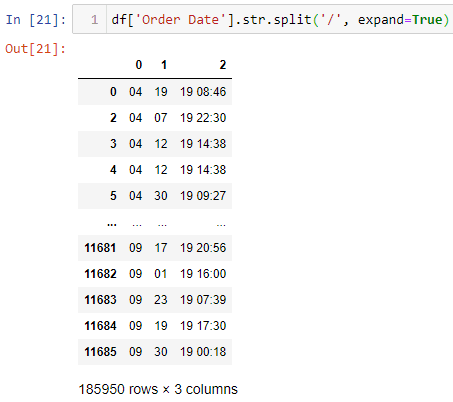
但是,我们只对index 0的月份专栏感兴趣。所以,
df['Order Date'].str.split('/', expand=True)[0]
# assign it to the 'Month' column
df['Month'] = df['Order Date'].str.split('/', expand=True)[0]
再次执行df.head()再次显示我们有一个新列, montr 。

现在,我们有需要的专栏,我们可以回答这个问题吗?
我们必须确定销售的最佳月份以及该月在线技术商店的总销售额。在Pandas中,有一种groupby()方法,可以通过特定列(或功能)将数据值分组。在这种情况下,我们将按月分组数据值,然后找到每个月的总销售额如下:
df.groupby('Month')['Sales Amount'].sum()
执行代码会产生以下输出:

尽管结果值得称赞,但读者不能立即分辨出哪个月的记录是最佳的销售价值,除非它们通过输出限制。数据分析师的主要目标是使最终用户(即分析/读者的消费者)尽可能简单。通过图表传达足够细节的同时,实现便利性的简单性的最佳方法是。因此,让我们创建第一张图表,显示上述代码的输出。
# data
months = range(1, 13)
sales = df.groupby('Month')['Sales'].sum().values
# plot
fig, ax = plt.subplots(figsize=(10,6))
ax = plt.plot(months, sales)
plt.xticks(months)
# prevent the y axis from displaying data with scientific notation
plt.ticklabel_format(useOffset=False, style='plain')
plt.title('Total Sales per Month', pad=20)
plt.ylabel('Sales', labelpad=20)
plt.xlabel('Month', labelpad=20)
# save the plot to 'plots' directory
plt.savefig('plots/sales_per_month.png', dpi=600, bbox_inches='tight')
plt.show()
输出如下所示:
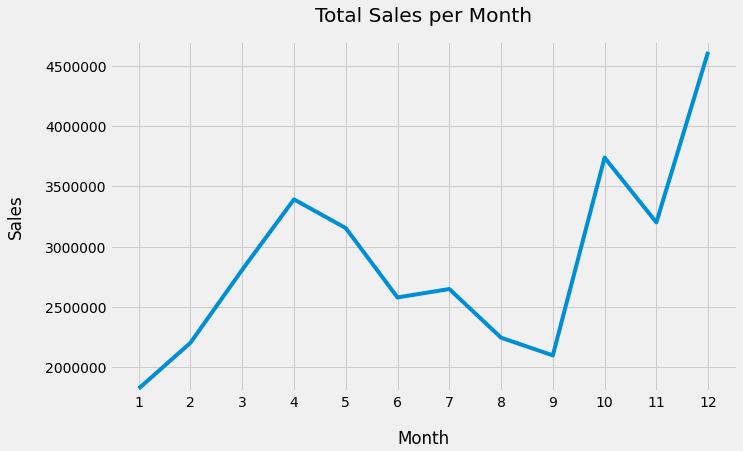
显然,在线技术商店在12月($ 4,613,443) 中记录了最高的销售价值。
问题2:技术商店在哪个城市销售最多的产品?
再次,此处的关键字是 city 和产品销售或订购的数量是具体的。预计我们将确定技术商店在12个月的数据中出售最多产品的城市。
与上一个问题类似,我们的数据集没有 city 列。让我们创建它。
在数据集中,在购买地址列中找到了从中订购产品的城市。问题在于我们可能必须将条目分开以提取城市。 注意:可以安全地将城市与州法规一起提取。美国的一些州有名字相同的城市。
df['Purchase Address'].str.split(',', expand=True)[[1,2]]
state_code = df['Purchase Address'].str.split(',', expand=True)[2].str.strip().str.split(" ", expand=True)[0]
city = df['Purchase Address'].str.split(',', expand=True)[1]
df["City"] = city + " " + state_code
在执行代码块并运行df.head()时,您会注意到数据集右端的 city 列。

