将被刮擦
为什么要从serpapi?
使用Google Lens API使用API通常可以解决在创建自己的解析器或爬网时可能会遇到的所有或大多数问题。从网络剪接的角度来看,我们的API可以帮助解决最痛苦的问题:
- 通过求解验证码或IP块,来自受支持的搜索引擎的旁路块。
- 无需从头开始创建解析器并维护它。
- 支付代理和验证码求解器。
- 如果需要更快地提取数据,则不需要使用浏览器自动化。
前往Playground进行现场互动演示。
准备
首先,我们需要创建一个node.js* project并添加koude0软件包koude1和koude2。
为此,在我们项目的目录中,打开命令行并输入:
$ npm init -y
,然后:
$ npm i serpapi dotenv
*如果您没有安装node.js,则可以download it from nodejs.org并遵循安装documentation。
-
SERPAPI软件包用于使用SERPAPI刮擦和解析搜索引擎结果。从Google,Bing,Bing,Yandex,Yahoo,Home Depot,eBay等获取搜索结果。
-
dotenv软件包是一个零依赖性模块,将环境变量从
.env文件加载到process.env。
接下来,我们需要在我们的package.json文件中添加一个带有“模块”值的顶级“类型”字段,以允许using ES6 modules in Node.JS:

目前,我们完成了项目的设置node.js环境,然后转到分步代码说明。
代码说明
首先,我们需要从koude2库中导入dotenv,而config和getJson从koude1库:
import dotenv from "dotenv";
import { config, getJson } from "serpapi";
然后,我们应用一些配置。致电dotenv koude12方法,然后将您的SERPAPI私有API键设置为全局koude8对象。
dotenv.config();
config.api_key = process.env.API_KEY; //your API key from serpapi.com
-
dotenv.config()将读取您的.env文件,解析内容,将其分配给process.env,并用parsed键返回包含已加载内容或error键的对象。 。
-
config.api_keyallows您通过修改配置对象来声明全局api_key值。
接下来,我们编写搜索engine并编写必要的搜索参数以提出请求:
const engine = "google_lens"; // search engine
const params = {
url: "https://user-images.githubusercontent.com/64033139/209465038-010d1e56-16db-41d6-9769-6707d6f57111.png", //Parameter defines the URL of an image to perform the Google Lens search
hl: "en", // Parameter defines the language to use for the Google search
};
您可以使用下一个搜索参数:
-
url参数定义图像的URL来执行Google Lens搜索。 -
hl参数定义用于Google Lens搜索的语言。这是一个两个字母的语言代码。 (例如,en用于英语,es用于西班牙语或fr用于法语)。前往Google languages page获取支持的Google语言的完整列表。 -
no_cache参数将迫使Serpapi获取App Store搜索结果,即使已经存在缓存版本。仅当查询和所有参数完全相同时,才能提供缓存。 1小时后缓存到期。缓存的搜索是免费的,并且不计入您每月的搜索。它可以设置为false(默认值)以允许缓存的结果,也可以将true的结果设置为禁止缓存结果。no_cache和async参数不应一起使用。 -
async参数定义了要将搜索提交给SERPAPI的方式。可以将其设置为false(默认值)以打开HTTP连接并保持打开状态,直到获得搜索结果,或者true只需将搜索提交给SERPAPI并以后将其检索。在这种情况下,您需要使用我们的Searches Archive API来检索结果。async和no_cache参数不应一起使用。async不应在启用Ludicrous Speed的帐户上使用。
接下来,我们声明从页面获取数据并返回的函数getResult:
const getResults = async () => {
...
