将被刮擦
完整代码
如果您不需要解释,请看一下the full code example in the online IDE
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
const reviewsLimit = 50; // hardcoded limit for demonstration purpose
const URL = `https://www.yelp.com/biz/kfc-seattle-18?osq=kfc#reviews`;
async function getReviewsFromPage(page) {
return await page.evaluate(() => {
return Array.from(document.querySelectorAll("section[aria-label='Recommended Reviews'] div > ul > li")).map((el) => {
const thumbnails = el.querySelector("div > a > img").getAttribute("srcset")?.split(", ");
const bestResolutionThumbnail = thumbnails && thumbnails[thumbnails.length - 1].split(" ")[0];
return {
user: {
name: el.querySelector(".user-passport-info span > a")?.textContent,
link: `https://www.yelp.com${el.querySelector(".user-passport-info span > a")?.getAttribute("href")}`,
thumbnail: bestResolutionThumbnail,
address: el.querySelector(".user-passport-info div > span")?.textContent,
friends: el.querySelector("[aria-label='Friends'] span > span")?.textContent,
photos: el.querySelector("[aria-label='Photos'] span > span")?.textContent,
reviews: el.querySelector("[aria-label='Reviews'] span > span")?.textContent,
eliteYear: el.querySelector(".user-passport-info div > a > span")?.textContent,
},
comment: {
text: el.querySelector("span[lang]")?.textContent,
language: el.querySelector("span[lang]")?.getAttribute("lang"),
},
date: el.querySelector(":scope > div > div:nth-child(2) div:nth-child(2) > span")?.textContent,
rating: el.querySelector("span > div[role='img']").getAttribute("aria-label")?.split(" ")?.[0],
photos: Array.from(el.querySelectorAll(":scope > div > div:nth-child(5) > div > div")).map((el) => {
const captionString = el.querySelector("img").getAttribute("alt");
const captionStart = captionString.indexOf(".");
const caption = captionStart !== -1 ? captionString.slice(captionStart + 2) : undefined;
return {
link: el.querySelector("img").getAttribute("src"),
caption,
};
}),
feedback: {
useful: el.querySelector(":scope > div > div:last-child span:nth-child(1) button span > span > span")?.textContent,
funny: el.querySelector(":scope > div > div:last-child span:nth-child(2) button span > span > span")?.textContent,
cool: el.querySelector(":scope > div > div:last-child span:nth-child(3) button span > span > span")?.textContent,
},
};
});
});
}
async function getReviews() {
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
const reviews = [];
while (true) {
await page.waitForSelector("section[aria-label='Recommended Reviews'] div > ul");
reviews.push(...(await getReviewsFromPage(page)));
const isNextPage = await page.$("a[aria-label='Next']");
if (!isNextPage || reviews.length >= reviewsLimit) break;
await page.click("a[aria-label='Next']");
await page.waitForTimeout(3000);
}
await browser.close();
return reviews;
}
getReviews().then((result) => console.dir(result, { depth: null }));
准备
首先,我们需要创建一个node.js* project并添加koude0包koude1,koude2和koude3以控制铬(或chrome或firefox,但现在我们仅在DevTools Protocol上使用铬在headless或无头模式中。
为此,在我们项目的目录中,打开命令行并输入:
$ npm init -y
,然后:
$ npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth
*如果您没有安装node.js,则可以download it from nodejs.org并遵循安装documentation。
ð注意:另外,您可以使用puppeteer无需任何扩展即可,但是我强烈建议将其与puppeteer-extra一起使用puppeteer-extra-plugin-stealth,以防止您使用无头铬或正在使用web driver的网站检测。您可以在Chrome headless tests website上检查它。下面的屏幕截图显示了差异。

Process
我们需要从HTML元素中提取数据。通过SelectorGadget Chrome extension,获得合适的CSS选择器的过程非常容易,该过程能够通过单击浏览器中的所需元素来获取CSS选择器。但是,它并不总是完美地工作,尤其是当JavaScript大量使用该网站时。
如果您想了解更多有关它们的信息,我们在Serpapi上有专门的Web Scraping with CSS Selectors博客文章。
下面的GIF说明了使用Selectorgadget选择结果的不同部分的方法。
代码说明
声明koude1从puppeteer-extra Library和koude9控制Chromium浏览器,以防止网站检测到您正在使用puppeteer-extra-plugin-stealth库中使用web driver:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
接下来,我们对puppeteer“说”使用StealthPlugin,设置要接收多少结果(reviewsLimit常数),然后搜索URL:
ð注意:您可以从我们的Web scraping Yelp Organic Results with Nodejs博客文章中获得DIY解决方案部分的位置评论URL。
puppeteer.use(StealthPlugin());
const reviewsLimit = 50; // hardcoded limit for demonstration purpose
const URL = `https://www.yelp.com/biz/kfc-seattle-18?osq=kfc#reviews`;
接下来,我们编写一个函数以从页面上获取评论:
async function getReviewsFromPage(page) {
...
