本文来自bmf-tech.com - Improving Code Performance Starting with Go。
的第9天从GO开始提高代码的性能
当我决定提高自制http路由器goblin的性能时,我试图在GO中进行绩效改进,因此我写了有关方法和练习的努力。
先决条件
我敢肯定,更深入的调整需要更多的知识,但是我只列出所需的最低要求。
- 垃圾收集
- 一种自动释放不再需要程序分配的记忆区域的函数。
- 内存区域
- 文本区域
- 可以存储将程序转换为机器语言的区域
- 堆栈区域
- 在程序执行下分配的内存区域内存区域
- 在运行时固定大小的数据
- 自动发布e.g。,当功能完成执行并且不再需要)
- ex。参数,返回值,临时变量等。
- 堆区
- 程序执行期间分配的内存区域
- 大小由动态确定的数据
- 受垃圾收集的约束
- 静态区域
- 程序执行期间分配的内存区域
- 分配直到终止程序
- ex。全局变量,静态变量等
- 文本区域
绩效提高方法
假设是有必要提高性能(是否值得牺牲可读性,我们可以确定该应用程序是瓶颈,等等)需要。
提高代码性能的一些方法包括如下:
- 算法优化
- 数据结构的优化
- 使用缓存
- 并行处理的应用
- 编译优化
有很多事情想到,但是在实施改进之前,应进行测量和分析。
(假定对绩效提高的需求比测量更重要,但这取决于每个人的需求,并且在这里不讨论。)
我们将在GO中介绍一些用于测量和分析的软件包和工具。
基准
GO在标准软件包测试中包含Benchmarks以获得代码的基准。
您可以运行命令go test -bench=. -benchmem来获得基准。
package main
import (
"math/rand"
"testing"
)
func BenchmarkRandIn(b *testing.B) {
for i := 0; i < b.N; i++ { // b.N automatically specifies the number of times the benchmark can be trusted
rand.Int() // Function to be measured
}
}
输出结果看起来像这样。
goos: darwin
goarch: amd64
pkg: bmf-san/go-perfomance-tips
cpu: VirtualApple @ 2.50GHz
BenchmarkRandIn-8 87550500 13.53 ns/op 0 B/op 0 allocs/op
PASS
ok bmf-san/go-perfomance-tips 1.381s
可以从中读取的基准结果如下:
- 87550500
- 函数执行数
- 执行次数越高,认为性能越好
- 13.53 ns / on
- 每个功能执行所需的时间
- 更少的时间被认为是更好的性能
- 0 b / on
- 分配每个功能执行的内存大小
- 数字越小,性能越好被认为
- 0 Allocs/op
- 每个功能执行的内存分配数
- 分配次数越少,性能越好
go可以以这种方式轻松进行基准测试。
有关其他GO基准功能,请参见文档。
Benchmarks
包装benchstat是比较基准结果的好工具,显示了基准结果改进的百分比。包装benchstat是比较基准结果的好工具,因为它显示了改进的百分比。
我管理的软件包bmf-san/goblin已纳入CI,以便可以在提交之前和之后比较结果。
// This is an example where nothing has improved...
