Versão em Português Brasileiro
概括
- Technology versions
- Background knowledge needed
- Why I decided to write it
- Too long; didn't read
- Database example
- Squash guide
- Conclusion
技术版本
- hasura v2.0.9
- Hasura Cli v2.0.9
- PostgreSQL 12
背景知识需要
- 了解sql,它的命令
- 了解迁移的工作方式
- Hasura GraphQL Engine如何工作
- Git如何工作
为什么我决定写它
在我工作的电子商务公司开发一个项目期间,我们有一项任务需要更改数据库结构,必须更改许多表和列才能完成任务。
作为 hasura graphql Engine 提供了一个网页来对数据库进行结构更改,我使用此界面进行了更改,并执行了必要的手动查询。所有这些修改都在存储库中创建了迁移,如在Hasura启用迁移的项目所期望的。
。修改后,值得注意的是,这些文件夹的数量具有修改以保存在迁移格式中的文件夹。我决定使用该命令将所有命令压缩到一个文件中,这将更可读。那是我的错误发生的时候:没有事先进行基本验证,我执行了命令并删除了先前的迁移。这就是我花了一天多的时间试图修复本可以在使用命令之前使用简单清单避免的错误的方法。我们如何避免这种情况?我将在下一个主题中解释。
太长;没有阅读
- 使用迁移进行更改。
- 使用git或类似,请提交保存迁移的承诺。
- 确保使用
hasura migrate apply和hasura migrate apply --down <N>根据需要执行up.sql和down.sql文件。使用SQL选项卡进行手动修复(可能发生错误),而无需使用迁移。 - 将您的完整迁移到版本控制系统。
- 使用命令
hasura migrate squash --from <num_migration> --name <name>执行 squalash ,删除旧迁移(您已经在版本控件处有它们)。 - 使用
hasura migrate apply --skip-execution在数据库中标记创建的迁移(如果未应用迁移的迁移,请勿使用 flag)。 - 再次使用命令
hasura migrate apply --down <N>删除迁移,然后在没有标志的情况下使用它来确保其工作。 - 将您的更改提交版本控制系统。
- (可选)如果需要,请进行优化,例如:如果有
DROP TABLE,请删除ALTER TABLE(当然不会丢失数据)。
数据库示例
要正确地演示如何做 squalash ,我将使用一个带有单个表的简单数据库,但是在实际情况下,您可以在 n 表之间进行各种操作,这可能会导致更大而复杂的南瓜。
我们的数据库包含通过此结构定义的students表:
CREATE TABLE "public"."students" (
"id" serial NOT NULL,
"name" Text NOT NULL,
"score" text NOT NULL,
PRIMARY KEY ("id")
);
它是在我们已经连接到PostgreSQL中创建的数据库,禁用控制台并开始在项目中迁移的数据库后创建的。您可以查看有关如何在迁移和元数据的section中启用迁移的更多详细信息(CI/CD)
假设这张桌子充满了一些学生数据:

一路上某个地方,我们意识到score列中的数据不能是文本,因为我们想对它们进行一些算术。但是,如果在生产中使用了此数据,我们将无法更改此数据! (假设您有成千上万的重要数据,并且不能丢失它们)
那该怎么办?在开发环境中,我们将创建一个新的列以适应此数据。我们将其命名为score_decimal,因为它代表得分是允许算术操作的十进制数字。转到students表的修改选项卡,然后单击添加新列。我们将其定义为Numeric列。
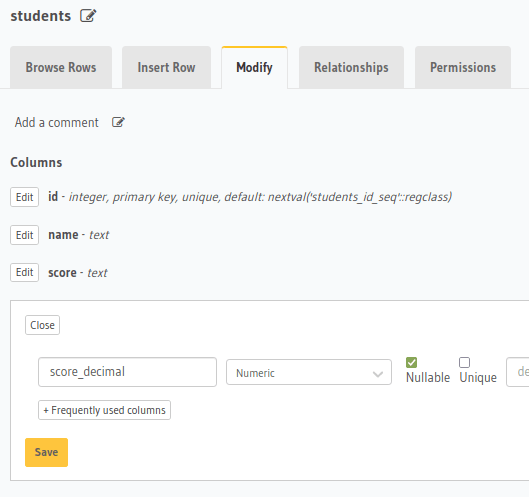
创建了新列后,我们可以将数据从score列迁移到score_decimal。为此,我们将使用位于数据库中表正下方的SQL部分。

在此选项卡中,您可以直接针对所选数据库运行SQL代码,将这些查询标记为迁移。根据代码的不同,Hasura可能足够聪明,可以识别它是结构性的还是数据更改并将其标记为迁移,因此在运行查询之前,请务必注意,以查看“ 这是迁移“框已启用。
将查询转换为文本字段中的分数的查询,我们可以将其运行而无需将其添加为迁移,以验证查询是否如所述执行。检查后,我们可以启用迁移框并为其编写名称,我使用了描述性名称cast_students_score_to_decimal_migration。这是转换数据的查询:
UPDATE students
SET score_decimal=CAST(score AS DECIMAL)
WHERE students.id = students.id;
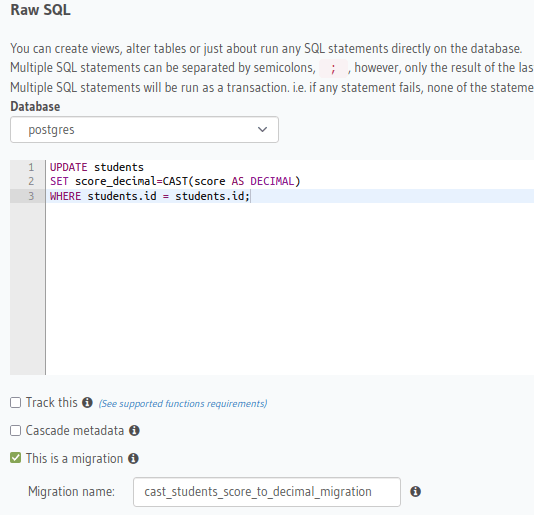
注意:进行更改字段类别的结构更改时,请务必小心,因此请在步骤中进行操作并更新视图层(前端),以更改新类型,而不会破坏客户端的应用程序。
运行数据的更新后,我们可以重命名列并删除旧列。迁移的名称为rename_columns_and_remove_old_migration。
ALTER TABLE students RENAME COLUMN "score" TO "score_text";
ALTER TABLE students RENAME COLUMN "score_decimal" TO "score";
ALTER TABLE students DROP COLUMN "score_text";
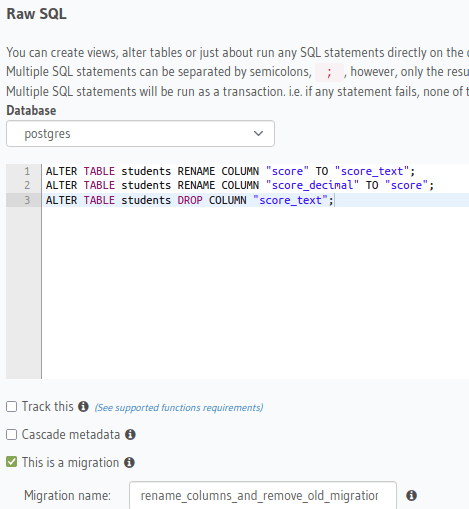
这样,我们完成了修改以运行算术操作,但是我们最终得到了一些可以通过squash操作加入的单独迁移,因为它们可以一起执行。
南瓜指南
对于迁移的squash过程“正确”(在过程中间总是会出现意外错误),我们需要确保遵循一些步骤。我将列出其中的一些以避免在此过程中发生错误。
- 保存在存储库中的迁移
- 确保可以进行迁移和撤销而没有错误
- 保存完整的迁移
- 挤压迁移
- 将迁移标记为执行
- 保存更改
- (可选)根据需要修改压缩迁移(并保存更改)
1.保存在存储库中的迁移
要跟踪我们的迁移而不是失去进步,我们可以保存提交的变化,然后我们可以继续改变它们而不会失去我们所做的事情,这是我之前犯的错误之一,而不是保存版本控制。
2.确保可以进行迁移并撤消任何错误
在存储库中保存的迁移后,我们可以开始修改那些不完整的down.sql文件的迁移。由于复杂的更改,例如重命名列和删除同一迁移中的列,我们对数据库进行的许多更改并不总是反映在文件中。例如,在最后一个迁移中,down.sql文件被填写如下:
-- Could not auto-generate a down migration.
