在我们深入研究AWS的不同数据库产品之前,让我们快速了解数据的管理和存储方式(关系与非关系)和不同用例的差异 - 操作/交易(OLTP)与分析(分析)( OLAP))
| 关系 | 非关系 |
|---|---|
| 表,行和列 | 许多不同的数据存储模型(键值对,文档或图形) |
| 刚性模式(SQL) | 灵活模式(NOSQL) |
| 数据库中强制执行的规则 | 在应用程序代码中定义 |
| 垂直可伸缩性 | 水平 |
| 支持加入和复杂查询 | 非结构化简单查询语言 |
| OLTP(在线交易处理) | olap(在线分析处理 |
|---|---|
| 面向交易的任务 | 分析和决策的任务 |
| OLTP通常涉及在数据库中插入,更新和/或删除少量数据 | OLAP对业务数据进行多维分析,并为复杂数据建模 | 提供了功能
| 简短的交易和简单查询 | 长交易和复杂查询 |
| IE生产DB | IE Data-Warehouse |

OLAP中的数据通常来自多个OLTP来源(汇总)。

OLAP数据软件有助于避免在原始源上的性能打击,但是,对于非常简单的方案,具有读取副本将可以完成工作。
与许多其他服务一样,AWS为我们提供了非常广泛的数据存储产品,以适合不同要求,可伸缩性,性能和价格。
- Amazon RDS(OLTP)
- dynamodb(oltp)
- documentdb
- 红移(OLAP)
- Elasticache
- emr(hadoop)(olap)
- EC2上的数据库(上面未列出的其他数据库可以直接安装在EC2上)
亚马逊RDS
Amazon RDS是一项由AWS管理的服务,允许您使用流行的开源和商业数据库引擎在AWS云中自动安装和提供关系数据库:
- mysql
- Microsoft SQL Server
- Oracle
- PostgreSQL
- Mariadb 和
- Amazon Aurora是MySQL和PostgreSQL兼容数据库,该数据库为云由AWS构建。
使用RDS旋转新数据库时,AWS将负责所有典型的管理任务(供应,安全性,高可用性,备份,备份,修补和更新次要版本)。
可伸缩性
使用Aurora RDS,我们可以通过增加实例类型的大小来垂直扩展。
水平缩放仅适用于使用RDS读取副本的读取 /查询。< / p>
是从您主实例中创建的读取副本,然后保持更新异步。只读流量可以直接转移到读取副本以卸载主数据库,然后只照顾写信。

在 Multi Az 部署的情况下,待机实例是与主要区域一起创建的。
备用实例不是一个简单的读取副本,因为复制发生了同步。
在发生故障的情况下,可以将复制品升级为主要,但这不会自动发生。
Multiaz部署提供自动故障转移(写入和读取会自动重定向),因此建议使用 灾难恢复 。
加密
可以在休息处进行加密(在创建过程中配置)
也可以加密连接。
加密使用kms。
您不能拥有未加密DB的加密复制品,同样,您可以拥有加密db的未加密复制品。
备份和恢复选项
每天执行自动备份,并具有保留期(最大35天),可用于还原和创建 new 数据库。
手动(按需)备份称为快照,没有保留期(它们不到期,必须手动删除)。他们备份整个DB实例,不仅是单个DB,并且在单个AZ(从几秒钟到几分钟)的情况下可能导致I/O的暂停。
如果是多动物,则没有打ic(除了SQLServer以外),因为备份是从Standyby实例中获取的。