};
在此功能中,我们需要获得带有结果的json,delete不必要的键,然后返回。
const results = await getJson(engine, params);
delete results.search_metadata;
delete results.search_parameters;
return results;
最后,我们运行getResults函数,并使用koude41方法在控制台中打印所有接收的信息,该方法允许您使用带有必要参数的对象来更改默认输出选项:
getResults().then((result) => console.dir(result, { depth: null }));
输出
{
"reverse_image_search":{
"link":"https://www.google.com/search?tbs=sbi:AMhZZitWp1e8SyEO5dl4qkTCxU70zIpDW4BZqoAlVXqVRYoNA58nc3GQXbry3Wfl6SnzaHZ-xCdVfXXvQmYBmRz2VytmMNasi8-oL3MaHsJM80etUlB7YESZvKTW3gD6f49AdV9TV5A-Sm-Nl9p6tDjuCTPPO6XuZA"
},
"text_results":[
{
"text":"18",
"link":"https://www.google.com/search?q=18&hl=en",
"serpapi_link":"https://serpapi.com/search.json?device=desktop&engine=google&google_domain=google.com&hl=en&q=18"
},
{
"text":"M",
"link":"https://www.google.com/search?q=M&hl=en",
"serpapi_link":"https://serpapi.com/search.json?device=desktop&engine=google&google_domain=google.com&hl=en&q=M"
}
],
"knowledge_graph":[
{
"title":"BMW i8",
"subtitle":"Sports car",
"link":"https://www.google.com/search?q=BMW+i8&kgmid=/m/080607h&hl=en&gl=US",
"more_images":{
"link":"https://www.google.com/search?q=BMW+i8&kgmid=/m/080607h&ved=0EOTpBwgAKAAwAA&source=.lens.button&tbm=isch&hl=en&gl=US",
"serpapi_link":"https://serpapi.com/search.json?device=desktop&engine=google&gl=US&google_domain=google.com&hl=en&q=BMW+i8&tbm=isch"
},
"thumbnail":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH",
"images":[
{
"title":"Image #1 for BMW i8",
"source":"https://www.youtube.com/watch?v=fOXuBey9xo8",
"link":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH",
"size":{
"width":300,
"height":168
}
},
{
"title":"Image #2 for BMW i8",
"source":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSLMCx-TtUdq5kmOhdczYL-PWIgaWtUntnHVAJWbbo7vin_obsM",
"link":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS8sXyFSX0NjlLBQcQbJAC85f-Aw9WIEX2D-Y3by-C7pd23R3C2",
"size":{
"width":276,
"height":182
}
}
]
},
... and other knowledge graph results
],
"visual_matches":[
{
"position":1,
"title":"The 2023 BMW i8 M (All we know so far) - YouTube",
"link":"https://www.youtube.com/watch?v=fOXuBey9xo8",
"source":"youtube.com",
"source_icon":"https://encrypted-tbn0.gstatic.com/favicon-tbn?q=tbn:ANd9GcQHQslzHLLyLc_qne5jxn7JocidlmUPyegZ8ojX3WVlorFk8BxW9a3vJWjDzN99UHVTqSaNBj_-6XykhxuVQfF3Ye7xScSWSuc2QHXi0a12CkVwBmo",
"thumbnail":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH"
},
... and other visual matches results
]
}
diy解决方案