go test -bench . -benchmem -count 1 > new.out
benchstat old.out new.out
name old time/op new time/op delta
Static1-36 248ns ± 0% 246ns ± 0% ~ (p=1.000 n=1+1)
Static5-36 502ns ± 0% 495ns ± 0% ~ (p=1.000 n=1+1)
Static10-36 874ns ± 0% 881ns ± 0% ~ (p=1.000 n=1+1)
WildCard1-36 1.60µs ± 0% 1.50µs ± 0% ~ (p=1.000 n=1+1)
WildCard5-36 4.49µs ± 0% 4.92µs ± 0% ~ (p=1.000 n=1+1)
WildCard10-36 7.68µs ± 0% 7.58µs ± 0% ~ (p=1.000 n=1+1)
Regexp1-36 1.38µs ± 0% 1.48µs ± 0% ~ (p=1.000 n=1+1)
Regexp5-36 4.30µs ± 0% 4.11µs ± 0% ~ (p=1.000 n=1+1)
Regexp10-36 7.66µs ± 0% 7.18µs ± 0% ~ (p=1.000 n=1+1)
绝对不允许性能退化!在这种情况下,使用机制使CI失败可能是一个好主意。
如果要通过查看这种基准的结果来检查实际的内存分配,则可以通过构建选项进行检查。
package main
import "fmt"
// Run build with go build -o example -gcflags '-m' gcflagsexample.go
func main() {
a := "hello"
b := "world"
fmt.Println(a + b)
}
运行go build -o example -gcflags '-m' gcflagsexample.go产生以下输出。
# command-line-arguments
./gcflagsexample.go:9:13: inlining call to fmt.Println
./gcflagsexample.go:9:13: ... argument does not escape
./gcflagsexample.go:9:16: a + b escapes to heap
./gcflagsexample.go:9:16: a + b escapes to heap
这是一个显而易见的示例,但这也是一种有用的分析方法,因为可以通过以这种方式识别对堆的分配并减少堆的分配来改善内存分配。
。分析
GO有一个称为pprof的工具,可以分析瓶颈在功能级别的位置。
package main
import (
"sort"
"testing"
)
func sortAlphabetically() {
s := []string{"abc", "aba", "cba", "acb"}
sort.Strings(s)
}
func BenchmarkSortAlphabetically(b *testing.B) {
for i := 0; i < b.N; i++ {
sortAlphabetically()
}
}
如果您想查看CPU配置文件,请运行以下内容。
go test -test.bench=BenchmarkSortAlphabetically -cpuprofile cpu.out && go tool pprof -http=":8888" cpu.out

如果要查看内存配置文件,请运行以下内容。
go test -test.bench=BenchmarkSortAlphabetically profilingexample_test.go -memprofile mem.out && go tool pprof -http=":8889" mem.out

利用pprof的UI使确定瓶颈在此过程中的位置更加容易。
实践
提出了改进goblin(自制HTTP路由器的goblin)的示例。
主题上的公关在这里。
Reduce the memory allocation by refactoring explodePath method #68
goblin是一个HTTP路由器,可与基于Tri-Tree的NET/HTTP接口配合使用。
至于功能,它具有路由所必需的最小值。
参见goblin#features
基准
首先,我们运行基准测试以衡量性能。
go test -bench=. -cpu=1 -benchmem
基准测试对于每个测试案例都有大约三种模式:静态路由(例如 /foo /bar),动态路由(例如 /foo /:bar)和使用正则表达式的路由(例如 /foo /: bar [^\ d+$])。
路由过程涉及
- 将数据放入树结构(定义路由)
- 从树结构中搜索数据(基于请求的路径返回数据)
在此测试案例中,仅测量后者。
输出结果如下:
goos: darwin
goarch: amd64
pkg: github.com/bmf-san/goblin
cpu: VirtualApple @ 2.50GHz
BenchmarkStatic1 5072353 240.1 ns/op 128 B/op 4 allocs/op
BenchmarkStatic5 2491546 490.0 ns/op 384 B/op 6 allocs/op
BenchmarkStatic10 1653658 729.6 ns/op 720 B/op 7 allocs/op