快照可以从RDS出口到S3,并允许与雅典娜,萨格人或EMR等其他工具进行进一步分析。
您可以选择简单地导出特定数据库,表或模式。
极光
Aurora是RDS家族中的数据库产品,与PostgreSQL和MySQL兼容,为云构建,因此更快。
它是分布的,自我修复,容错的(在3个AZ 上具有6种方法复制),每个实例的自动体最多为128TB。
可以使用多达15个读取副本(在同一区域)的多个AZ上配置单个主实例。
在失败的情况下,可以将读取副本晋升为主的角色,并允许在约60秒内重新启动(故障转移选项)。
跨区域副本量表从MySQL数据库引擎 - (仅适用于Aurora mysql),遍及逻辑异步复制区域读取操作 - 主。
全局数据库功能允许跨区域 cluster 读取缩放(从Aurora存储层中复制物理异步复制 ) - 这意味着它跨越多个区域,以供低潜伏期全球读取和灾难恢复。 (可用于MySQL和Postgres)
Multi Master 特征在区域内的写入(也仅适用于MySQL) - 这意味着它在跨AZS的写入一致性后提供了读取。如果一个AZ中的中断,所有DB写入将自动重定向到另一个实例,而无需执行故障转移。
您可以通过4种方式连接到Aurora:
- 群集端点:将执行对主实例的读写访问。
- 读取器端点:读取复制品舰队的负载平衡连接。
- 自定义端点:加载余额在您注册的一组实例上连接,并且要用于特定角色或任务。
- 实例端点:群集中的每个实例,包括您的主要和读取副本实例,每个实例都将拥有自己的独特实例端点,可以指向自身。出于负载平衡原因有用。
Aurora无服务器
- 无缝缩放容量
- 应用程序通过routerfleet连接。
- acus(Aurora容量单元)是每个2GB的内存。
Aurora Serverless配置了单个连接端点(您没有写入和副本端点的端点,因为它是无服务器的,并且会自动缩放)
>这是
的理想选择- 不经常使用的应用程序
- 用法所在的新应用程序 - 尚不知道或可预测
- 非常可变的工作负载
RDS代理
完全托管的数据库代理,当无服务器应用程序访问RDS时,它会共享不经常使用的连接(因为它创建了连接池)并提高了降低CPU/内存的效率压力。
它还控制身份验证方法。
当不使用RDS时
在某些用例中,采用RD可能证明是对抗的。
- 如果关键/值数据结构或数据结构是不可预测的,或者尚未确定的,并且当自动可伸缩性是必需的时 - > dynamoDB更合适。
- 在大型二进制对象的情况下 - > S3 可能是一个更好的选择。
- 如果其他数据库平台(例如IBM DB2或SAP HANA )或如果您需要root Access ,则EC2将是解决方案。 由于RDS是托管服务,因此您无法访问OS,因此您无法安装诸如管理工具之类的软件,如果这是您的要求,EC2将为您提供更大的控制DB和基础服务器OS ,但是您必须自己管理一切(备份,冗余,扩展 - 以及我们上面已经看到的所有管理任务)。
RDS购买选项
- 按需
- 保留实例
- 无服务器
- BYOL(携带您自己的许可证) - 仅适用于Oracle DB,均用于按需或保留实例
可以在几分钟内随时启动按需实例。
价格取决于实例类型。如果进行多AZ部署,您将付出额外费用(通常是两倍)。
使用无服务器,没有实例可以管理,因此定价以ACUS(Aurora容量单元:2GB的内存)每小时测量。
保留实例允许您购买一定时间(从1到3年)的实例类型的折扣,并取决于付款方式(所有前期,局部,部分上游,无上游)可以进一步减少。
