如果您喜欢Postgres,则不需要告诉我 me 为什么。它是完全开源的,但是由于其坚固的基础和越来越多的令人愉悦的功能,它已成为应用程序数据库的绝对首选选择。但是,当涉及到数据仓库时,在企业中,您会很快开始推动其极限...所以也许您已经变得有点... 云心疑。
没关系。不要感到难过!实际上,让我们通过潜入我当前选择的云数据仓库中的底漆来探索这些感觉: Snowflake 。我们将从高空的视野开始,然后缩小接下来的细节,因为我认为当您了解大局时,这些细节都会变得更加有意义。
目录:
建筑
让我们回顾一下典型的Postgres或其他关系OLTP数据库管理系统的构建方式。您有一台大型机器,它附有一个巨大的存储阵列(可能在您的SAN上),大量的RAM和处理器更多的处理器,甚至比我们当中最大的ho积者在其“旧PC零件”盒中都有他们的壁橱。所有工作都通过这一台服务器,尽管您可能已经设置了读取复制品来处理报告负载,但仍然存在无法分发数据库的最终限制。
Snowflake是新的DBMSES的一部分,通过将存储与COMPUTE分开的关键步骤,从而使自己能够赋予自己能力。这意味着所有实际查询执行都是通过在实际存储介质上方抽象的层中运行的临时服务器来完成的,在雪花的情况下,该介质是云(AWS,Azure或GCP)存储。正如您可能猜到的那样,好处是您可以无限地缩放该计算图层。唯一的限制是您的钱包!
注意:Ottertune在2022年有一篇很棒的文章回顾数据库开发,而分离存储和计算是新进入者的一个重要主题。 Google甚至最近发布了AlloyDB,这是一个修改后的PostgreSQL,它采取了将存储与计算分开的相同步骤,因此,如果它符合您的需求,也许值得一看。但是,嘿,这篇文章仍然与雪花有关!
考虑到这一点,可以将架构分为大约三层,我想考虑到以下内容:
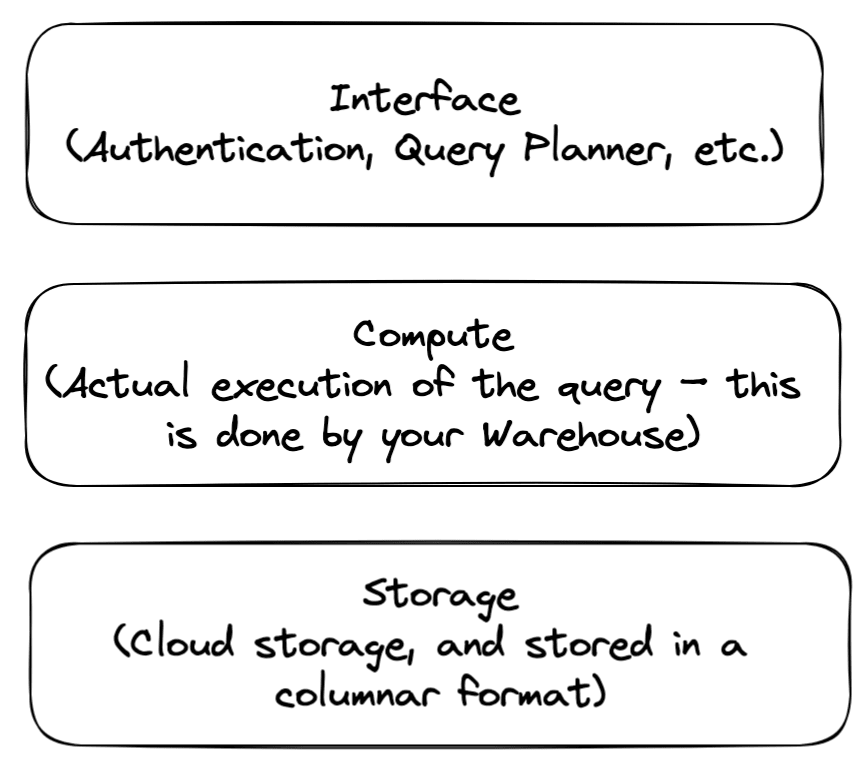
接口层
Snowflake称其为“云服务”层,但我不喜欢该名称,因此我将其视为接口。它提供了SQL界面,该接口会涉及您的查询,计划执行并进行执行。它们都在私人云中以及其他雪花的组件中运行,与其他Snowflake客户分开。
计算层
查询执行是在雪花所指的仓库内完成的。这些代表计算能力,截至今天,从 x-small (1个学分/小时)到 6倍 (512个学分/小时)。顺便说一句,积分取决于您的定价计划。
可以将仓库配置为全职运行,但默认情况下将根据活动自动求和和恢复。
应该直观的是,使用较大的仓库尺寸将使您的查询更快,以付出问题的经典传统。就像在Postgres中一样,通常还有其他方法可以更快地进行查询!