BenchmarkWildCard1 1602606 747.3 ns/op 456 B/op 9 allocs/op
BenchmarkWildCard5 435784 2716 ns/op 1016 B/op 23 allocs/op
BenchmarkWildCard10 246729 5033 ns/op 1680 B/op 35 allocs/op
BenchmarkRegexp1 1647258 733.2 ns/op 456 B/op 9 allocs/op
BenchmarkRegexp5 456652 2641 ns/op 1016 B/op 23 allocs/op
BenchmarkRegexp10 251998 4780 ns/op 1680 B/op 35 allocs/op
PASS
ok github.com/bmf-san/goblin 14.304s
可以将几个趋势读取到执行次数,每次运行的执行次数,每次运行的内存大小以及内存分配的数量中。
我个人担心即使是用于静态路由也正在发生内存分配。 (其他HTTP路由器基准显示0个Allocs。)
分析
接下来,使用PPROF获得配置文件。
这次,我们只专注于内存以获得配置文件。
go test -bench . -memprofile mem.out && go tool pprof -http=":8889" mem.out
图形输出结果。
呢pprof_graph
{kind=link}
我们可以看到,最大框的过程(使用最多的内存)是explodePath。
即使您查看顶部(按照最长的执行时间列表),explodePath也位于列表的顶部。
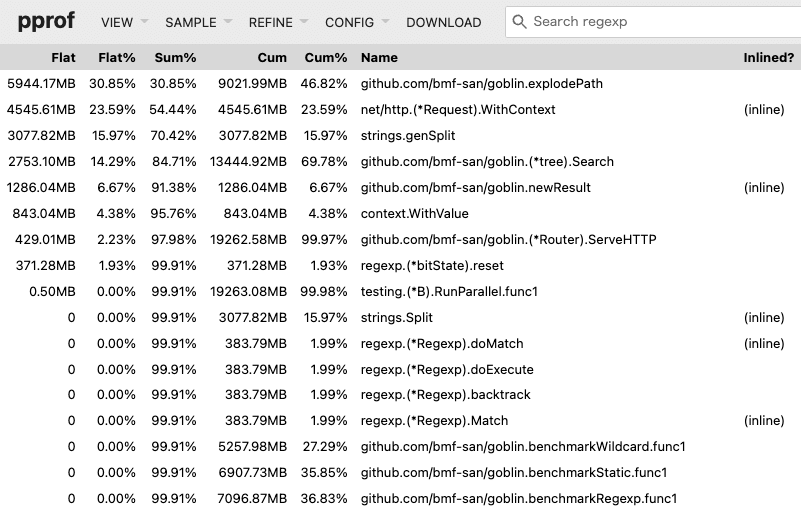
flat是功能的处理时间,暨是包括等待时间的处理时间。
此外,检查源以查看功能中的位置处理实际上很重。

由于Search是负责路由器匹配过程的核心过程,所以我认为这将是那里的瓶颈,但是事实证明其中一个特定的过程explodePath是瓶颈。
调整
explodePath的过程是由/拆分接收的字符串,并将其返回为[]字符串类型。
// explodePath removes an empty value in slice.
func explodePath(path string) []string {
s := strings.Split(path, pathDelimiter)
var r []string
for _, str := range s {
if str != "" {
r = append(r, str)
}
}
return r
}
还包括测试代码以方便理解规格。
func TestExplodePath(t *testing.T) {
cases := []struct {
actual []string
expected []string
}{
{
actual: explodePath(""),
expected: nil,
},
{
actual: explodePath("/"),
expected: nil,
},
{
actual: explodePath("//"),
expected: nil,
},
{
actual: explodePath("///"),
expected: nil,
},
{
actual: explodePath("/foo"),
expected: []string{"foo"},
},
{
actual: explodePath("/foo/bar"),
expected: []string{"foo", "bar"},
},
{
actual: explodePath("/foo/bar/baz"),
expected: []string{"foo", "bar", "baz"},
},
{
actual: explodePath("/foo/bar/baz/"),
expected: []string{"foo", "bar", "baz"},
},
}
for _, c := range cases {
if !reflect.DeepEqual(c.actual, c.expected) {
t.Errorf("actual:%v expected:%v", c.actual, c.expected)
}
}
}
由于[[]字符串类型中定义的变量r没有定义能力,因此可以推断内存效率可能很差。
以下是一个基准测试,并将附加的结果添加到准备验证的切片中。
package main
import "testing"
func BenchmarkSliceLen0Cap0(b *testing.B) {
var s []int
b.StartTimer()
for i := 0; i < b.N; i++ {
s = append(s, i)
}
b.StopTimer()
}
func BenchmarkSliceLenN(b *testing.B) {
var s = make([]int, b.N)
b.StartTimer()
for i := 0; i < b.N; i++ {
s = append(s, i)
}
b.StopTimer()
}
func BenchmarkSliceLen0CapN(b *testing.B) {
var s = make([]int, 0, b.N)
b.StartTimer()
for i := 0; i < b.N; i++ {
s = append(s, i)
}
b.StopTimer()
}
goos: darwin
goarch: amd64