存储和I/O的定价在不同的DB发动机上有所不同,也必须考虑。
Aurora使用A 共享群集存储架构,而所有其他DB类型都使用 ebs(Elastic Block Store)
您可以检查我的previous post about EBS以找出不同的存储选项及其定价。
在Aurora和共享群集存储架构的情况下,您无法配置任何存储选项,因为它将自动为您管理,这就是为什么定价指标在GB月中 + I/OS的数量处理(每百万要求计费)
DynamoDB
这是一个完全管理的示意性NOSQL数据库服务。
非关系,密钥/价值和文档存储
它有四个9s。 (99.99%)可用性(5个全球表格)
数据会自动在单个区域内的3个不同的可用性区域中复制。
- 表
- 项目 - >基本上是一行(最大记录大小为 400kb ) 分区键和排序键组成表中的主要键使用的访问项(两个属性都存在时,主键也称为复合键 - 您还可以指定没有SK的PK) )
- 属性 - >与该项目相关的信息(列)
由于DynamoDB是示意性的,一旦定义了主键的结构(分区和排序键),每个项目/行都可以具有自己的结构。
ttl(timetolive)定义表格中的项目何时到期,并且将自动删除(**无需额外费用,因为它们不使用wcu / rcu)
WCU和RCU(写入和读取容量单元)是每秒读数和写入数量的度量。计费与RCU和 / < / p>不同
备份和还原
按需备份可以安排并在几秒钟内执行,没有影响对桌面性能和可用性的影响 - 它们不会到期。
可以启用第二个时间点恢复到第二个,并允许在当前时间到过去35天之间将表的数据还原到任何状态。将在A 新表上进行在同一区域或其他区域上进行。
发电机索引
dynamoDB使您可以创建其他索引,以便可以运行查询以通过其他属性搜索数据,但是请记住, dynamo索引的工作方式与关系数据库中的数据差异很大(并且您必须运行您的运行方式对该索引的查询)。
辅助索引可以是本地的(与单个分区密钥相关)或全局(让您在整个表中查询)。
DynamoDB流
每当从DynamoDB表中插入/更新/删除项目时,写入流到流并存储长达24小时的记录。
流允许捕获项目级修改的时序序列
根据您的用例,您可以定义要将哪些数据放入流中:
- 键
- 新图像
- 旧图像
- 旧图像和新图像(含义修改之前和之后的整个属性)
全局表
dynamoDB以跨区域复制的形式提供辅助层(全局表)
使用全局表,dynamoDB变为多主机数据库和
数据在位于不同区域的表中复制了异步(通过当您创建全局表时自动创建的DynamoDB流),每个表都包含相同的数据集(不像具有具有的Memcached节点数据的不同分区)。
除了增加区域停电的情况外,全局表还会降低延迟,因为您的用户将从最接近的表副本(数据局部性)访问数据)
DynamoDB加速器(DAX)
dax(完全管理的内存中缓存,可以提高从毫秒到 _micro_second 延迟的性能。
提高读写性能。
dax是针对DynamoDB进行了优化的,并且不需要代码中的更改,因为它只是将其放在Dynamo DB面前,您的要求只需指向此处即可。
如果发生Elasticache,则有更多的管理开销(例如缓存无效)。
dax是DynamoDB的独立实体,并将其放置在VPC中。
Amazon Elasticache
是密钥/值存储在内存数据库,以及Redis和Memcached的托管实现。
一个非常常见的用例是将其放在RDS或DynamoDB面前,以提高性能并减少延迟