本节是为了显示我们的解决方案和DIY解决方案之间的比较。
如果您不需要解释,请看一下the full code example in the online IDE
import puppeteer from "puppeteer-extra";
import StealthPlugin from "puppeteer-extra-plugin-stealth";
puppeteer.use(StealthPlugin());
const searchParams = {
imageUrl: "https://user-images.githubusercontent.com/64033139/209465038-010d1e56-16db-41d6-9769-6707d6f57111.png", //Parameter defines the URL of an image to perform the Google Lens search
hl: "en", //Parameter defines the language to use for the Google search
};
const URL = `https://lens.google.com/uploadbyurl?url=${searchParams.imageUrl}&hl=${searchParams.hl}&gl=${searchParams.gl}`;
async function getResultsFromPage(page) {
const reverseImageSearch = await page.evaluate(() => ({ link: document.querySelector(".z3qvzf .WpHeLc").getAttribute("href") }));
const knowledgeGraphItems = await page.$$(".sHc5hf > div");
const knowledgeGraph = [];
for (const item of knowledgeGraphItems) {
await item.click();
await page.waitForTimeout(2000);
const thumbnail = await item.$eval(".FH8DCc", (node) => node.getAttribute("src"));
knowledgeGraph.push(
await page.evaluate(
(thumbnail) => ({
title: document.querySelector(".DeMn2d").textContent,
subtitle: document.querySelector(".XNTym").textContent,
link: document.querySelector(".wNPKTe a").getAttribute("href"),
moreImagesLink: document.querySelector(".XkkoHf + div .Tc2PU > a").getAttribute("href"),
thumbnail,
images: Array.from(document.querySelectorAll(".XkkoHf + div .Tc2PU .Y02Gld a")).map((el) => ({
title: el.getAttribute("aria-label"),
source: el.getAttribute("href"),
link: el.querySelector("img").getAttribute("src"),
})),
}),
thumbnail
)
);
}
const height = await page.evaluate(() => document.querySelector(".jXKZBd").scrollHeight);
const scrollIterationCount = 5;
for (let i = 0; i < scrollIterationCount; i++) {
await page.mouse.wheel({ deltaY: height / scrollIterationCount });
await page.waitForTimeout(2000);
}
const visualMatches = await page.evaluate(() => {
return Array.from(document.querySelectorAll(".Vd9M6 a")).map((el) => ({
title: el.getAttribute("aria-label"),
link: el.getAttribute("href"),
source: el.querySelector(".PlAMyb span").textContent,
sourceIcon: el.querySelector(".PlAMyb img").getAttribute("src"),
thumbnail: el.querySelector(".Me0cf img").getAttribute("src"),
}));
});
await page.click("#text");
await page.waitForTimeout(2000);
const textResultsItems = await page.$$(".WfGljd[aria-label]");
const textResults = [];
for (const item of textResultsItems) {
