随着云计算的开发,对象存储的价格低廉和可弹性可扩展空间获得了青睐。越来越多的企业正在将温暖和冷的数据迁移到对象存储。但是,将索引和分析组件直接迁移到对象存储将阻碍查询性能并引起兼容性问题。
本文将详细说明Elasticsearch中的热和冷数据分层的基础,并介绍如何使用Juicefs来应对对象存储上发生的问题。
1 Elasticsearch的数据层架构
在潜入ES如何实现冷冷数据层策略之前,有三个概念要知道:数据流,索引生命周期管理(ILM)和节点角色。
数据流
数据流是ES中的一个重要概念,具有以下特征:
- 流媒体写作。数据流是在流中而不是在块中编写的数据集。
- 仅附加写作。数据流通过附录写入数据,不需要修改现有数据。
- 时间戳。在创建时将给出每个新数据以记录的时间戳。
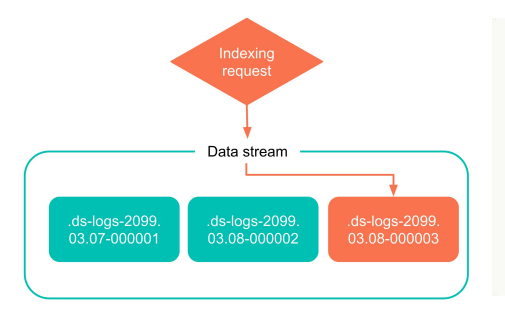
- 多个索引:在ES中,每个数据都位于索引中。数据流是一个较高级别的概念,一个数据流可以由许多索引组成,这些索引是根据不同规则生成的。但是,只有最新的索引是可写的,而历史索引仅阅读。
日志数据是典型的数据蒸汽类型。它是仅附加的,还必须时间戳。用户将通过不同的维度(例如DAY或其他)生成新索引。
以下方案是数据流创建索引的简单示例。在使用数据流的过程中,ES将直接写入最新的索引。随着更多数据的生成,此索引最终将成为旧的,仅阅读的索引。
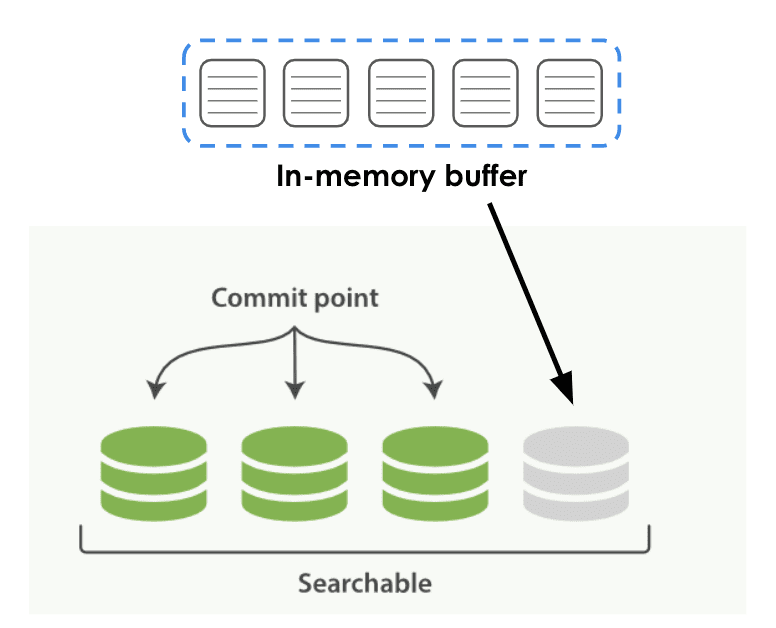
以下图将数据写入ES,包括两个阶段。
- 阶段1:数据首先写入内存缓冲区。
- 阶段2:缓冲区将根据某些规则和时间落在本地磁盘上,该规则和时间在图中显示为绿色(持久数据),称为Es。 中的段