有益:
- 不经常更改但经常访问的数据
- 可以容忍陈旧数据的应用
- 数据被原始源而不是缓存检索时会更昂贵和较慢的数据
- Elasticache通常用于存储会话状态(DynamoDB的替代方案)
一些示例是WebSesses商店,用于卸载DB的流行查询数据库缓存,排行榜和流数据仪表板。
除了缓存之外,内存数据层也可用于分析和建议引擎。
,由于弹性气节点在EC2计费上运行时是基于实例类型的,因此它们被配备时。
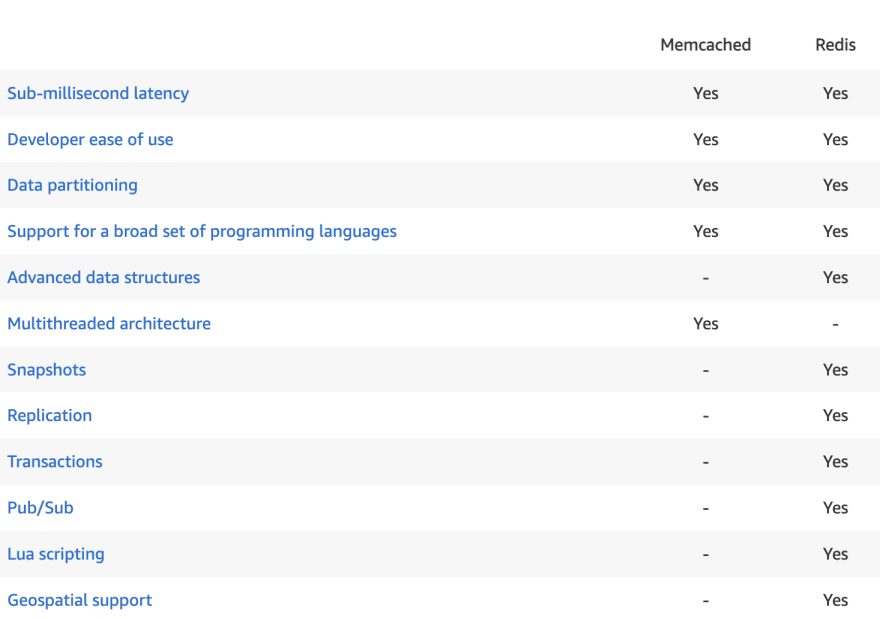
纪念与Redis
memcached是内存的密钥存储,它是多线程和支持分区(可以用作数据存储之外的缓存)
另一方面,REDIS不仅仅是一个缓存层,因为它支持更高级的数据结构,提供数据持久性,加密和复制(这是纯粹是内存的数据存储)。
两者都具有高毫米潜伏期的高性能。
Elasticache可伸缩性:
节点是安全网络连接的RAM的固定尺寸块。
节点可以使用不同的实例类型启动。更改实例类型允许垂直缩放。
由于模因和redis的不同性质,Elasticache对它们进行了不同的管理。
shard(redis)是一组最多6个Elasticache节点
群集(REDIS)是1组(禁用群集模式)或在单个或多个可用性区域中最多90个redis shards(启用群集模式时)。
数据在该集群中的所有碎片中分区。
启用了群集模式,您可以拥有多个碎片(在相同或跨不同的可用性区域内),其中主节点和零至5副本。
启用了群集模式,您还可以在线或离线resharding
- 在线重新设备您可以添加或删除碎片 您可以通过添加新的副本 水平扩展
群集(模因)是一个或多个节点的集合。 Amazon Elasticache自动检测并替换失败的节点。
通过将节点添加到群集中水平缩放。
为了提高容差,请在集群的AWS区域内找到跨多个可用性区域(AZS)的模因节点(但请记住,每个节点都是数据的分区,并且没有副本也没有备份)。
其他数据库服务
DocumentDB
DocumentDB是一个完全管理的非关系文档数据库,具有完整的mongoDB兼容性,这意味着它对JSON数据非常有用,它可以自动扩展到64TB。
。- 集群端点 - 对于需要读写和写入数据库的应用程序
- 阅读器端点:用于连接以读取副本
- 实例端点:群集中的每个实例,包括您的主要和读取副本实例,每个实例都将拥有自己的独特实例端点,可以指向自身。出于负载平衡原因有用。
钥匙空间(用于Cassandra)
Keyspaces是可扩展的完全管理的apache cassandra兼容数据库服务(无服务器),它允许您使用CQL(Cassandra Query语言)。
Cassandra是一个免费的开源分布式,宽列商店,NOSQL数据库管理系统。
按键基本上是一组表,表是您写数据的位置。与DynamoDB类似,您可以定义已提供或按需容量模式。
海王星
Neptune是一个完全管理的图形数据库服务,其用例用于欺诈检测,推荐引擎,社交网络和应用使用Gremlin,OpencyPher和Sparql等开源API。
像DocumentDB一样,它具有群集,读取器和实例端点
QLDB
Quantum Ledger Database
QLDB是一个完全管理的,无服务器的分类帐数据库,用于透明不可变和密码验证的交易日志。
数据只能将数据附加(不覆盖或删除)到期刊上,因此,当需要诚信保证时,QLDB很棒。
