介绍
我一直在寻找一个项目来尝试了解图形数据库,尤其是Amazon Neptune一段时间了。我十岁的孩子着迷于希腊神及其家人,我正在看着他追踪一棵希腊神的家谱。这是如此令人费解,以至于我认为这可能是一个值得的项目,也可以一起工作。
图数据库
图数据库中的数据主要存储为3个不同的对象:
- 节点 - 节点是您在数据库中存储的内容。相关地思考,这类似于表中的记录。如果桌子在这种情况下对神的细节持有细节,那么关于单个神的每个记录都将是他们自己的节点。节点可以是任何实体,一个人,一个地方,事物等的实例,并且相同的图形数据库可以保存这些实体的多种类型的实例。
- 边缘 - 边缘是节点之间的关系。同样,在关系上思考,它们类似于节点之间的外键。人际关系不是强制性的,但它们可能是多对多的。相同的节点可以以多种不同的方式相互关联。
- 属性 - 可以添加到节点或边缘的额外非强制性属性。
亚马逊海王星支持RDF和属性图。我可以为两者之间的差异提供的最简单解释是,使用RDF,一切都是节点。您添加到节点的每个属性都是与原始节点相关的另一个节点。例如,如果原始节点是神,那么上帝的名字将是另一个节点。在属性图中,属性可以保存在节点上。为了本文,我要坚持使用属性图。
亚马逊海王星
亚马逊海王星是为云构建的完全管理的数据库服务,使构建和运行图形应用程序变得更加容易。
最近写了很多关于亚马逊海王星的文章,我不会尝试在这里复制。
AWS Community Builders @abc_wendsss和@ymwjbxxq的AWS Community Builders撰写了有关如何开始服务的大量资源。
自Neptune Serverless推出以来,现在更容易开始。尽管关于这是否真正没有服务(我的看法,不是)存在争议,但它确实使开始服务变得更加容易。有关辩论的更多详细信息,请参见Jeremy Daly的文章Not so serverless Neptune。
我将使用Neptune无服务器进行此练习。
入门
1)转到https://eu-west-1.console.aws.amazon.com/neptune/home?region=eu-west-1#databases:,然后单击创建数据库
2)选择无服务器作为引擎类型

3)小心模板。默认值似乎是生产的,但我选择了开发和测试选项。

4)默认情况下创建了jupyter笔记本电脑,以帮助您针对数据库运行查询。为了提高效率,我选择使用它,但是如果您想节省成本,可以将其关闭。您必须指定笔记本的名称,还必须为笔记本上的IAM角色指定访问权限。
5)我将所有其他所有内容都放在默认设置上。
6)单击创建数据库
7)这将需要几分钟才能启动数据库和笔记本。
加载数据中
可以使用这样的OpencyPher语句直接将数据直接插入到数据库中以创建节点
%%oc
CREATE (g1:Uranus { name:"Uranus", branch: ""});
CREATE (g2:Gaia { name:"Gaia", branch: ""});
CREATE (g3:Cronus { name:"Cronus", branch: "Titan"});
或这是为了在节点之间建立关系
%%oc
MATCH (a),(b),(c) WHERE a.name = "Uranus"
AND b.name = "Cronus" AND c.name = "Gaia"
create (a)-[r:parentOf]->(b),(c)-[r1:parentOf]->(b)
RETURN type(r);
您可以使用另一个查询返回关系
%%oc
MATCH p = (a {name: 'Cronus'})-[:parentOf*1..2]-(b)
RETURN *;