}
然后,我们从页面上下文(使用koude14方法)获取信息,然后将其保存在返回的对象中:
return await page.evaluate(() => ({
...
}));
接下来,我们从所有"section[aria-label='Recommended Reviews'] div > ul > li"选择器(koude17方法)返回一个新数组(koude15方法):
let isAds = false;
return Array.from(document.querySelectorAll("section[aria-label='Recommended Reviews'] div > ul > li")).map((el) => {
...
});
要使返回的结果对象我们需要在所有分辨率中获得thumbnails。然后,我们获得了最后一个分辨率链接 - 这是最好的:
const thumbnails = el.querySelector("div > a > img").getAttribute("srcset")?.split(", ");
const bestResolutionThumbnail = thumbnails && thumbnails[thumbnails.length - 1].split(" ")[0];
接下来,我们需要使用下一个方法获取并返回页面的不同部分:
return {
user: {
name: el.querySelector(".user-passport-info span > a")?.textContent,
link: `https://www.yelp.com${el.querySelector(".user-passport-info span > a")?.getAttribute("href")}`,
thumbnail: bestResolutionThumbnail,
address: el.querySelector(".user-passport-info div > span")?.textContent,
friends: el.querySelector("[aria-label='Friends'] span > span")?.textContent,
photos: el.querySelector("[aria-label='Photos'] span > span")?.textContent,
reviews: el.querySelector("[aria-label='Reviews'] span > span")?.textContent,
eliteYear: el.querySelector(".user-passport-info div > a > span")?.textContent,
},
comment: {
text: el.querySelector("span[lang]")?.textContent,
language: el.querySelector("span[lang]")?.getAttribute("lang"),
},
date: el.querySelector(":scope > div > div:nth-child(2) div:nth-child(2) > span")?.textContent,
rating: el.querySelector("span > div[role='img']").getAttribute("aria-label")?.split(" ")?.[0],
photos: Array.from(el.querySelectorAll(":scope > div > div:nth-child(5) > div > div")).map((el) => {
const captionString = el.querySelector("img").getAttribute("alt");
const captionStart = captionString.indexOf(".");
const caption = captionStart !== -1 ? captionString.slice(captionStart + 2) : undefined;
return {
link: el.querySelector("img").getAttribute("src"),
caption,
};
}),
feedback: {
useful: el.querySelector(":scope > div > div:last-child span:nth-child(1) button span > span > span")?.textContent,
funny: el.querySelector(":scope > div > div:last-child span:nth-child(2) button span > span > span")?.textContent,
cool: el.querySelector(":scope > div > div:last-child span:nth-child(3) button span > span > span")?.textContent,
},
};
接下来,编写一个函数来控制浏览器并获取信息:
async function getReviews() {
...
