每一次有意识学习的行为都要求愿意对自己的自尊心受伤。这就是为什么幼儿在意识到自己的自我重要性之前,很容易学习。
thomas sasz
动机
a 数据Lakehouse 是一种现代数据架构,将数据湖的可扩展性和灵活性与数据仓库的治理和性能结合在一起。这种方法使组织可以在单个平台中存储和分析大量结构化和非结构化数据,从而实现更有效的数据驱动决策。
为此,我们将建立一个数据湖设施解决方案,用于分析 Elon Musk 使用 minio apache drill 作为查询引擎, Apache Superset 用于可视化和 Apache气流用于编排。本文将带您完成构建和利用此解决方案的过程,以获得见解并做出数据驱动的决策。
然后,我们将使用Docker-Compose轻松部署我们的解决方案。
建筑学
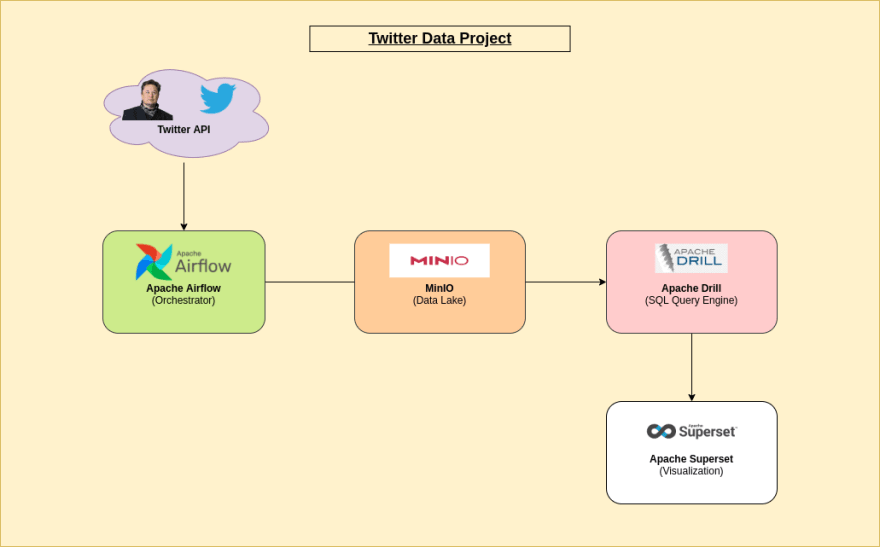
表中的内容
- 什么是Apache气流?
- 什么是Minio?
- 什么是Apache Drill?
- 什么是Apache Superset?
- 代码
- get_twitter_data()
- clean_twitter_data()
- write_to_bucket()
- dag(直接无环图)
- Apache钻头配置
- Apache Superset配置
- docker-compose&.env文件
- 结果
什么是Apache气流
气流是社区创建的平台,以编程作者,计划和监视工作流程。
Apache气流是用Python编写的OpenSource Workflow编排。它使用dag(直接无环图)表示工作流程。它是高度可定制/灵活的,并且拥有一个非常活跃的社区。
ðâ€您可以阅读更多here。
什么是米尼奥
Minio提供高性能,S3兼容对象存储。
Minio是一种OpenSource多云对象存储,并且与AWS S3完全兼容。使用Minio,您可以托管自己的本地或云对象存储。
ðâ€You Ca阅读更多here。
什么是Apache钻头
无模式的SQL查询引擎,用于Hadoop,NoSQL和云存储。
Minio是一种OpenSource多云对象存储,并且与AWS S3完全兼容。使用Minio,您可以托管自己的本地或云对象存储。
ðâ€You Ca阅读更多here。
什么是apache超集
Apache Superset是现代数据探索和可视化平台。
超集集是快速,轻巧,直观的,并且装有选项,使所有技能的用户都可以轻松探索和可视化数据,从简单的线图到高度详细的地理空间图。
。ðâ€You Ca阅读更多here。
代码
可以在此处访问完整代码:
源代码:
https://github.com/mikekenneth/twitter_data-lakehouse_minio_drill_superset
get_twitter_data()
以下是Python任务,将Elon的推文从Twitter API提取到Python列表:
import os
import json
import requests
from airflow.decorators import dag, task
@task
def get_twitter_data():
TWITTER_BEARER_TOKEN = os.getenv("TWITTER_BEARER_TOKEN")
# Get tweets using Twitter API v2 & Bearer Token
BASE_URL = "https://api.twitter.com/2/tweets/search/recent"
USERNAME = "elonmusk"
FIELDS = {"created_at", "lang", "attachments", "public_metrics", "text", "author_id"}
url = f"{BASE_URL}?query=from:{USERNAME}&tweet.fields={','.join(FIELDS)}&expansions=author_id&max_results=50"
response = requests.get(url=url, headers={"Authorization": f"Bearer {TWITTER_BEARER_TOKEN}"})
response = json.loads(response.content)
print(response)
data = response["data"]
includes = response["includes"]
return data, includes
clean_twitter_data()
以下是以正确格式清洁和转换推文的Python任务:
from uuid import uuid4
from datetime import datetime
from airflow.decorators import dag, task
@task
def clean_twitter_data(tweets_data):
data, includes = tweets_data
batchId = str(uuid4()).replace("-", "")
batchDatetime = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# Refine tweets data
tweet_list = []
for tweet in data:
refined_tweet = {
"tweet_id": tweet["id"],
"username": includes["users"][0]["username"], # Get username from the included data
"user_id": tweet["author_id"],
"text": tweet["text"],
