抽象的
这个项目将非常有用,因为它将节省从图像中键入的时间和精力。图像处理通常被视为任意操纵图像以实现美学标准或支持首选现实。但是,图像处理更准确地定义为人类视觉系统和数字成像设备之间的翻译手段。
Python-Tesseract是Python的光学特征识别(OCR)工具。也就是说,它将识别并阅读图像中嵌入的文本。 Python-Tesseract是Google的Tesseract-Or发动机的包装纸。 Tesseract是从Python中的Ocropus模型开发的,该模型是C ++中的LSMT的叉子,称为Clstm。
Tesseract库配备了一个方便的命令行工具,称为Tesseract。我们可以使用此工具对图像执行OCR,并将输出存储在文本文件中。
使用Python中的Pytesseract库,我们制作了给定为输入的照片的图像处理。
范围:对于将从图像中获取文本的巨型组织,此应用程序可能会节省时间。它可以打开“无纸化文件”的世界,这也有助于升级存储空间。它也可以在自动化过程中有所帮助,因为它可以从图像本身获取文本。
目录
1-)简介
2-)方法论 /系统设计
3-)结果
数字列表
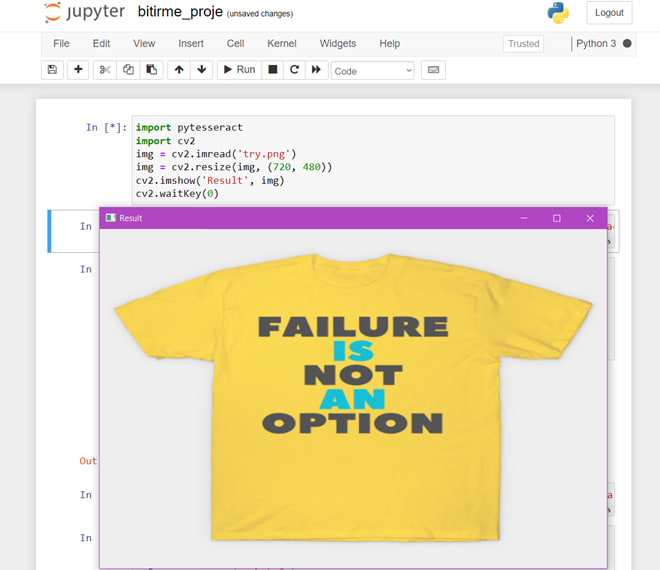

1.简介
使用Tesseract库Python-Tesseract的图像处理是Python的光学特征识别(OCR)工具。也就是说,它将识别并阅读图像中嵌入的文本。 Tesseract - 一种开源OCR引擎,在OCR开发人员中广受欢迎。即使有时实施和修改可能会很痛苦,但在最长的时间内,市场上有太多免费和强大的OCR替代方案。 Tesseract始于博士学位。布里斯托尔HP实验室的研究项目。它在1984年至1994年之间由HP开发,并在2005年发行了HP,HP在2005年发布了Tesseract作为开源软件。自2006年以来,它由Google开发。 Tesseract是Apache 2.0许可下的开源文本识别(OCR)引擎。它可以直接使用,也可以(对于程序员)使用API从图像中提取印刷文本。它支持多种语言。 Tesseract没有内置的GUI,但是3rdparty页面上有几个可用的。 Tesseract通过包装器与许多编程语言和框架兼容,可以在此处找到。它可以与现有布局分析一起使用,以识别大型文档中的文本,也可以与外部文本检测器一起使用,以识别单个文本行的图像中的文本。

安装Tesseract
tesseract –version
pip install pytesseract
pip install opencv-python
如果我们想将Tesseract集成到我们的Python代码中,我们将使用Tesseract的API。
tesseract image_path stdout
在文件中写入输出文本:
tesseract image_path text_result.txt
pytesseract 是Tesseract-Or引擎的包装。它也可作为Teseract的独立求职脚本有用,因为它可以读取枕头和Leptonica Imaging库支持的所有图像类型,包括JPEG,PNG,GIF,GIF,BMP,BMP,TIFF等。
下面的脚本将为您提供ORCR期间Tesseract检测到的每个字符的边界框信息。