准备好 City 列,让我们再次了解我们对我们的问题。它说,我们应该确定技术店销售最多产品的城市。这意味着我们应该按城市对数据集进行分组,然后评估有序数量的总和。这样:
df.groupby('City')['Quantity Ordered'].sum()
输出应该看起来像这样:
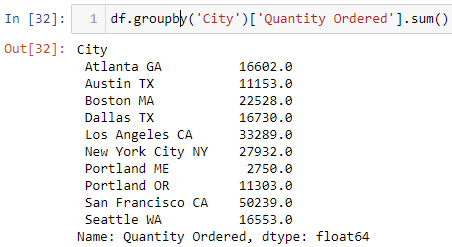
但同样,该分析的消费者可能会发现不方便地从输出中查明答案。和以前一样,让我们创建一个清晰的图表。
# data
cities = [city.lstrip() for city, df in city_group]
quantity_ordered = df.groupby('City')['Quantity Ordered'].sum().values
# plot
fig, ax = plt.subplots(figsize=(10,6))
ax= plt.bar(cities, quantity_ordered)
plt.xticks(cities, rotation=90)
plt.title('Quantity Ordered by City', pad=20)
plt.ylabel('Quantity Ordered', labelpad=20)
plt.xlabel('City', labelpad=20)
plt.grid(False)
plt.savefig('plots/quantity_ordered_city.png', dpi=600, bbox_inches='tight')
plt.show()
最终图表如下:

从图表中,技术商店在 旧金山,CA 中出售了更多的产品。
问题3:商店是否要最大程度地购买商店?
您认为我们应该在这里做什么?好吧,问题是谈论时间,这意味着焦点列是订购日期。与以前提取月份不同,此任务涉及提取小时。我们不需要分钟,因为它在回答手头的问题中起着微不足道的作用。
Python编程社区最有趣的方面是编码人员为解决特定问题开发的一系列技术。例如,我们使用pandas.Series.str.split方法在问题1 中提取月份。另外,我们可以使用PANDAS方法pandas.to_datetime,将订购日期下的条目转换为A datetime 对象,然后提取小时。见下文:
# convert 'Order Date' to datetime
df['Order Date'] = pd.to_datetime(df['Order Date'])
# extract the hour then assign it to 'Hour' column
df['Hour'] = df['Order Date'].dt.hour
运行df.head()显示一个新列, hour 。