"like_count": tweet["public_metrics"]["like_count"],
"retweet_count": tweet["public_metrics"]["retweet_count"],
"created_at": tweet["created_at"],
"batchID": batchId,
"batchDatetime": batchDatetime,
}
tweet_list.append(refined_tweet)
return tweet_list, batchDatetime, batchId
dump_data_to_bucket()
以下是Python任务将推文列表转换为Pandas数据框架,然后将其写入我们的Minio Object Storage中,作为Parquet文件。
import os
from airflow.decorators import dag, task
@task
def write_to_bucket(data):
tweet_list, batchDatetime_str, batchId = data
batchDatetime = datetime.strptime(batchDatetime_str, "%Y-%m-%d %H:%M:%S")
import pandas as pd
from minio import Minio
from io import BytesIO
MINIO_BUCKET_NAME = os.getenv("MINIO_BUCKET_NAME")
MINIO_ROOT_USER = os.getenv("MINIO_ROOT_USER")
MINIO_ROOT_PASSWORD = os.getenv("MINIO_ROOT_PASSWORD")
df = pd.DataFrame(tweet_list)
file_data = df.to_parquet(index=False)
client = Minio("minio:9000", access_key=MINIO_ROOT_USER, secret_key=MINIO_ROOT_PASSWORD, secure=False)
# Make MINIO_BUCKET_NAME if not exist.
found = client.bucket_exists(MINIO_BUCKET_NAME)
if not found:
client.make_bucket(MINIO_BUCKET_NAME)
else:
print(f"Bucket '{MINIO_BUCKET_NAME}' already exists!")
# Put parquet data in the bucket
filename = (
f"tweets/{batchDatetime.strftime('%Y/%m/%d')}/elon_tweets_{batchDatetime.strftime('%H%M%S')}_{batchId}.parquet"
)
client.put_object(
MINIO_BUCKET_NAME, filename, data=BytesIO(file_data), length=len(file_data), content_type="application/csv"
)
DAG(直接无环图)
以下是允许指定任务之间的依赖项的DAG本身:
from datetime import datetime
from airflow.decorators import dag, task
@dag(
schedule="0 * * * *",
start_date=datetime(2023, 1, 10),
catchup=False,
tags=["twitter", "etl"],
)
def twitter_etl():
raw_data = get_twitter_data()
cleaned_data = clean_twitter_data(raw_data)
write_to_bucket(cleaned_data)
twitter_etl()
Apache钻头配置
-
要授予Apache Drill访问我们的Minio(S3)存储桶,我们需要定义钻头
core-site.xml文件中的访问键:
<?xml version="1.0" encoding="UTF-8" ?> <configuration> <property> <name>fs.s3a.access.key</name> <value>minioadmin</value> </property> <property> <name>fs.s3a.secret.key</name> <value>minioadmin</value> </property> <property> <name>fs.s3a.endpoint</name> <value>http://minio:9000</value> </property> <property> <name>fs.s3a.connection.ssl.enabled</name> <value>false</value> </property> <property> <name>fs.s3a.path.style.access</name> <value>true</value> </property> </configuration> -
接下来,我们将配置S3存储插件以指定
storage-plugins-override.conf文件中Apache Drill访问的存储桶:
"storage": { s3: { type: "file", connection: "s3a://twitter-data", workspaces: { "root": { "location": "/", "writable": false, "defaultInputFormat": null, "allowAccessOutsideWorkspace": false } }, formats: { "parquet": { "type": "parquet" }, "csv" : { "type" : "text", "extensions" : [ "csv" ] } }, enabled: true } }
ðâ€您可以阅读更多here。
Apache Superset配置
要查询Apache-Drill,我们需要使用superset_drill.Dockerfile:
构建 koude4 的自定义图像
FROM apache/superset
# Switching to root to install the required packages
USER root
# install requirements for Apache Drill
RUN pip install sqlalchemy-drill
# Switching back to using the `superset` user
USER superset
ðâ€您可以阅读更多here。
docker-compose&.env文件
下面是we need to create容纳运行我们管道所需的环境变量的.env文件:
ðâ€您可以阅读this来学习我们生成TWITTER_BEARER_TOKEN。
# Twitter
TWITTER_BEARER_TOKEN="TOKEN"
# Minio
MINIO_ROOT_USER=minioadmin
MINIO_ROOT_PASSWORD=minioadmin
MINIO_BUCKET_NAME='twitter-data'
# Superset
SUPERSET_USERNAME=admin
SUPERSET_PASSWORD=admin
# Apache Airflow
## Meta-Database
POSTGRES_USER=airflow
POSTGRES_PASSWORD=airflow
POSTGRES_DB=airflow
## Airflow Core
AIRFLOW__CORE__FERNET_KEY=''
AIRFLOW__CORE__EXECUTOR=LocalExecutor
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION=True
AIRFLOW__CORE__LOAD_EXAMPLES=False
AIRFLOW_UID=50000
AIRFLOW_GID=0
## Backend DB
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN=postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__DATABASE__LOAD_DEFAULT_CONNECTIONS=False
## Airflow Init
_AIRFLOW_DB_UPGRADE=True
_AIRFLOW_WWW_USER_CREATE=True
_AIRFLOW_WWW_USER_USERNAME=airflow
_AIRFLOW_WWW_USER_PASSWORD=airflow
_PIP_ADDITIONAL_REQUIREMENTS= "minio pandas requests"
及以下是docker-compose.yaml文件,允许我们的管道旋转所需的基础架构:
version: '3.4'
x-common:
&common
image: apache/airflow:2.5.0
user: "${AIRFLOW_UID}:0"
env_file:
- .env
volumes:
- ./app/dags:/opt/airflow/dags
- ./app/logs:/opt/airflow/logs
x-depends-on:
&depends-on
depends_on:
postgres:
condition: service_healthy
airflow-init:
condition: service_completed_successfully
services:
minio:
image: minio/minio:latest
ports:
- '9000:9000'
- '9090:9090'
volumes:
- './data:/data'
env_file:
- .env
command: server --console-address ":9090" /data
healthcheck:
test:
[
"CMD",
"curl",
"-f",
"http://localhost:9000/minio/health/live"
]
interval: 30s
timeout: 20s
retries: 3
drill:
env_file:
- .env
image: apache/drill:latest
ports:
- '8047:8047'
- '31010:31010'
volumes:
# If needed, override default settings
- ./conf/drill/core-site.xml:/opt/drill/conf/core-site.xml
# Register default storage plugins
- ./conf/drill/storage-plugins-override.conf:/opt/drill/conf/storage-plugins-override.conf
stdin_open: true
tty: true
superset_drill:
env_file:
- .env
ports:
- '8088:8088'
build:
context: .