}
首先,在此功能中,我们需要使用puppeteer.launch({options})方法来定义browser当前的options,例如headless: true和args: ["--no-sandbox", "--disable-setuid-sandbox"]。
这些选项意味着我们将headless模式和数组与arguments一起使用,我们用来允许在线IDE中启动浏览器流程。然后我们打开一个新的page:
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
接下来,我们更改默认值(30 sec)等待选择器的时间到60000毫秒(1分钟)与koude32方法缓慢连接,请使用koude34方法访问URL,并定义reviews阵列:
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
const reviews = [];
接下来,我们使用while loop(koude36),其中我们使用koude38方法等待直到选择器加载,将页面上的结果添加到reviews array(使用koude40)(使用koude40),检查下一页按钮是否存在于页面上(koude41方法)和结果的数量少于reviewsLimit我们在下一页按钮元素上单击(koude43方法),等待3秒(使用koude44方法),否则我们停止循环(使用koude45)。
。
。
while (true) {
await page.waitForSelector("section[aria-label='Recommended Reviews'] div > ul");
reviews.push(...(await getReviewsFromPage(page)));
const isNextPage = await page.$("a[aria-label='Next']");
if (!isNextPage || reviews.length >= reviewsLimit) break;
await page.click("a[aria-label='Next']");
await page.waitForTimeout(3000);
}
最后,我们关闭浏览器,然后返回收到的数据:
await browser.close();
return reviews;
现在我们可以启动我们的解析器:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
输出