import cv2
import pytesseract
img = cv2.imread(‘image.jpg’)
h, w, c = img.shape
boxes = pytesseract.image_to_boxes(img)
for b in boxes.splitlines():
b = b.split(‘ ‘)
img = cv2.rectangle(img, (int(b[1]), h — int(b[2])), (int(b[3]), h — int(b[4])), (0, 255, 0), 2)
cv2.imshow(‘img’, img)
cv2.waitKey(0)
如果我们想要围绕单词而不是字符的框,则功能image_to_data将派上用场。可以通过几种方式分析文本页面。如果您只想在一个小区域或不同方向上运行OCR,则Tesseract API提供多种页面细分模式。
。仅方向和脚本检测(OSD)。
•使用OSD的自动页细分
¢自动页细分,但没有OSD或OCR。
¢完全自动的页面细分,但没有OSD。 (默认)
¢假定一列可变大小的文本。
¢假定一个垂直对准文本的单个均匀块。
假设单个均匀的文本块。
¢将图像视为单个文本行。
¢将图像视为一个单词。
¢将图像视为一个圆圈中的单词。
¢将图像视为单个字符。
<稀疏文本。找到尽可能多的文本。
•稀疏文本,带有OSD。
要更改您的页面细分模式,请将自定义配置字符串中的PSM参数更改为上述任何模式代码。
2.方法 /系统设计
当从背景中对前景文本进行干净的分割时,tesseract效果最好。实际上,保证这些类型的设置可能非常具有挑战性。有多种原因,您可能无法从Tesseract中获得高质量的输出,例如图像在背景上有噪音。图像质量(尺寸,对比度,闪电)越好,识别结果越好。它需要一些预处理以改善OCR结果,需要适当地缩放图像,具有尽可能多的图像对比度,并且文本必须水平对齐。 Tesseract OCR非常强大,但确实有以下局限性。
•OCR不如我们可以使用的某些商业解决方案。
¢对受伪影影响的图像做得很好
¢它无法识别手写。
•它可能会发现gibberish并将其报告为OCR输出。
¢如果文档包含-l lang论点中给出的语言,则结果可能很差。
•并不总是擅长分析文档的自然阅读顺序。例如,它可能无法识别文档包含两个列,并且可以尝试跨列加入文本。
<质量较差的扫描可能会产生较差的OCR。
•它不会暴露有关字体家庭文本所属的信息。
打开一个简单的图像
- 导入CV2。
- 导入pytesseract。
- 将测试图像保存在同一目录中。
- 创建一个变量以使用cv2.imread()函数存储图像,并将图像的名称传递为参数。
- 要调整图像大小,请使用CV2.Resize()函数并传递所需的分辨率。
- 使用cv2.imshow(window_nameâ,image_name)。
- 添加cv2.waitkey(0)以显示无限的图像。
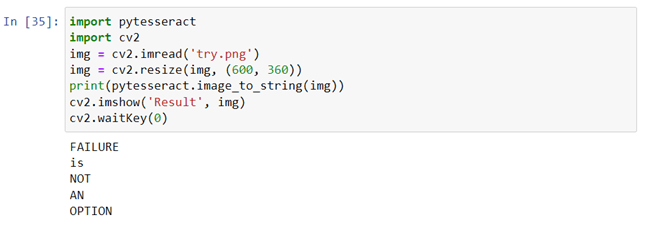
将图像转换为字符串
- 导入CV2,pytesseract。
- 将测试图像保存在同一目录中。
- 创建一个变量以使用cv2.imread()函数存储图像,并将图像的名称传递为参数。
