监督学习使用培训集来教授模型以产生所需的输出。该培训数据集包括输入和正确的输出,使模型可以随着时间的推移而学习。该算法通过损耗函数来测量其准确性,调整直到误差已充分最小化为止。
当数据挖掘分类和回归时,可以将监督学习分为两种类型的问题:
-
分类使用算法将测试数据准确地分配给特定类别。它识别数据集中的特定实体,并试图就应该如何标记或定义这些实体得出一些结论。常见分类算法是线性分类器,支持向量机(SVM),决策树,K-Nearest邻居和随机森林,在下面更详细地描述。
-
回归用于了解因变量和自变量之间的关系。它通常用于进行预测,例如给定业务的销售收入。线性回归,后勤回归和多项式回归是流行回归算法。
监督学习的工作原理?
在监督学习中,使用标记的数据集对模型进行了培训,该模型在其中了解每种类型的数据。训练过程完成后,根据测试数据(训练集的一个子集)对模型进行测试,然后预测输出。
以下示例和图表可以轻松理解监督学习的工作:
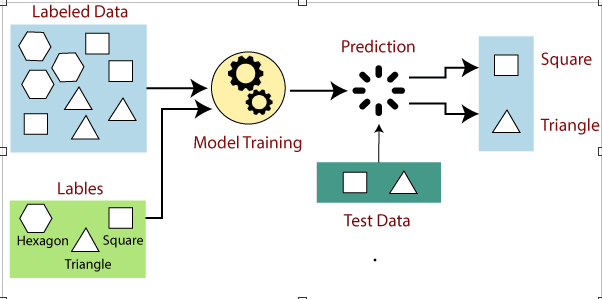
假设我们有一个不同类型形状的数据集,包括正方形,矩形,三角形和多边形。现在的第一步是我们需要为每种形状训练模型。
-
如果给定的形状具有四个侧面,并且所有侧面都相等,则将其标记为 square 。
-
如果给定的形状具有三个侧面,则将其标记为三角形。
-
如果给定的形状具有六个相等的侧面,则将标记为六边形。
现在,经过训练后,我们使用测试集测试了我们的模型,模型的任务是识别形状。
机器已经在所有类型的形状上进行了训练,当它找到新形状时,它会分类多个侧面的形状,并预测输出。
监督机器学习算法的类型:
监督学习可以进一步分为两种类型的问题:
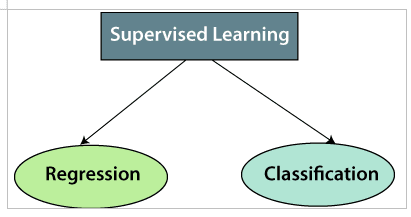
1。回归
如果输入变量和输出变量之间存在关系,则使用回归算法。它用于预测连续变量,例如天气预报,市场趋势等。以下是一些受到监督学习的流行回归算法:
-
线性回归
-
回归树
-
非线性回归
-
贝叶斯线性回归
-
多项式回归
2。分类
分类算法是在输出变量分类时使用的,这意味着有两个类,例如yes-no,男性女性,true-false等。
垃圾邮件过滤,
-
随机森林
-
决策树
-
逻辑回归
-
支持向量机
监督学习的优势:
-
在监督学习的帮助下,该模型可以根据先前的经验预测输出。
-
在监督学习中,我们可以对对象类有一个确切的想法。
-
监督学习模型有助于我们解决各种现实世界中的问题,例如欺诈检测,垃圾邮件过滤等。
监督学习的缺点:
-
监督学习模型不适合处理复杂的任务。
-
如果测试数据与培训数据集不同,则监督学习无法预测正确的输出。
-
培训需要大量计算时间。
-
在监督学习中,我们需要有关对象类别的足够知识。
监督机器学习示例
这是一些有监督的机器学习示例模型,用于不同的业务应用程序:
图像和对象识别
监督的机器学习用于从图像或视频中定位,分类和隔离对象,当应用于不同的图像分析和视觉技术时,这很有用。图像或对象识别的主要目标是准确识别图像。
示例: 我们使用ML准确地识别图像,就好像它是平面或汽车的图像一样,或者图像是猫或狗的图像。
预测分析
监督的机器学习模型被广泛用于构建预测分析系统,该系统可深入了解不同的业务数据点。这使组织能够使用系统给出的输出来预测某些结果。它还可以帮助企业领导者做出改善公司的决策。
示例1:我们可以使用监督的学习来预测房价。数据具有有关房屋大小,价格,房屋中的房间数量,花园和其他功能的详细信息。我们需要有关房屋各种参数的数据,用于数千栋房屋,然后将其用于训练数据。现在可以使用训练有素的监督机器学习模型来预测房屋的价格。
示例2: 垃圾邮件检测是大多数组织使用监督机器学习算法的另一个领域。数据科学家对不同的参数进行分类以区分官方邮件或垃圾邮件邮件。他们使用这些算法来训练数据库,从而使训练有素的数据库识别新数据中的模式并将其分类为垃圾邮件和非垃圾邮件通信。
情感分析
组织可以使用监督的机器学习算法来预测客户的观点。他们使用算法来从大量数据集,意图和背景等大型数据集中提取和分类重要的信息。这种监督学习模型还用于预测文本的情感。此信息对于获得有关客户需求的见解非常有用,并有助于改善品牌客户的参与度。
示例:一些o*诉讼,尤其是电子商务商店,经常尝试通过发布在其应用程序或网站上的产品评论来识别其客户的情感。*
参考:
-
javapoint
-
ibm
-
确实