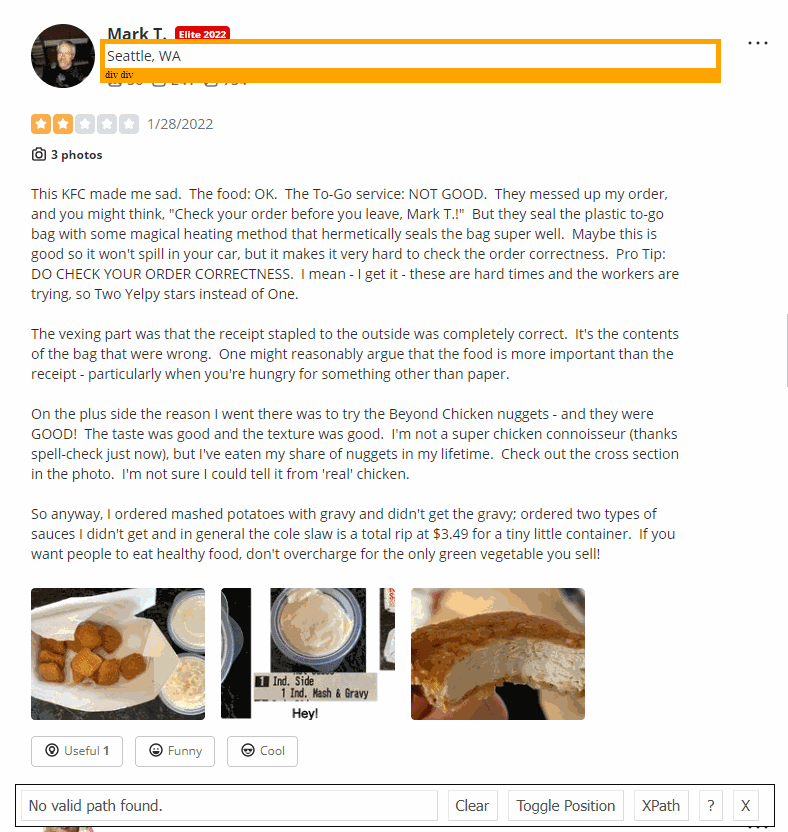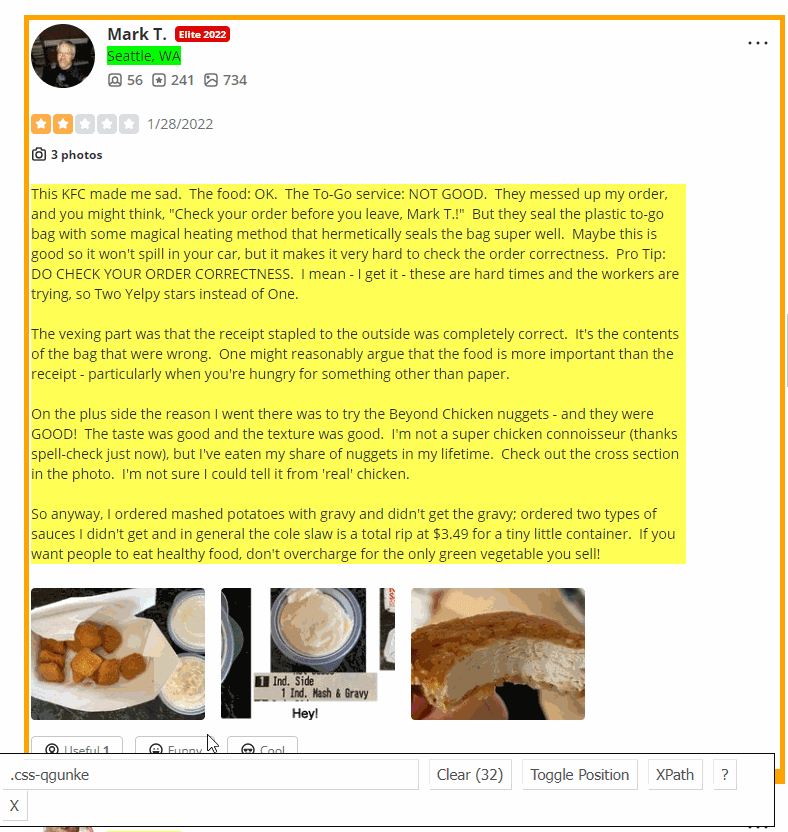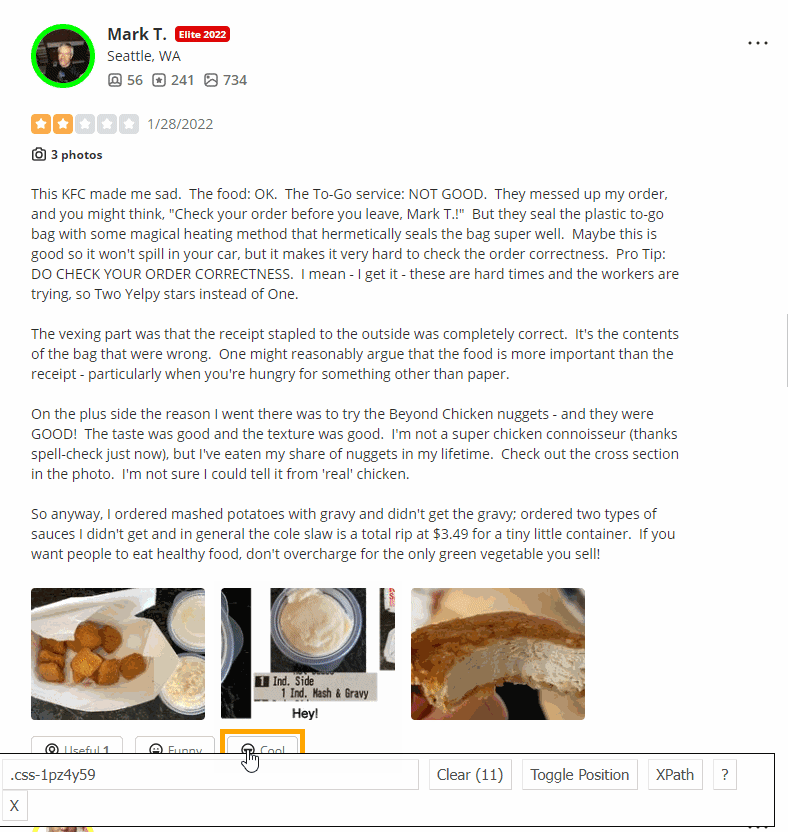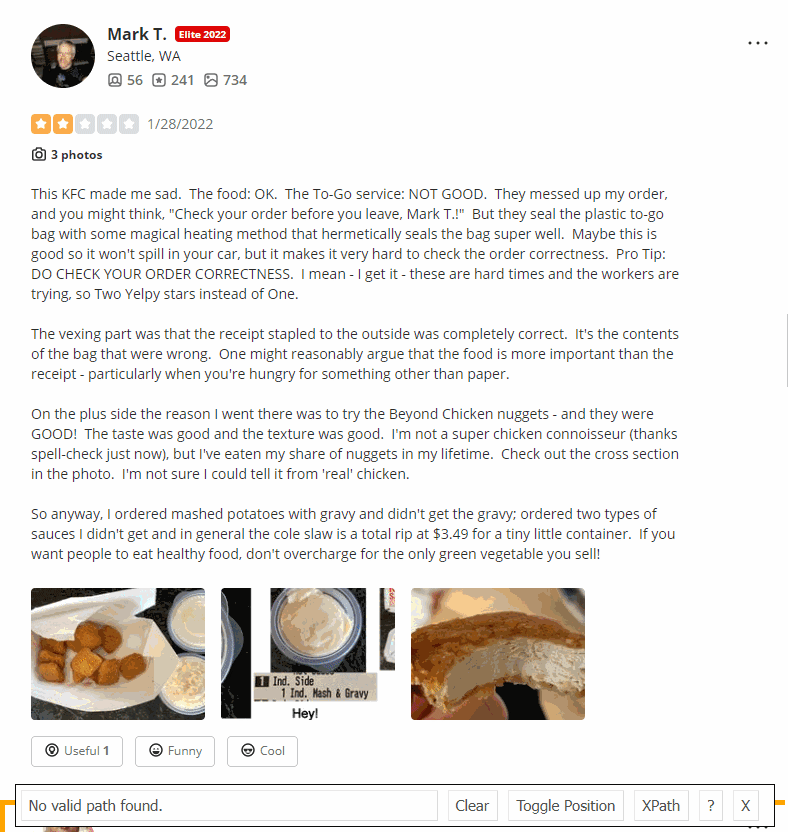
[
{
"user":{
"name":"Mark T.",
"link":"https://www.yelp.com/user_details?userid=z44H_fDiNpvH-B8B_vBnBA",
"thumbnail":"https://s3-media0.fl.yelpcdn.com/photo/9n6QdxRSINg3RZhoy0vw7w/ms.jpg",
"address":"Seattle, WA",
"friends":"56",
"photos":"734",
"reviews":"241",
"eliteYear":"Elite 2022"
},
"comment":{
"text":"`This KFC made me sad. The food: OK. The To-Go service: NOT GOOD. They messed up my order, and you might think, \"Check your order before you leave, Mark T.!\" But they seal the plastic to-go bag with some magical heating method that hermetically seals the bag super well. Maybe this is good so it won't spill in your car, but it makes it very hard to check the order correctness. Pro Tip: DO CHECK YOUR ORDER CORRECTNESS. I mean - I get it - these are hard times and the workers are trying, so Two Yelpy stars instead of One.The vexing part was that the receipt stapled to the outside was completely correct. It's the contents of the bag that were wrong. One might reasonably argue that the food is more important than the receipt - particularly when