- 使用cv2.imshow(window_nameâ,image_name)。
- 要转换为字符串使用pytesseract.image_to_string(âimage_nameâ)并将其存储在变量中。
- 打印字符串。
- 添加cv2.waitkey(0)以显示无限的图像。
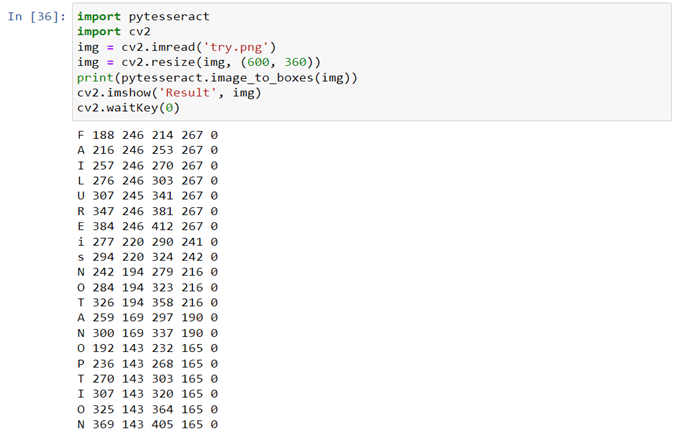
打印文本/数字的确切位置
image_to_boxes()函数在每个文本周围创建虚构框,并为每个字符返回四个值,如下:
a)x坐标。
b)Y坐标。
c)x坐标的对角点。
d)y坐标的对角点
- 导入CV2,pytesseract。
- 将测试图像保存在同一目录中。
- 创建一个变量以使用cv2.imread()函数存储图像,并将图像的名称传递为参数。
- 使用cv2.imshow(window_nameâ,image_name)。
- 返回coordinates pytesseract.image_to_boxes(âimage_nameâ)并将其存储在变量中。
- 打印字符串。
- 添加cv2.waitkey(0)以显示无限的图像。
围绕检测到的字符绘制盒子并标记它们
要在文本和标签上添加框,我们需要OpenCV的两个函数:
a)cv2.Rectangle(image_nameâ,x_coorcory,y_coorcory,rgb_value_of_color,sthumness_of_box)
b)cv2.putText(image_nameâ,x_coorcory,y_coorcory,–font_nameâ,font_size,rgb_value_of_of_color,sthumness_of_text)
)- 导入pytesseract,cv2。
- 使用Imread()。 阅读并显示
- 创建两个变量以使用img.shape()。 来存储每个字符的尺寸
- 使用pytesseract.image_to_boxes(img) 围绕每个字符进行虚构文本
- 创建一个用于循环的循环,该循环将列表的形式转换为所有坐标,以便于访问。
- 初始化X坐标,Y-坐标,宽度,高度的四个变量。
- 从上面创建的列表中分配各自的值。
- 作为列表元素的字符串形式,将其转换为整数。
- 使用cv2.Rectangle()函数在字符周围创建框。
- 使用cv2.puttext()添加字符周围的标签。
- 使用imshow()函数显示最终图像。
- 使用CV2.Waitkey(0)。 添加无限延迟
3.结果
深度学习几乎影响了计算机视觉的每个方面,对于角色识别和手写识别也是如此。基于深度学习的模型已设法获得了前所未有的文本识别精度,远远超出了传统信息提取和机器学习图像处理方法。
tesseract在文档图像遵循下一个准则时表现良好:
•从背景的前景文本进行干净的分割
•合适的水平对齐和缩放
•没有模糊和噪音的高质量图像
Tesseract 4.0的最新版本支持基于深度学习的OCR,这显着准确。 OCR引擎本身建立在长期记忆(LSTM)网络上,一种经常性神经网络(RNN)。
tesseract非常适合扫描干净的文档,并且具有很高的准确性和字体可变性,因为它的培训是全面的。我要说的是,如果您的任务是扫描书籍,文档和印刷文本,那么Tesseract是一个首选工具。