在此过程中可能存在一些时间滞后,如果在持久性过程中触发查询,则无法搜索新创建的段。一旦持续了细分,就可以立即通过高级查询引擎进行搜索。
索引生命周期管理
索引生命周期管理(ILM)是索引的生命周期管理,ILM将索引的生命周期定义为5阶段。
- 热数据:需要经常更新或查询。
- 温暖的数据:不再更新,但仍经常查询。
- 冷数据:不再更新,并且频率较低。
- 冷冻数据:不再更新且几乎没有查询。将这种数据放在相对较低且廉价的存储介质中是安全的。
- 删除数据:不再需要,可以安全删除。 所有ES索引数据最终都将通过这些阶段,用户可以通过设置不同的ILM策略来管理其数据。
节点角色
在ES中,每个部署节点将具有节点角色。不同的角色,例如主,数据,摄入等,将分配给每个ES节点。用户可以将节点角色和上述不同的生命周期阶段组合在一起,以进行数据管理。
数据节点具有不同的阶段,并且可以是存储热数据,热数据,冷数据甚至极冷的数据的节点。节点将根据其任务分配不同的角色,并且有时根据角色将不同的节点配置为不同的硬件。
例如,需要使用高性能CPU或磁盘配置热数据节点,对于具有温暖和冷数据的节点,由于查询这些数据的频率较低,因此硬件的需求不一定很高,对于某些计算资源。
节点角色是基于数据生命周期的不同阶段定义的。这是一个示例,其中node.roles在es yaml文件中配置。您还可以为其应该具有的节点配置多个角色。
node.roles: ["data_hot", "data_content"]
生命周期政策
了解数据流,索引生命周期管理和节点角色的概念之后,您可以自定义数据的生命周期策略。
基于策略中定义的索引特征的不同维度,例如索引的大小,索引中的文档数以及创建索引的时间,ES可以自动帮助用户从一个生命周期到另一个生命周期,在es。