you're hungry for something other than paper.On the plus side the reason I went there was to try the Beyond Chicken nuggets - and they were GOOD! The taste was good and the texture was good. I'm not a super chicken connoisseur (thanks spell-check just now), but I've eaten my share of nuggets in my lifetime. Check out the cross section in the photo. I'm not sure I could tell it from 'real' chicken. So anyway, I ordered mashed potatoes with gravy and didn't get the gravy; ordered two types of sauces I didn't get and in general the cole slaw is a total rip at $3.49 for a tiny little container. If you want people to eat healthy food, don't overcharge for the only green vegetable you sell!`",
"language":"en"
},
"date":"1/28/2022",
"rating":"2",
"photos":[
{
"link":"https://s3-media0.fl.yelpcdn.com/bphoto/CsgT6CJlTEC9tuqWgw9hLg/180s.jpg",
"caption":"The Beyond Chicken. Best when freshly hot."
},
{
"link":"https://s3-media0.fl.yelpcdn.com/bphoto/I_v-WDBLYBTc7z0O8GJCVQ/180s.jpg",
"caption":"The sadness of my KFC trip."
},
{
"link":"https://s3-media0.fl.yelpcdn.com/bphoto/qMGmBmZPxzD0pQfhfvleJg/180s.jpg",
"caption":"That texture! Might even fool chicken-philes!"