-- Please write an appropriate down migration for the SQL below:
-- ALTER TABLE students RENAME COLUMN "score" TO "score_text";
-- ALTER TABLE students RENAME COLUMN "score_decimal" TO "score";
-- ALTER TABLE students DROP COLUMN "score_text";
为了使迁移工作,即删除更改,我们将逆转up.sql中的命令。
ALTER TABLE students ADD COLUMN "score_text" text;
ALTER TABLE students RENAME COLUMN "score" TO "score_decimal";
ALTER TABLE students RENAME COLUMN "score_text" TO "score";
我们将使用创建新列并逆转命令的迁移。
ALTER TABLE "public"."students" DROP COLUMN "score_decimal";
这样,我们可以使用hasura migrate apply的--up和--down标志。该命令根据迁移中定义的.sql更改数据库。如果将文件与它们各自的命令相关联,则更有意义,使用--down的命令将删除应用的迁移更改,而--up将应用它们(如果未定义,则默认应用--up)。要删除一些,请使用:
hasura migrate apply --down <N>
在命令中, n 是将要删除的迁移数量。使用hasura migrate apply --help查看更多详细信息。
注意:如果您运行迁移并且失败了,如果您在同一文件中有一个以上的SQL命令,请尝试通过SQL Tab(无创建新的)修复它,请更正它并尝试再次。
3.保存完整的迁移
由于您已经测试了迁移并且它们正在工作,因此再次将其保存在提交中,现在是完整的迁移。
4.挤压迁移
在所有迁移完成和工作时,我们可以 squalash 它们,也就是说,将它们压缩到一个迁移中。为此,我们将运行命令:
hasura migrate squash --from <num_migracao> --name <name>
它为我们压缩迁移文件。在此示例中,我会喜欢的:
hasura migrate squash --from 1638852925395 --name "changing_column_type"
此命令将从前缀1638852925395开始将所有迁移合并为一个名为“ consews_column_type” 的迁移。我建议您删除以前的迁移,因为它们已经保存在存储库中。
5.将迁移标记为执行
一旦我们创建了由于操作而创建了新的压缩迁移,如果未将先前的迁移应用于数据库,我们将运行该命令以标记它,就好像我们只是迁移一样生成已经应用了:
hasura migrate apply --skip-execution
请记住,仅当我们实际将其他迁移的更改应用于数据库时,才应运行此命令,否则,在没有--skip-execution标志的情况下运行命令以正常应用。
6.保存更改
完成此操作后,将更改再次保存在存储库的版本控件中以避免失去更改。
7.(可选)根据需要修改压缩迁移(并保存更改)
如果您的迁移有许多命令,请评估文件,并根据所做的更改查看是否可以简化执行的SQL代码。例如,您创建一个表,然后在另一个迁移中添加列,如果您没有在中间添加任何数据,否则尚未进行生产,请在创建表格时直接添加列这将简化代码。
结论
我希望这些指示可以作为指南,以便您在开发的项目中不会犯同样的错误。我试图将尽可能多的细节放在分步说明中及其背后的原因。
这些说明也可以在其他项目中复制,即使它们不遵循相同的技术,但是如果它们的概念相似,则有可能。如果您不立即使用它们,至少我希望您从本文中的展示中学到了一些东西。
欢迎任何可以增强本文的积极批评!与需要此内容的其他人分享!
谢谢您的关注。