dockerfile: superset_drill.Dockerfile
volumes:
- ./superset.db:/app/superset_home/superset.db
postgres:
image: postgres:13
container_name: postgres
ports:
- "5433:5432"
healthcheck:
test: [ "CMD", "pg_isready", "-U", "airflow" ]
interval: 5s
retries: 5
env_file:
- .env
scheduler:
<<: *common
<<: *depends-on
container_name: airflow-scheduler
command: scheduler
restart: on-failure
ports:
- "8793:8793"
webserver:
<<: *common
<<: *depends-on
container_name: airflow-webserver
restart: always
command: webserver
ports:
- "8080:8080"
healthcheck:
test:
[
"CMD",
"curl",
"--fail",
"http://localhost:8080/health"
]
interval: 30s
timeout: 30s
retries: 5
airflow-init:
<<: *common
container_name: airflow-init
entrypoint: /bin/bash
command:
- -c
- |
mkdir -p /sources/logs /sources/dags
chown -R "${AIRFLOW_UID}:0" /sources/{logs,dags}
exec /entrypoint airflow version
结果
-
当我们访问Apache-Airflow Web UI时,我们可以看到DAG,并且可以直接运行以查看结果。
DAG(Apache-Airflow Web UI):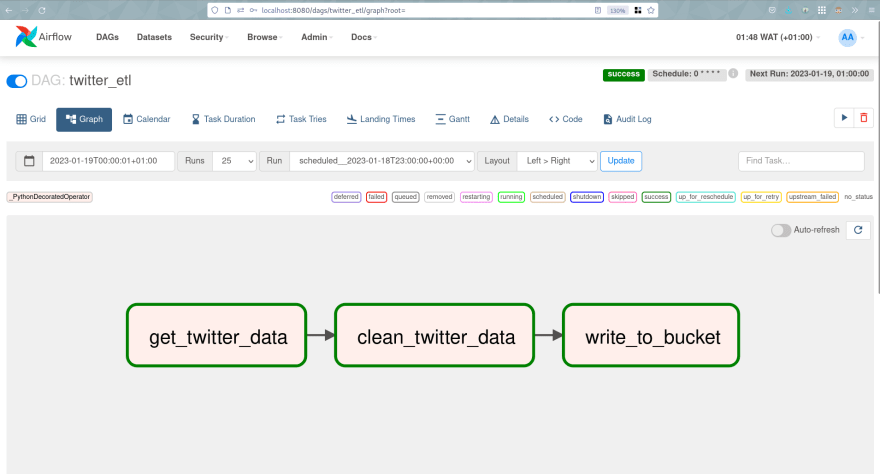
-
在我们的存储桶(Minio Console)中生成的Tweets Parquet文件:

-
如果需要,我们可以使用Apache-Drill Web界面直接查询 Data-Lakehouse :
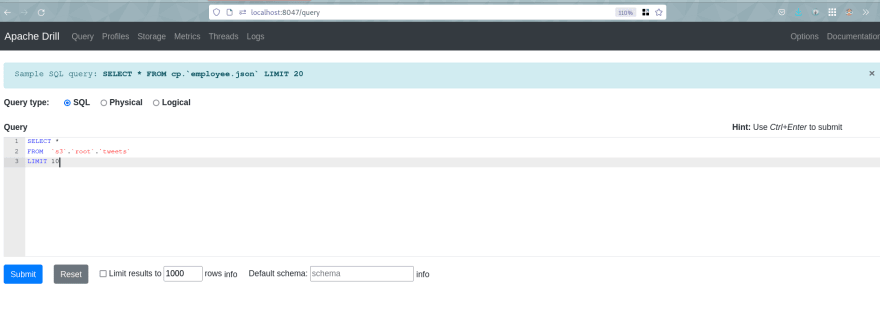
-
最后,我们可以可视化仪表板(我已经构建了它,但是可以轻松修改它,并且数据存储在
superset.db文件中):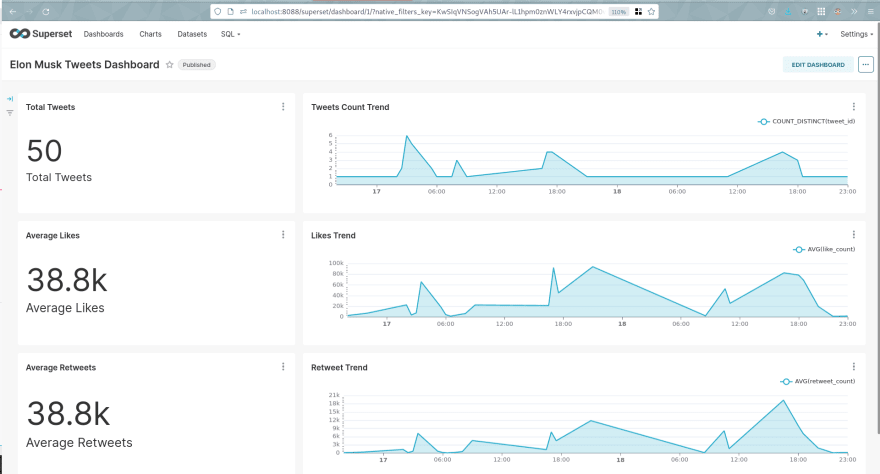
这是一个包裹。我希望这对您有帮助。
关于我
我是一名数据工程师,拥有3年以上的经验,并且是软件工程师(5年以上)。我喜欢学习和教学(主要是学习ð)。
您可以通过Twitter和LinkedIn或 mike.kenneth47@gmail.com 与我联系。