例如,用户可以根据索引的大小来定义功能,并将热数据滚动到热数据,或者根据其他一些规则将热数据滚动到冷数据。 ES可以自动完成工作,而生命周期策略需要由用户定义。
下面的屏幕截图显示了Kibana的管理接口,该接口允许用户以图形方式配置生命周期策略。您可以看到有三个阶段:热数据,热数据和冷数据。
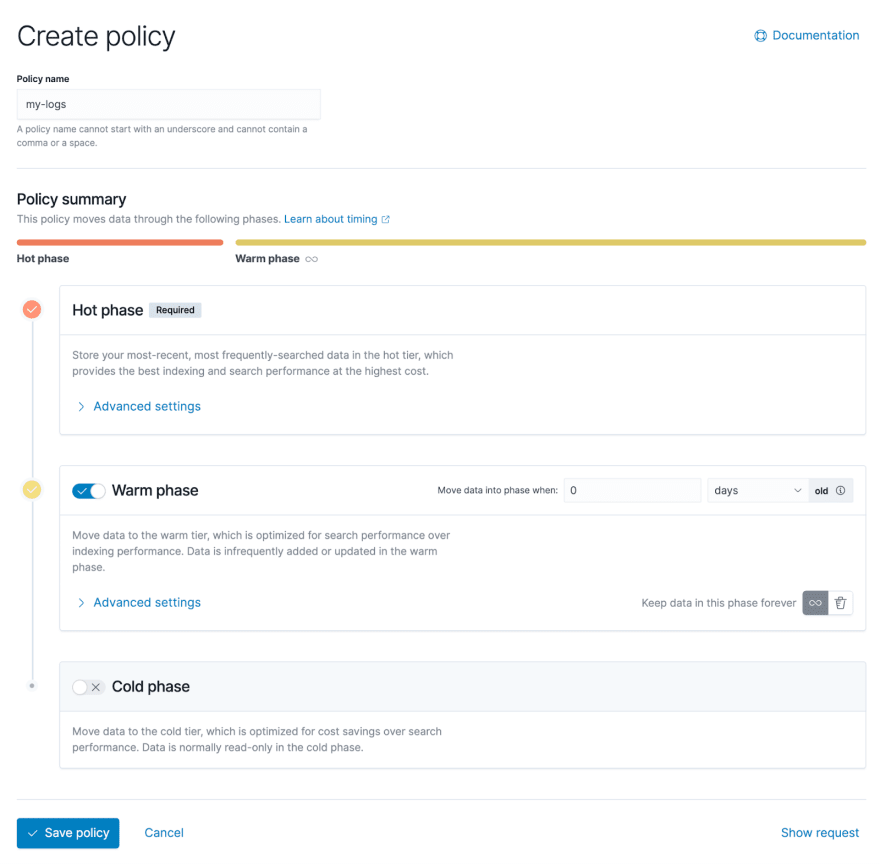
扩展高级设置,您可以根据不同特征查看有关配置策略的更多详细信息,该特征在下面的屏幕截图的右侧列出。
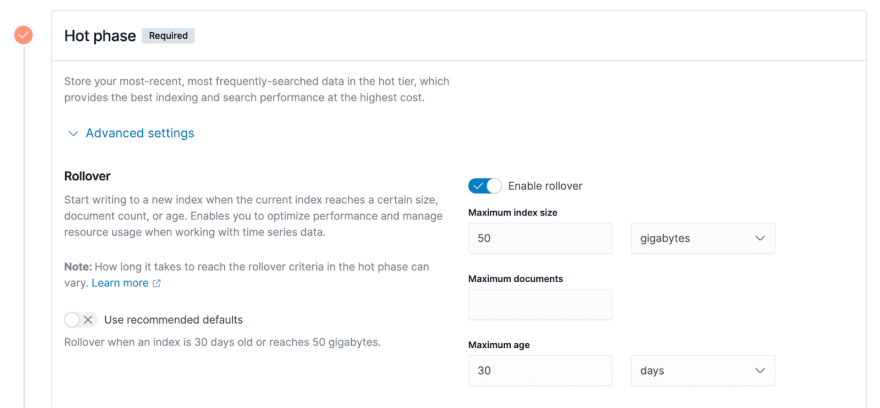
最大索引大小。在上面的屏幕截图中以50 GB的示例为例。这意味着当索引的大小超过50GB时,数据将从热数据阶段滚动到热数据阶段。
。最大文档。 ES索引的基本存储单元是文档,用户数据以文档的形式写入ES。因此,文档的数量是可测量的指标。
最大年龄。作为30天的一个例子,即已经创建了30天的索引,它将触发热数据的滚动到前面提到的温暖数据阶段。
但是,直接在对象存储上使用ElasticSearch可能会导致写入性能和兼容性和其他问题。因此,也希望平衡查询性能的公司开始在云上寻找解决方案。在这种情况下,Juicefs越来越多地用于数据分层体系结构。
2 ES + Juicefs的实践
步骤1:准备多种类型的节点并分配不同的角色。每个ES节点都可以分配不同的角色,例如存储热数据,热数据,冷数据等。用户需要准备不同类型的节点以符合不同角色的需求。
步骤2:安装Juicefs文件系统。通常,用户使用JUICEFS进行温暖和冷数据存储,用户需要将JUICEFS文件系统安装在ES温暖数据节点或冷数据节点上。用户可以通过符号链接或其他方式将安装点配置为ES,以使ES认为其数据存储在本地目录中,但是该目录实际上是JUICEFS文件系统。