存储层
在Postgres和其他RDBMSES中,表的数据以基于行的格式存储,与巨型CSV没有什么不同。为了加快查询的速度,您可以创建索引,以帮助Postgres快速找到您感兴趣的行。
雪花完全不同。它是 columnar 数据库,这意味着它以基于列的格式存储数据。为了使用类比,将图片产品存储在物理仓库中。在Postgres模型下,您有大量的板条箱(行),每个板条箱中都有一套完整的项目(列)。叉车检索板条箱后,您将获得该板条箱中的所有物品。
但是,在雪花模型下,想象所有按类型分类并以自己的专用部分存储的所有不同项目。仅检索一种类型的项目(一列)将比检索所有类型的项目快得多。
语言差异
好吧,我认为这是足够的高级体系结构。让我们看一下 snowflake sql 和 postgres sql 。
句法
作为Postgres情人,Snowflake SQL对您来说不会是没有问题的:它基于ANSI SQL标准,并且支持您所有通常的查询语法。但是您可能会遇到一些区别。
跨数据库参考实际上有效
Postgres实际上确实让您写出对数据库(mydb.schema.table)指定的对象的引用,但是如果您实际尝试在连接的数据库中使用未使用的内容,它将告诉您cross-database references are not implemented。
雪花不仅允许交叉数据库参考,而且积极鼓励它们。从功能上讲,差异主要是在治理层(您可以在每个数据库级别设置RBAC),因为无论如何数据都“在云中”。尽管如此,要知道这是一件非常重要的事情。
USE语句
遵循上述内容,您可能需要设置“当前”数据库。这与运行USE db_name;一样简单。这是一个连接本地设置,因此如果您重新连接,它将不会持续。
没有SEARCH_PATH-相反,USE SCHEMA
如果您一直不在public中,那么您可能会习惯在Postgres中运行SET SEARCH_PATH = 'myschema';。这不是雪花中的事情,但是您可以使用USE SCHEMA myschema设置当前的模式。但是,与SEARCH_PATH不同,这不能采用多个模式名称。
汇总功能后无FILTER
您是否在Postgres中经历了FILTER的喜悦?不?看!
SELECT
date,
SUM(amount) FILTER (status = 'complete') AS total_completed,
SUM(amount) FILTER (status = 'pending') AS total_pending
FROM orders GROUP BY 1;
但抑制了您的喜悦,因为雪花不支持该语法。相反,返回到久经考验的SUM(CASE):
SELECT
date,
SUM(CASE WHEN status = 'completed' THEN amount ELSE 0 END)
AS total_completed,
SUM(CASE WHEN status = 'pending' THEN amount ELSE 0 END)
AS total_pending
FROM orders GROUP BY 1;
没有DISTINCT ONð
koude13是Postgres中非常整洁的功能,它使您可以执行一个非常常见的任务,即希望将行匹配到某些列 而不必担心其他列会发生什么。也就是说,您肯定会熟悉GROUP BY,但是GROUP BY的要求很烦人,您可以清楚地知道如何从非组列中汇总值。有时候我不在乎,伙计!因此,Postgres让您这样做:
SELECT DISTINCT ON (unique_value)
unique_value, other_datapoint, corollary_val
FROM my_table
ORDER BY unique_value, other_datapoint, corollary_val;
在雪花中,您可以访问QUALIFY条款,该条款使您可以获得相同的最终结果:
SELECT unique_value, other_datapoint, corollary_val
FROM my_table
QUALIFY row_number() OVER (PARTITION BY unique_value ORDER BY unique_value, other_datapoint, corollary_val) = 1;
横向联接查询不能使用ORDER BY ... LIMIT
曾经在Postgres中运行过这样的查询?