散装装载机
但是,如果您只有少量记录,则使用Neptune Bulk Loader应该更快地奏效。

要使这项工作,您需要一个IAM角色和S3 VPC端点。 AWS文档在详细介绍所需步骤
方面做得很好
here.
数据格式
我创建了两个文件要通过散装加载器加载,一个用于节点,一个用于边缘。
nodes.csv
:ID,name:String,branch:String,:LABEL
g1,"Uranus","",Uranus
g2,"Gaia","",Gaia
g3,"Cronus","",Cronus
edges.csv
:ID,:START_ID,:END_ID,:TYPE
e1,g1,g3,parentOf
e2,g2,g3,parentOf
您可以将更多属性作为列标题添加,并且将加载到数据库中的节点或边缘。
一旦制定了所需的策略和端点,散装装载机就容易得多。我旋转一个小型T2.Micro实例,并使用EC2实例连接执行curl命令以运行加载程序。
curl -X POST \
-H 'Content-Type: application/json' \
https://database-1.cluster-cryicaski1uo.eu-west-1.neptune.amazonaws.com:8182/loader -d '
{
"source" : "s3://neptune-greek-gods/initial/nodes.csv",
"format" : "opencypher",
"userProvidedEdgeIds": "TRUE",
"iamRoleArn" : "arn:aws:iam::565877345391:role/GreekGodsUploadfromS3",
"region" : "eu-west-1",
"failOnError" : "FALSE",
"parallelism" : "MEDIUM"
}'
查询
亚马逊海王星支持Gremlin,OpencyPher和Sparql查询数据。对我来说,我在工作中接触了Neo4J和Opencypher,这对我来说是直观的。这是一种声明性的查询语言,例如SQL,如果您有SQL的经验,那么很容易掌握其基础知识。这是我发现有用的一些示例。
- 获取所有节点的计数
%%oc
MATCH (n)
RETURN COUNT(*);
- 返回所有节点或有限的数字。如果您想查看所有节点,则可以忽略最后一行。
%%oc
MATCH (n)
RETURN n
LIMIT 10;
- 删除所有节点(如果您需要在加载之前清除数据库,则有用)
%%oc
MATCH (n)
DETACH DELETE n
- 穿越节点以显示关系。以下查询显示了宙斯的所有直系亲属。
%%oc
MATCH p = (a {name: 'Zeus'})-[:parentOf*1..1]->(b)
RETURN *

- 参数
1..1设置了越过图形的啤酒花数。因此,通过更改这些,您可以显示出除原始节点以外的节点之间的更多关系。以下查询显示了宙斯的所有直系亲属,然后显示他们的孩子。
%%oc
MATCH p = (a {name: 'Zeus'})-[:parentOf*1..2]->(b)
RETURN *
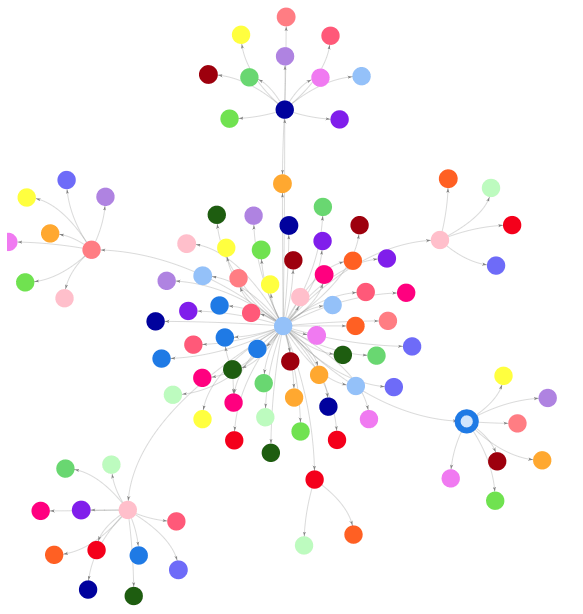
- 参数
->(b)表示仅返回一种从宙斯倒下的方式,在这种情况下。您可以删除>以返回宙斯孩子的其他父母。例如,赫拉(Hera)现在是这个查询的几个神的母亲。
%%oc
MATCH p = (a {name: 'Zeus'})-[:parentOf*1..2]-(b)
RETURN *

结束思想
在撰写本文时,一些想法不断发展。
关系
关于SQL和关系数据模型的伟大事物之一是,您可以在加载数据后使用数据。在图形数据库中,您需要事先知道这些关系。图数据库的功能是能够穿越图形并通过其他节点找到节点之间的关系。在图形数据库中执行此操作要比在普通关系数据库中容易得多。
多租户
我已经在许多数据平台上工作,这些数据平台可以支持单个数据库实例的多租户模式。这可以通过多种方式,单独的模式,调整表上的主要密钥。但是,我正在努力查看如何在单个图形数据库实例上执行此操作。
图形分析
我一直认为图形分析功能是图形数据库的令人难以置信的销售点,但是在研究了500个希腊神点及其彼此之间的关系之后,现在我不确定。我想我认为答案只会跳出而无需询问。但是,您仍然需要了解您的数据,要问的问题以及如何解释结果。
无服务器
为什么AWS选择RD来构建图形数据库?他们在DynamoDB中具有出色的产品,我认为将更适合图形数据。