缓存是一个概念,它是从硬件世界赠予软件世界的。缓存是一个临时存储区域,可存储用过的物品,以便于访问。用外行的话说,这是我们所有人都有的椅子。

此博客涵盖
的基础知识- What are Caches?
- Caching Operations
- Cache Eviction Policies
- Implementation of Cache Eviction Policies
- Distributed Caching
- Caching In Python
常规缓存
在计算机科学领域,缓存是存储计算结果的硬件组件,以便于快速访问。有助于速度的主要因素是其内存尺寸及其位置。缓存的内存大小比RAM少。这减少了检索数据的扫描数。缓存位于消费者(CPU)较近的地方,因此延迟较小。
缓存操作
有两种广泛的缓存操作。缓存,例如浏览器缓存,服务器缓存,代理缓存,硬件缓存在read和write Caches的原理下工作。
在处理缓存时,我们总是有大量的内存,这些内存很耗时,读写,db,硬盘等,cache是坐在其顶部的软件/硬件,从而使工作更快。
阅读缓存
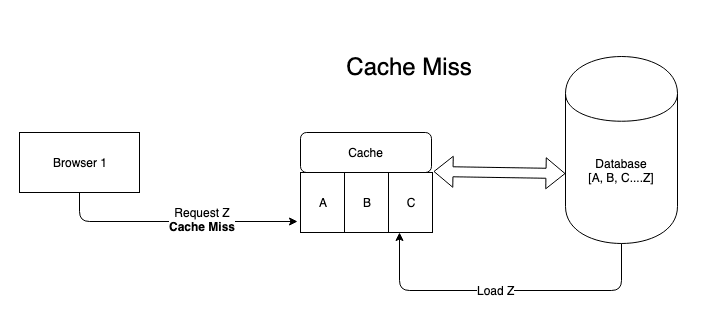
读取缓存是存储访问的项目的存储。每当客户端请求数据中的数据时,请求就会列出与存储相关的缓存。
- 如果请求的数据可在缓存上可用,则是缓存hit 。

- 如果不是,那是缓存MISS 。
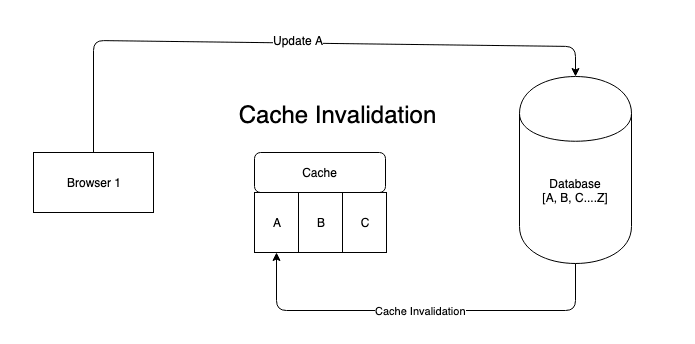
- 现在,当从高速缓存访问数据时,一些其他过程会更改数据,此时您需要使用新更改的数据重新加载缓存,这是缓存无效
写缓存
写缓存的名称建议启用快速写入。想象一个沉重的系统,我们都知道写入DB的代价很高。缓存方便并处理DB写入负载,后来将分批更新为DB。重要的是要注意,DB和缓存之间的数据应始终同步。有3种方法可以实现写入缓存。
- 通过 写
- 写回来
- 写
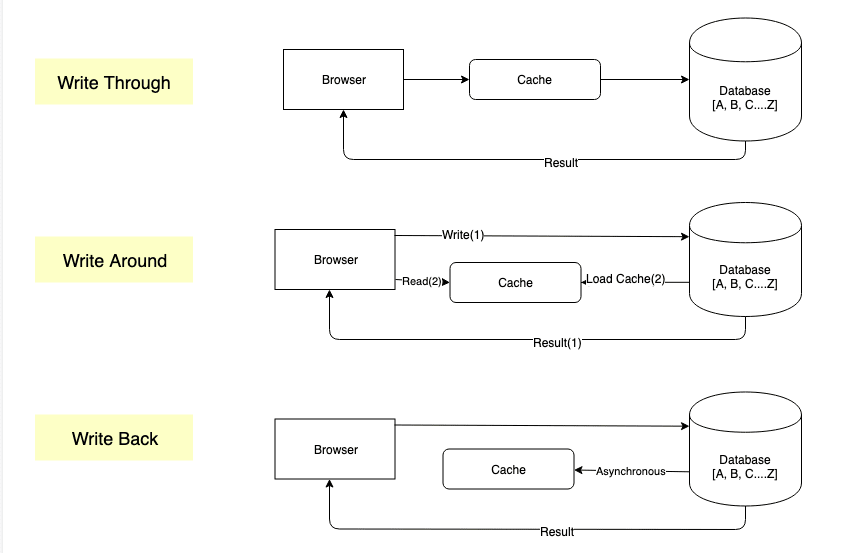
写信
写入数据库的写入通过缓存发生。每次在缓存中写入新数据时,都会在DB中更新。
优点 - 缓存与存储之间的数据不匹配
缺点 - 需要更新缓存和存储空间,而不是增加性能
写回
回报是当缓存异步以设定的间隔将值更新为db时。
此方法通过写入的优势和缺点。尽管写入缓存的速度更快数据丢失和不一致
写作
直接将数据直接写入存储并仅在读取数据时加载缓存。
优点
- 缓存不会被写入后未立即读取的数据
- 减少写入方法的延迟
缺点
- 读取最近的书面数据将导致缓存失误,不适合此类用例。
缓存驱逐政策
缓存进行读取并快速写入。然后,读取和从缓存中读取所有数据而不是使用DBS才有意义。但是,请记住速度仅仅是因为缓存很小。较大的缓存,搜索它需要更长的时间。
因此,重要的是要优化空间。一旦缓存已满,我们只能通过删除已在缓存中删除新数据的空间。同样,这不能是一个猜测游戏,我们需要最大化利用来优化输出。
用于确定需要从缓存中丢弃数据的算法是缓存驱逐策略
- lru-最少使用的
- lfu-最不常用的
- MRU-最近使用的
- fifo-首先是
LRU-最近使用的
顾名思义,当缓存耗尽空间时,请删除least recently used元素。它简单易于实现,听起来很公平,但是对于缓存而言,frequency of usage的权重比上次访问时的重量更大,这将我们带入下一个算法。
LFU-最少使用
lfu同时考虑了数据的年龄和频率。但是,这里的问题经常被使用长时间停滞在缓存中
MRU-最近使用的
为什么有人在谈论使用频率之后会使用MRU算法?我们不会总是重新阅读我们刚刚阅读的数据吗?不必要。成像图像库应用程序,专辑的图像在正确滑动时会被缓存和加载。那回到上一张照片怎么样?是的,发生这种情况的可能性较小。
FIFO-首先
当缓存开始像队列一样工作时,您将有一个FIFO缓存。这非常适合涉及数据的管道依次读取和处理的情况。
LRU实施
缓存基本上是哈希表。内部的每个数据都进行了哈希和存储,使其可以在O(1)处访问。
现在,我们如何踢出最近使用的物品,到目前为止,我们只有哈希功能,并且它的数据。我们需要以某种方式存储访问顺序。
我们可以做的一件事是有一个数组,我们在访问元素时输入该元素。但是,在这种方法中计算频率变成了过度杀伤。我们可以选择另一个哈希表,这不是访问问题。
双重链接列表可能适合该目的。每次访问链接列表并维护哈希表中的参考,使我们能够在o(1)中访问它。
。
当元素已经存在时,将其从当前位置中删除,并将其添加到链接列表的末端。
在哪里放置缓存?
缓存越接近其消费者。在Web应用程序的情况下,这可能意味着将缓存与Web服务器一起放置。但是有几个问题
- 当服务器下降时,我们将丢失与服务器缓存关联的所有数据
- 当需要增加缓存的大小时,它将侵入服务器分配的内存。