pkg: example.com
cpu: VirtualApple @ 2.50GHz
BenchmarkSliceLen0Cap0 100000000 11.88 ns/op 45 B/op 0 allocs/op
BenchmarkSliceLenN 78467056 23.60 ns/op 65 B/op 0 allocs/op
BenchmarkSliceLen0CapN 616491007 5.057 ns/op 8 B/op 0 allocs/op
PASS
ok example.com 6.898s
bmf@bmfnoMacBook-Air:~/Desktop$
这个结果表明,通过指定容量,代码可能更有效。
因此,修改explodePath如下。
func explodePath(path string) []string {
s := strings.Split(path, "/")
// var r []string
r := make([]string, 0, strings.Count(path, "/")) // Specify capacity
for _, str := range s {
if str != "" {
r = append(r, str)
}
}
return r
}
更深入和改进的实施。
func explodePath(path string) []string {
splitFn := func(c rune) bool {
return c == '/'
}
return strings.FieldsFunc(path, splitFn)
}
我们将将基准测试与三种模式进行比较:原始explodePath实施,具有保留切片容量的实现以及使用strings.FieldFunc的实施。
package main
import (
"strings"
"testing"
)
func explodePath(path string) []string {
s := strings.Split(path, "/")
var r []string
for _, str := range s {
if str != "" {
r = append(r, str)
}
}
return r
}
func explodePathCap(path string) []string {
s := strings.Split(path, "/")
r := make([]string, 0, strings.Count(path, "/"))
for _, str := range s {
if str != "" {
r = append(r, str)
}
}
return r
}
func explodePathFieldsFunc(path string) []string {
splitFn := func(c rune) bool {
return c == '/'
}
return strings.FieldsFunc(path, splitFn)
}
func BenchmarkExplodePath(b *testing.B) {
paths := []string{"", "/", "///", "/foo", "/foo/bar", "/foo/bar/baz"}
b.StartTimer()
for i := 0; i < b.N; i++ {
for _, v := range paths {
explodePath(v)
}
}
b.StopTimer()
}
func BenchmarkExplodePathCap(b *testing.B) {
paths := []string{"", "/", "///", "/foo", "/foo/bar", "/foo/bar/baz"}
b.StartTimer()
for i := 0; i < b.N; i++ {
for _, v := range paths {
explodePathCap(v)
}
}
b.StopTimer()
}
func BenchmarkExplodePathFieldsFunc(b *testing.B) {
paths := []string{"", "/", "///", "/foo", "/foo/bar", "/foo/bar/baz"}
b.StartTimer()
for i := 0; i < b.N; i++ {
for _, v := range paths {
explodePathFieldsFunc(v)
}
}
b.StopTimer()
}
goos: darwin
goarch: amd64
pkg: example.com
cpu: VirtualApple @ 2.50GHz
BenchmarkExplodePath 1690340 722.2 ns/op 432 B/op 12 allocs/op
BenchmarkExplodePathCap 1622161 729.5 ns/op 416 B/op 11 allocs/op
BenchmarkExplodePathFieldsFunc 4948364 239.5 ns/op 96 B/op 3 allocs/op
PASS
ok example.com 5.685s
使用strings.PathFieldFunc实施似乎具有最佳性能,因此被采用。
衡量有效性
在改进explodePath的实现后检查结果。
基准
# Before
goos: darwin
goarch: amd64
pkg: github.com/bmf-san/goblin