await page.click("#text");
await page.waitForTimeout(2000);
await item.click();
await page.waitForTimeout(2000);
textResults.push(
await page.evaluate(() => ({
text: document.querySelector(".C3t4Ke").textContent,
link: document.querySelector("a[aria-label=Search]").getAttribute("href"),
}))
);
}
return { reverseImageSearch, textResults, knowledgeGraph, visualMatches };
}
async function getLensResults() {
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
const results = await getResultsFromPage(page);
await browser.close();
return results;
}
getLensResults().then((result) => console.dir(result, { depth: null }));
准备
首先,我们需要添加koude0包koude43,koude44和koude45来控制Chromium(或Chrome或Firefox,但现在我们仅在DevTools Protocol上使用DevTools Protocol或无头模式的DevTools Protocol在DevTools Protocol上使用Chromium。
为此,在我们项目的目录中,打开命令行并输入:
$ npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth
ð注意:另外,您可以使用puppeteer无需任何扩展即可,但是我强烈建议将其与puppeteer-extra一起使用puppeteer-extra-plugin-stealth,以防止网站检测到您使用的无头铬或正在使用web driver。您可以在Chrome headless tests website上检查它。下面的屏幕截图显示了差异。

Process
我们需要从HTML元素中提取数据。通过SelectorGadget Chrome extension,获得合适的CSS选择器的过程非常容易,该过程能够通过单击浏览器中的所需元素来获取CSS选择器。但是,它并不总是完美地工作,尤其是当JavaScript大量使用该网站时。
如果您想了解更多有关它们的信息,我们在Serpapi上有专门的Web Scraping with CSS Selectors博客文章。
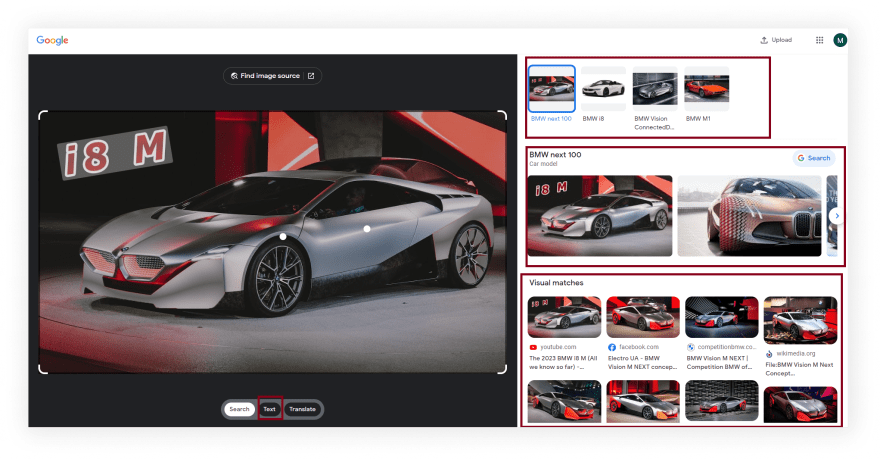
下面的GIF说明了使用Selectorgadget选择结果的不同部分的方法。
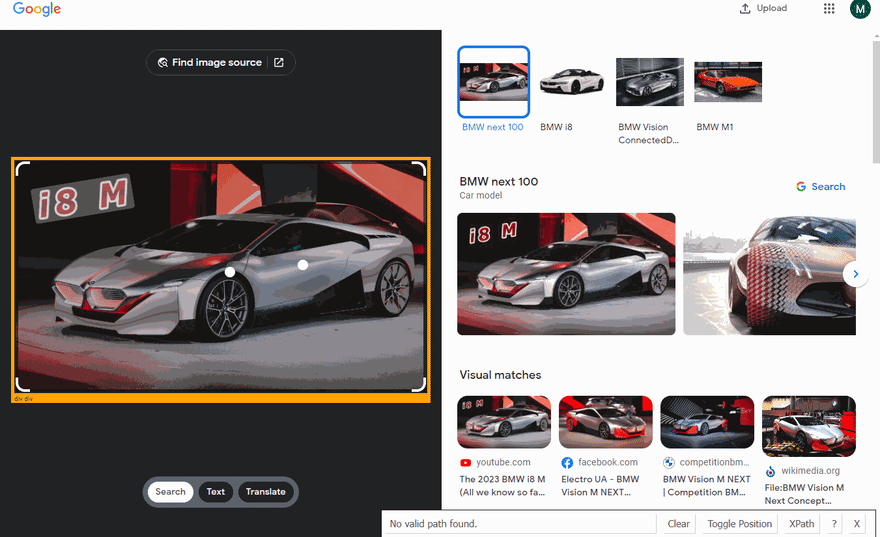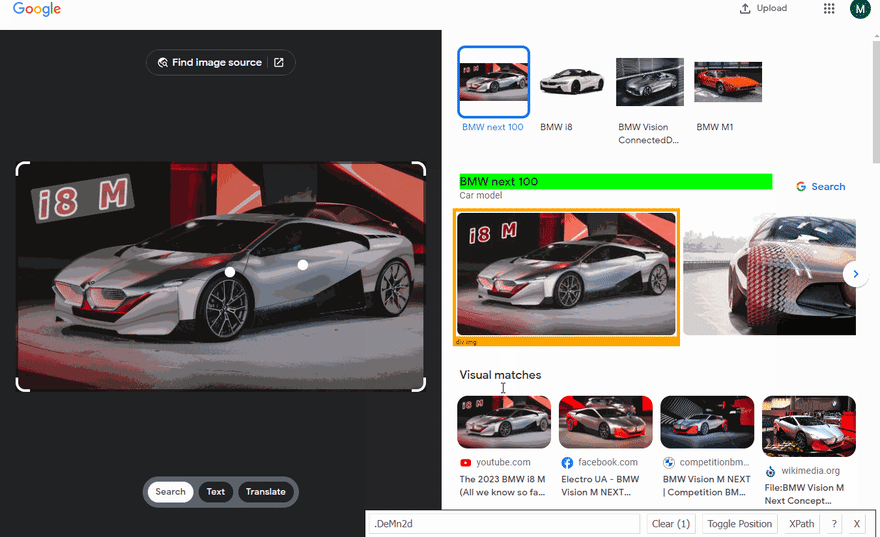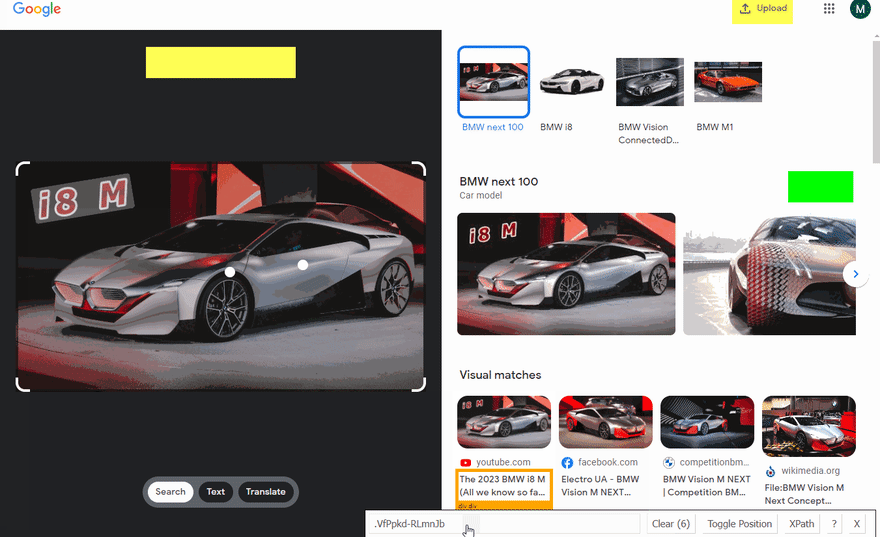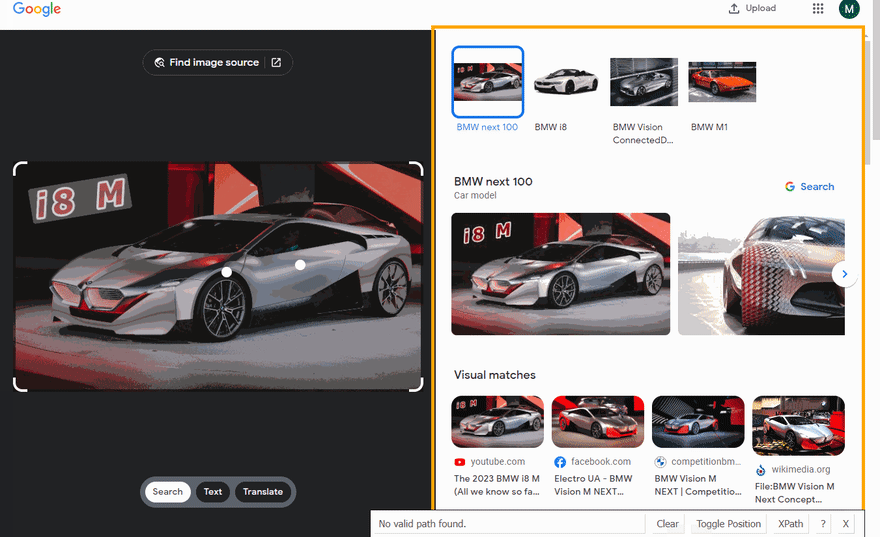
代码说明
声明koude43从puppeteer-extra库和koude51中控制Chromium浏览器,以防止网站检测到您正在puppeteer-extra-plugin-stealth库中使用web driver:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
接下来,我们对puppeteer“说”使用StealthPlugin,编写搜索参数和搜索URL:
puppeteer.use(StealthPlugin());
const searchParams = {
imageUrl: "https://user-images.githubusercontent.com/64033139/209465038-010d1e56-16db-41d6-9769-6707d6f57111.png", //Parameter defines the URL of an image to perform the Google Lens search
hl: "en", //Parameter defines the language to use for the Google search
};
const URL = `https://lens.google.com/uploadbyurl?url=${searchParams.imageUrl}&hl=${searchParams.hl}&gl=${searchParams.gl}`;
接下来,我们编写一个函数以从页面中获取结果:
async function getResultsFromPage(page) {
...
}
在此功能中,我们将使用下一个方法来获取必要的信息:
然后,我们从页面上下文(使用koude60方法)获取到Google反向图像的链接,然后将其保存在reverseImageSearch常数中:
const reverseImageSearch = await page.evaluate(() => ({ link: document.querySelector(".z3qvzf .WpHeLc").getAttribute("href") }));