最可行的解决方案是维护服务器外部的缓存。尽管它包含了额外的延迟,但值得缓存的可靠性。
分布式缓存是在服务器外托管缓存并独立缩放的概念。
什么时候实施缓存?
找到实施缓存的技术是所有步骤中最简单的。 CACHES承诺高速API,并且不掺入它们可能会感到愚蠢,但是如果您出于错误的原因这样做,它只会为系统增加额外的开销。因此,在实施缓存之前,请确保
- 您的数据存储的命中率很高
- 您已经竭尽所能提高DB级别的速度。
- 您已经学习并研究了各种缓存方法和系统,并找到了适合您的目的的方法。
Python实施
要了解缓存,我们需要了解我们正在处理的数据。在此示例中,我使用的是简单的mongodb架构User和Event collections。
我们将有API通过其关联ID获取User和Event。以下代码段包含一个辅助功能,可以从mongodb
获取相应的文档
def read_document(db, collection, _id):
collection = db[collection]
return collection.find_one({"_id": _id})
python内置的lru-caching
from flask import jsonify
from functools import lru_cache
@app.route(“/user/<uid>“)
@lru_cache()
def get_user(uid):
try:
return jsonify(read_user(db, uid))
except KeyError as e:
return jsonify({”Status": “Error”, “message”: str(e)})
lru-caching如您在下面的示例中所看到的,易于实现,因为它具有盒子python的支持。但是有一些缺点
- 很简单,可以扩展到高级功能
- 仅支持一种类型的缓存算法
- lru-caching是服务器端缓存的一个经典示例,因此服务器中有内存超载。
- Cache Timeout不是隐含的,请手动无效
缓存在Python烧瓶中
为了支持其他缓存,例如Redis或Memcache,Blask-Cache提供了框外支持。
config = {’CACHE_TYPE’: ‘redis’} # or memcache
app = Flask( __name__ )
app.config.from_mapping(config)
cache = Cache(app)
@app.route(“/user/<uid>“)
@cache.cached(timeout=30)
def get_user(uid):
try:
return jsonify(read_user(db, uid))
except KeyError as e:
return jsonify({”Status": “Error”, “message”: str(e)})
这样,我们涵盖了缓存,何时使用一个缓存以及如何在Python烧瓶中实施。