cpu: VirtualApple @ 2.50GHz
BenchmarkStatic1 5072353 240.1 ns/op 128 B/op 4 allocs/op
BenchmarkStatic5 2491546 490.0 ns/op 384 B/op 6 allocs/op
BenchmarkStatic10 1653658 729.6 ns/op 720 B/op 7 allocs/op
BenchmarkWildCard1 1602606 747.3 ns/op 456 B/op 9 allocs/op
BenchmarkWildCard5 435784 2716 ns/op 1016 B/op 23 allocs/op
BenchmarkWildCard10 246729 5033 ns/op 1680 B/op 35 allocs/op
BenchmarkRegexp1 1647258 733.2 ns/op 456 B/op 9 allocs/op
BenchmarkRegexp5 456652 2641 ns/op 1016 B/op 23 allocs/op
BenchmarkRegexp10 251998 4780 ns/op 1680 B/op 35 allocs/op
PASS
ok github.com/bmf-san/goblin 14.304s
# After
go test -bench=. -cpu=1 -benchmem -count=1
goos: darwin
goarch: amd64
pkg: github.com/bmf-san/goblin
cpu: VirtualApple @ 2.50GHz
BenchmarkStatic1 10310658 117.7 ns/op 32 B/op 1 allocs/op
BenchmarkStatic5 4774347 258.1 ns/op 96 B/op 1 allocs/op
BenchmarkStatic10 2816960 435.8 ns/op 176 B/op 1 allocs/op
BenchmarkWildCard1 1867770 653.4 ns/op 384 B/op 6 allocs/op
BenchmarkWildCard5 496778 2484 ns/op 928 B/op 13 allocs/op
BenchmarkWildCard10 258508 4538 ns/op 1560 B/op 19 allocs/op
BenchmarkRegexp1 1978704 608.4 ns/op 384 B/op 6 allocs/op
BenchmarkRegexp5 519240 2394 ns/op 928 B/op 13 allocs/op
BenchmarkRegexp10 280741 4309 ns/op 1560 B/op 19 allocs/op
PASS
ok github.com/bmf-san/goblin 13.666s
比较改进之前和之后,我们可以说总体趋势是改善的。
分析
pprof的图。

pprof的顶部。

您可以看到瓶颈已移至strings.FieldsFunc,在explodePath中被称为
进一步的改进
不幸的是,可以说,数据结构和算法没有显着改进,因此没有显着的改进。
我感觉到他们现在使用的数据结构和算法仍然很难使用。 (我看到了其他使用更多高级树的路由器,所以我想那是真的...)
这有点脱离话题,但是我创建了一个与其他路由器进行比较的基准标记,看看是否可以得到一些提示以进行改进。
比较它们并查看它们的破烂很有趣。
我想通过研究其他路由器实现,学习高级树结构等来改进它,我以前没有做过。
概括
- GO使基准测试和分析变得容易。
- 不要猜测,测量!
- 很难获得较小的改进(是的)
参考
- github.com - google/pprof
- github.com - dgryski/go-perfbook
- dave.cheney.net - High Perfomance Go Workshop
- go.dev - Profiling Go Programs
- go.dev - A Guide to the Go Garbage Collector
- developer.so-tech.co.jp
- segment.com - Allocation efficiency in high-performance Go services
- blog.logrocket.com - Benchmarking in Golang: Improving function performance
- medium.com - Go code refactoring : the 23x performance hunt
- medium.com - Go言語のプロファイリングツール、pprofのWeb UIがめちゃくちゃ便利なので紹介する
- teivah.medium.com - Good Code vs Bad Code in Golang
- hnakamur.github.io - goで書いたコードがヒープ割り当てになるかを確認する方法
- glog.kazu69.net - Goのメモリ管理を眺めてみた
- dsas.blog.klab.org - Goでアロケーションに気をつけたコードを書く方法
- tech.speee.jp - Goのロギングライブラリから見たゼロアロケーション
- kawasin73.hatenablog.com - メモリアロケーションに対する罪悪感