SELECT * FROM orders o
JOIN LATERAL (
SELECT * FROM orders WHERE customer_id = o.customer_id
ORDER BY created_at DESC LIMIT 1
) latest_order
这个想法非常简单:将每个订单与客户的最新订单一起拉。如果您不熟悉横向连接,它们允许您的加入表达式是每行特定的子查询。但是雪花将拒绝执行此操作:
Unsupported subquery type cannot be evaluated
有帮助,对吗?问题是,正如我们在下面的那样,雪花中的ORDER BY ... LIMIT查询真的很慢, ,每行不得不运行一行(横向连接确实)绝对会谋杀到雪花甚至不允许您加载特定的脚枪的地步。
数据类型比较
这是映射到其最接近的雪花等效物的Postgres数据类型的摘要:
| Postgres数据类型 | 雪花数据类型 | 注释 |
|---|---|---|
| bigint | bigint | |
| bigserial | bigint | |
| 位 | 二进制 | |
| varbit | varbinary | 等效于二进制 |
| 布尔 | 布尔 | 仅支持2016年1月25日之后提供的帐户。怪异! |
| 盒子 | 几何 | |
| bytea | 二进制 | |
| char | char | |
| varchar | varchar | |
| cidr | ||
| 圆圈 | 几何 | |
| date | date | |
| 双 | 双 | |
| inet | ||
| 整数 | 整数 | |
| 间隔 | 我真的很沮丧的雪花没有这种类型。 | |
| JSON | 文本 | 使用变体可能更有用。 |
| JSONB | 变体 | |
| 线 | 几何 | |
| lseg | 几何 | |
| MaAidad | ||
| maAiddr8 | ||
| 钱 | 数字 | ymmv。 |
| 数字 | 数字 | |
| 路径 | 几何 | |
| pg_lsn | 不是邮政,所以...否。 | |
| pg_snapshot | ||
| 点 | 几何 | |
| Polygon | 几何 | |
| 真实 | 真实 | |
| SmallInt | SmallInt | |
| SmallSerial | SmallInt | |
| 序列 | int | |
| 文本 | 文本 | |
| 时间 | 时间 | |
| timetz | 时间 | 小心!雪花的时间只是24小时的时间价值。没有存储或认可时区的概念。 |
| 时间戳 | timestamp_ntz | |
| timestamptz | timestamp_tz | 还有Timestamp_ltz,它存储UTC值但在当前会话的时区中运行...不建议它。 |
| tsquery | ||
| tsvector | ||
| txid_snapshot | ||
| uuid | 文本 | 不是本地类型。 |
| XML | 变体 | 变体是非常酷。 |
没有间隔生存
我喜欢在Postgres中使用间隔类型,并且一直在做这样的事情:
SELECT NOW() - INTERVAL '24 HOURS';
这在雪花上不起作用,因此您必须还原到Dateadd(MS SQL Server的粉丝不会发疯):
SELECT DATEADD('HOUR', -24, NOW());
避免的事情
Snowflake的完全不同的体系结构意味着您关于查询执行方式的心理模型可能需要一些扩展。这是雪花新移民犯的常见错误列表(我个人都做了所有这些)。
SELECT * =ðü
还记得我们如何提到雪花是柱子? SELECT *需要为所有列获取数据,而在Postgres中,这不仅仅是一列。请记住,以我们的类比,Postgres将所有列的数据价值存储在一个大箱子中,您的叉车已经在拾取。
但是雪花有不同的仓库部分,每个列 ,因此您的叉车需要进行数十个站点!
这并不意味着您绝对不应该运行SELECT *(也许您的报告确实需要所有数据),但是您应该注意您要雪花做什么。
ORDER BY … LIMIT =ð
这是Postgres中的常见且通常是性能的模式:
SELECT id FROM orders ORDER BY created_at LIMIT 5;
Postgres能够使用索引轻松找到最固有的创建贷款(想想我们仓库中的粘合剂,带有指向正确的过道的方向)。
但是雪花没有索引!由于数据不是由ROW存储的,因此索引无济于事。因此,对于这样的查询,雪花可能需要扫描每个值!
(旁注:雪花很容易做到这一点,这要归功于其分配负载的能力,并且我保证您可以有效地选择您的仓库尺寸,但是男孩会很昂贵)。
但是,雪花实际上非常擅长保留每一列的统计数据,并且将每一列中的所有数据捆绑成标记的小盒子。这使雪花非常擅长处理过滤器。因此,如果您稍微缩小范围,Snowflake的工作变得容易得多:
SELECT id FROM orders
WHERE created_at > current_date - 5
ORDER BY created_at LIMIT 5;
这些详细的统计数据还可以帮助雪花执行可以有效地利用元数据工作的查询,例如:
SELECT MAX(created_at) FROM orders;
选择太大的仓库=ð
尽管它可能只是为了增加仓库的大小即可使查询更快地运行(或在不预定时间内完成),但请确保首先优化,并且仅作为最后的度假胜地。更大的仓库并不便宜。始终从XSMALL开始,并在上进行工作,如果您无法优化查询。
结论
还有更多关于雪花的知识,但我希望本文提供了一个很好的起点。如果您渴望更多的雪花内容,请查看我在using Tasks, Streams, and Python UDFs上的较早文章!