接下来,我们获得知识图信息。为此,我们需要从页面上获取所有knowledgeGraphItems(使用koude63方法)。
然后,使用koude64循环我们单击每个item上的(koude65方法),然后从此知识图中获取并添加(koude67方法)信息到knowledgeGraph array:
const knowledgeGraphItems = await page.$$(".sHc5hf > div");
const knowledgeGraph = [];
for (const item of knowledgeGraphItems) {
await item.click();
await page.waitForTimeout(2000);
const thumbnail = await item.$eval(".FH8DCc", (node) => node.getAttribute("src"));
knowledgeGraph.push(
await page.evaluate(
(thumbnail) => ({
title: document.querySelector(".DeMn2d").textContent,
subtitle: document.querySelector(".XNTym").textContent,
link: document.querySelector(".wNPKTe a").getAttribute("href"),
moreImagesLink: document.querySelector(".XkkoHf + div .Tc2PU > a").getAttribute("href"),
thumbnail,
images: Array.from(document.querySelectorAll(".XkkoHf + div .Tc2PU .Y02Gld a")).map((el) => ({
title: el.getAttribute("aria-label"),
source: el.getAttribute("href"),
link: el.querySelector("img").getAttribute("src"),
})),
}),
thumbnail
)
);
}
接下来,我们需要滚动页面以加载所有缩略图(如果不这样做,我们只会得到1x1像素尺寸的占位符)。为此,我们获得页面高度,设置scrollIterationCount以定义我们要如何分割页面,然后滚动它(koude70方法):
const height = await page.evaluate(() => document.querySelector(".jXKZBd").scrollHeight);
const scrollIterationCount = 5;
for (let i = 0; i < scrollIterationCount; i++) {
await page.mouse.wheel({ deltaY: height / scrollIterationCount });
await page.waitForTimeout(2000);
}
接下来,我们获取视觉匹配结果的信息,并将其保存在visualMatches常数中。
const visualMatches = await page.evaluate(() => {
return Array.from(document.querySelectorAll(".Vd9M6 a")).map((el) => ({
title: el.getAttribute("aria-label"),
link: el.getAttribute("href"),
source: el.querySelector(".PlAMyb span").textContent,
sourceIcon: el.querySelector(".PlAMyb img").getAttribute("src"),
thumbnail: el.querySelector(".Me0cf img").getAttribute("src"),
}));
});
要获取文本结果,我们单击“文本”按钮,获取所有文本项目,并将每个项目设置为textResults数组:
await page.click("#text");
await page.waitForTimeout(2000);
const textResultsItems = await page.$$(".WfGljd[aria-label]");
const textResults = [];
for (const item of textResultsItems) {
await page.click("#text");
await page.waitForTimeout(2000);
await item.click();
await page.waitForTimeout(2000);
textResults.push(
await page.evaluate(() => ({
text: document.querySelector(".C3t4Ke").textContent,
link: document.querySelector("a[aria-label=Search]").getAttribute("href"),
}))
);
}
然后,我们返回对象,其中包括我们在此功能中获得的所有信息:
return { reverseImageSearch, textResults, knowledgeGraph, visualMatches };
接下来,编写一个函数来控制浏览器并获取信息:
async function getLensResults() {
...