步骤3:创建生命周期策略。每个用户都需要通过ES API或通过Kibana自定义这一点,这提供了一些相对简单的方法来创建和管理生命周期策略。
步骤4:为索引设置生命周期策略。创建生命周期策略后,您需要将策略应用于索引,也就是说,您需要设置刚刚为索引创建的策略。您可以使用索引模板来执行此操作,该模板可以在Kibana中创建,也可以通过API通过index.lifycycle.name。
明确配置。这里有一些提示。
提示1:温暖或冷节点的副本(副本)的数量可以设置为1 。所有数据都放在Juicefs上,最终将其上传到基础对象存储中,因此数据的可靠性足够高。因此,可以减少ES侧的副本数量以节省存储空间。
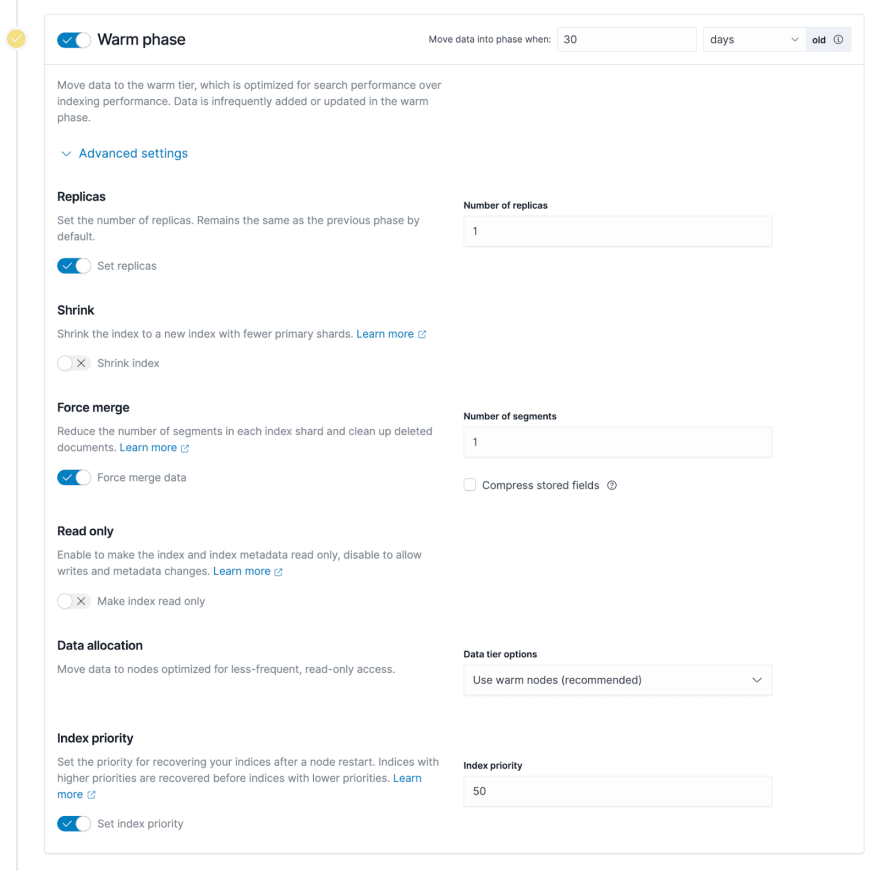
提示2:打开力合并可能会在节点上引起恒定的CPU使用,因此如果适当的话,将其关闭。从热数据到热数据时,ES将合并与热数据指数相对应的所有基础段。如果启用了武力合并,ES将首先合并这些段,然后将它们存储在暖数据的基础系统中。但是,合并段是一个非常消耗CPU的过程。如果热数据的数据节点也需要随附一些查询请求,则可以在适当的情况下关闭此功能,也就是说,保持数据完整并将其直接写入基础存储。
提示3:可以将温暖或冷相的索引设置为只读。在索引温暖和冷的数据阶段时,我们基本上可以假设数据是仅读取的,并且索引将不会被修改。设置仅阅读的索引可以减少在温暖和冷的数据节点上的一些资源使用情况,然后您可以缩小这些节点并节省一些硬件资源。
来自Juicedata/JuiceFSï¼(0á0â0â)