创建了小时列,我们可以继续检查问题。它要求技术商店应该展示广告,以最大程度地提高客户购买产品的可能性。我们如何处理此任务?
一种方法可能是检查产品 小时的数量。检查小时和订购数量之间的关系可能会指向我们对这个问题的正确答案。让我们创建一个数量的图, vs 小时:
# data
hour = [f'{0}{hour}' if len(str(hour)) < 2 else str(hour) for hour, df in df.groupby('Hour')]
quantity_ordered = df.groupby('Hour')['Quantity Ordered'].sum().values
# plot
fig, ax = plt.subplots(figsize=(10, 6))
ax= plt.plot(hour, quantity_ordered)
plt.xticks(hour)
plt.title('Quantity Ordered by Hour', pad=20)
plt.ylabel('Quantity Ordered', labelpad=20)
plt.xlabel('Hour', labelpad=20)
plt.savefig('plots/quantity_ordered_hour.png', dpi=600, bbox_inches='tight')
plt.show()
此代码块的输出显示如下:
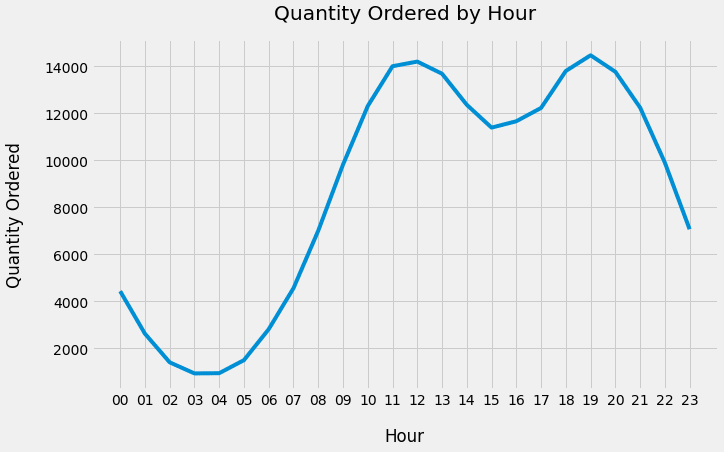
该图显示了一种有趣的关系 - 订单的数量比早晨的六点急剧增加,在上午11点至中午12点之间达到顶峰。中午后趋势下降,然后在晚上7点建立另一个峰。
通常,企业会希望潜在客户在下达采购订单之前查看其产品。这是说技术商店应在订单数量达到高峰之前显示广告, 上午11点 和 6pm 。
问题4:商店应该向买家组成什么产品?
解决这个问题问自己的最佳方法,科技商店如何知道推荐哪些产品?查看订单ID 列,您会注意到几个重复的订单ID。换句话说,几种产品共享相同的订单ID,这意味着它们被订购在一起。在线商店经常将不同的产品捆绑在单个订单ID下以跟踪销售。
我们如何使用此信息来解决问题?好吧,我们可以将产品分组为新的列,称为 galted 。按照下面的代码完成此操作:
# You may want to create a copy of the dataset before
# you proceed
new_df = df.copy()
# Slice the new dataset to keep only
# the products with duplicated Order ID
new_df = new_df[new_df['Order ID'].duplicated(keep=False)]
# Store the grouped products into a column called _Grouped_
new_df['Grouped'] = new_df.groupby('Order ID')['Product'].transform(lambda x: ','.join(x))
在执行代码块时,运行new_df.head(),输出应该看起来像:

现在,我们可以在分组列中删除重复的条目。另外,我们只对 order ofer ID 和分组列感兴趣,因此仅选择这些列。
new_df = new_df[['Order ID', 'Grouped']].drop_duplicates()
new_df.head()的输出应为:

现在,让我们找到最常见的产品。在下面的代码块中,我们确定了三个组中出售的10个最常见的产品。
注意:我们将导入一些新库
from itertools import combinations
from collections import Counter
# initialize an empty Counter object
count = Counter()
for row in new_df['Grouped']:
# split the grouped products
row_list = row.split(',')
# the most common products sold as group of three
count.update(Counter(combinations(row_list, 3)))
# ten most common groups of three
for key, value in count.most_common(10):
print(key, value)
输出应为:

输出表示 Google Phone , usb-c充电电缆 , 有线耳机 一起出售 87次 。因此,商店应向客户推荐他们作为一个小组购买。其他值得注意的组合是 iPhone , 闪电充电电缆 和 有线耳机 作为一个组购买 62次 , iPhone , 闪电充电电缆 和 Apple AirPods耳机 作为组 47次 。
问题5:在数据的12个月中,商店销售最多的产品?
正如我们之前所做的那样,理解这个问题需要我们确定关键字,这些关键字是 product 和 dordity dordity dordity 。因此,我们将通过 product 列对数据集进行分组,然后找到每种产品的订单数如下:
df.groupby('Product')['Quantity Ordered'].sum()
运行代码产量:

让我们看看图表上的输出外观如何更好地理解其提供的见解。
# data
products = [product for product, df in df.groupby('Product')]
quantity_ordered = df.groupby('Product')['Quantity Ordered'].sum().values
# plot
fig, ax = plt.subplots(figsize=(12, 6))
ax = plt.bar(products, quantity_ordered)
plt.xticks(products, rotation=90)
plt.title('Number of Orders per Product', pad=20)
plt.ylabel('Quantity Ordered', labelpad=20)
plt.xlabel('Product', labelpad=20)
plt.grid(False)
plt.savefig('plots/quantity_ordered_product.png', dpi=600, bbox_inches='tight')
plt.show()
代码块的输出应像下面的图表:

该图表表明 AAA电池(4件件) 是技术商店在数据的12个月期间售出的产品。
结论
数据分析是业务分析的骨干。如我们所见,Python是数据分析师武器库中的重要工具。最重要的是,您必须能够以读者可以使用图表轻松理解的方式从数据中展示洞察力。