}
首先,在此功能中,我们需要使用带有当前options的puppeteer.launch({options})方法来定义browser,例如headless: true和args: ["--no-sandbox", "--disable-setuid-sandbox"]。
这些选项意味着我们将headless模式和数组与arguments一起使用,我们用来允许在线IDE中启动浏览器流程。然后我们打开一个新的page:
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
接下来,我们将等待选择器的默认值(30 sec)更改为60000毫秒(1分钟)的时间,以使用koude79方法慢速互联网连接,请使用koude81方法访问URL:
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
然后,我们定义results数组,并从页面保存结果:
const results = await getResultsFromPage(page);
最后,我们关闭浏览器,然后返回收到的数据:
await browser.close();
return results;
现在我们可以启动我们的解析器:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
输出
{
"reverseImageSearch":{
"link":"https://www.google.com/search?tbs=sbi:AMhZZis56hg-YEqgOHS8pa8l_1QxyQa2cxtCmEZoD71xt6dE6WPxXnbPXQV6EuTR9Yhnyb56yuK1pVQveu_1_1lXI49V16nuPJPYy5LFOIu9_16JkSKvotCdgwacqAKAxnmZ8mjkw0qYAZqvGzmkOCPnXM6oko0pADoQ4A"
},
"textResults":[
{
"text":"\"18\"",
"link":"https://www.google.com/search?q=18%20"
},
{
"text":"\"M\"",
"link":"https://www.google.com/search?q=M"
}
],
"knowledgeGraph":[
{
"title":"BMW i8",
"subtitle":"Sports car",
"link":"https://www.google.com/search?q=BMW+i8&kgmid=/m/080607h&hl=en&gl=US",
"moreImagesLink":"https://www.google.com/search?q=BMW+i8&kgmid=/m/080607h&ved=0EOTpBwgAKAAwAA&source=.lens.button&tbm=isch&hl=en&gl=US",
"thumbnail":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH",
"images":[
{
"title":"Image #1 for BMW i8",
"source":"https://www.youtube.com/watch?v=fOXuBey9xo8",
"link":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH"
},
{
"title":"Image #2 for BMW i8",
"source":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSLMCx-TtUdq5kmOhdczYL-PWIgaWtUntnHVAJWbbo7vin_obsM",
"link":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS8sXyFSX0NjlLBQcQbJAC85f-Aw9WIEX2D-Y3by-C7pd23R3C2"
}
]
},
... and other knowledge graph results
],
"visualMatches":[
{
"title":"The 2023 BMW i8 M (All we know so far) - YouTube",
"link":"https://www.youtube.com/watch?v=fOXuBey9xo8",
"source":"youtube.com",
"sourceIcon":"https://encrypted-tbn0.gstatic.com/favicon-tbn?q=tbn:ANd9GcQHQslzHLLyLc_qne5jxn7JocidlmUPyegZ8ojX3WVlorFk8BxW9a3vJWjDzN99UHVTqSaNBj_-6XykhxuVQfF3Ye7xScSWSuc2QHXi0a12CkVwBmo",
"thumbnail":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH"
},
... and other visual matches results
]
}
链接
如果您想在此博客文章中添加其他功能,或者您想查看Serpapi,write me a message的某些项目。
添加Feature Requestð«或Bugð