}
],
"feedback":{
"useful":" 1"
}
},
...and other results
]
usuingaoqian42 from serpapi
本节是为了显示DIY解决方案与我们的解决方案之间的比较。
最大的区别是您不需要从头开始创建解析器并维护它。
也有可能在Google的某个时候阻止请求,我们在后端处理它,因此无需弄清楚如何自己做或弄清楚要使用哪个验证码,代理提供商。
首先,我们需要安装koude46:
npm i google-search-results-nodejs
这是full code example,如果您不需要说明:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(process.env.API_KEY); //your API key from serpapi.com
const reviewsLimit = 50; // hardcoded limit for demonstration purpose
const params = {
engine: "yelp_reviews", // search engine
device: "desktop", //Parameter defines the device to use to get the results. It can be set to "desktop" (default), "tablet", or "mobile"
place_id: "UON0MxZGG0cgsU5LYPjJbg", //Parameter defines the Yelp ID of a place
};
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
const getResults = async () => {
const reviews = [];
while (true) {
const json = await getJson();
if (json.reviews) {
reviews.push(...json.reviews);
params.start ? (params.start += 10) : (params.start = 10);
} else break;
if (reviews.length >= reviewsLimit) break;
}
return reviews;
};
getResults().then((result) => console.dir(result, { depth: null }));
代码说明
首先,我们需要从koude46库中声明SerpApi并使用SerpApi的API键定义新的search实例:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(API_KEY);
接下来,我们编写用于提出请求的必要参数,并设置要接收多少结果(reviewsLimit常数):
ð注意:您可以从我们的serpapi解决方案部分中的Web scraping Yelp Organic Results with Nodejs博客文章中获取位置ID。
const reviewsLimit = 50; // hardcoded limit for demonstration purpose
const params = {
engine: "yelp_reviews", // search engine
device: "desktop", //Parameter defines the device to use to get the results. It can be set to "desktop" (default), "tablet", or "mobile"
place_id: "UON0MxZGG0cgsU5LYPjJbg", //Parameter defines the Yelp ID of a place
};
接下来,我们从Serpapi库中包装搜索方法,以便进一步处理搜索结果:
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
最后,我们声明了从页面获取数据并返回的函数getResult:
const getResults = async () => {
...
};
在此功能中,我们需要声明一个空的reviews数组并使用koude36循环获取json,添加每个页面中的reviews结果,并设置下一页启动索引(to params.start值)。如果页面上没有更多结果,或者收到的结果的数量超过reviewsLimit,我们会停止循环(使用koude45)并返回reviews数组:
const reviews = [];
while (true) {
const json = await getJson();
if (json.reviews) {
reviews.push(...json.reviews);
params.start ? (params.start += 10) : (params.start = 10);
} else break;
if (reviews.length >= reviewsLimit) break;
}
return reviews;
之后,我们运行getResults函数并使用koude61方法在控制台中打印所有接收的信息,该方法使您可以使用带有必要参数的对象来更改默认输出选项:
getResults().then((result) => console.dir(result, { depth: null }));
输出
[
{
"user":{
"name":"Lesjar M.",
"user_id":"pQJfTSDC-zEdcrU0K_gONw",
"link":"https://www.yelp.com/user_details?userid=pQJfTSDC-zEdcrU0K_gONw",
"thumbnail":"https://s3-media0.fl.yelpcdn.com/photo/k5o32UV20u44mH_W7pPx_A/60s.jpg",
"address":"Northwest Everett, Everett, WA",
"photos":1,
"reviews":2
},
"comment":{
"text":"I just ordered a chicken sandwich and fries. Got it delivered through door dash. The classic chicken sandwich is $8.99 by itself. Which is a decently priced chicken sandwich. When I got the order, and opened the bag. I grabbed the sandwich and I literally thought the driver ate half the sandwich because it was the smallest, pathetic, and sad looking piece of crap, posing as a chicken sandwich I've ever seen. It looked no where near the same size as the picture projected it to be. The picture was a full size chicken sandwich. What was handed to me had to have been an imposter. I'm so angry. I feel like I was totally ripped off. Money is tight, but thought I'd splurge since I'm going back to work tomorrow. I will never eat at KFC again. I've never been so ripped off! (If I could I'd give half a star!)",
"language":"en"
},
"date":"2/8/2022",
"rating":1,
"tags":[
"1 photo"
],
"photos":[
{
"link":"https://s3-media0.fl.yelpcdn.com/bphoto/95M1boh80dnsCiBcPbyrAQ/o.jpg",
"caption":"KFC "Classic Chicken Sandwich."",
"uploaded":"February 8, 2022"
}
],
"feedback":{
"funny":1,
"cool":1
}
},
...and other results
]
链接
如果您想在此博客文章中添加其他功能,或者您想查看Serpapi,write me a message的某些项目。
添加Feature Requestð«或Bugð