索引是提高阅读性能的一种方式,但也使写作的性能变得更糟,因此请考虑根据用例中的应用程序中使用索引。
为了证明,我将使用带有1000万记录的orders表:
create table orders (
id serial primary key,
total integer, -- unit: usd
user_id integer,
created_at date
);
然后生成:
total:范围内的随机数(1-10k)
user_id:范围内的随机数(1-100k)
created_at:范围中的随机日期(2002-2022)(20年)
orders表应该看起来像这样:
id | total | user_id | created_at
----+-------+---------+------------
1 | 7492 | 9968 | 2021-03-20
2 | 3084 | 81839 | 2008-03-20
3 | 3523 | 85845 | 2018-12-22
...
没有索引:
让我们使用explain analyze查看query plan以获取此查询:
explain analyze select sum(total) from orders
where extract(year from created_at) = 2013;

查询将按照本计划执行,以内而外的顺序:
Finalize Aggregate
└── Gather
└── Partial Aggregate
└── Parallel Seq Scan
因此,PostgreSQL将与2名工人并行进行顺序扫描,然后对于每个工人,它将执行一个Partial Aggregation (sum function),然后Gather工人的结果,然后进行Finalized Aggregation (sum function)。
在平行的SEQ扫描节点中,对每个循环进行3个循环,扫描3,333,333行(= 3,166,526 + 166,807)
要了解Partial Aggregate如何与Finalize Aggregate合作,请阅读有关PARALLEL-AGGREGATION和PARALLEL-SEQ-SCAN
使用索引:
索引是为特定查询而设计的,所以让我们考虑两种为两个不同查询创建索引的方法,但它们具有相同的目的。
在表达式上使用索引:
现在在created_at列上创建索引,因为我们在查询上使用extract(year from created_at)表达式,因此我们也需要在索引上使用该表达式(阅读有关indexes on expression6的更多信息):
create index my_index on orders (extract(year from created_at));
explain analyze select sum(total) from orders
where extract(year from created_at) = 2013;

Aggregate
└── Bitmap Heap Scan
└── Bitmap Index Scan
现在,它使用my_index进行扫描,并且执行时间从1441.190ms减少到227.388ms(84,22%),这很重要。
在列上使用索引:
还有另一种方法可以使用between操作员计算2013年的订单总价值
explain analyze select sum(total) from orders
where created_at between '2013-01-01' and '2013-12-31';
使用此查询,我们只需要在created_at列上创建索引:
create index my_index_2 on orders(created_at);

Finalize Aggregate
└── Gather
└── Partial Aggregate
└── Parallel Bitmap Heap Scan
└── Bitmap Index Scan
使用这对索引 - 查询,它打开了平行的工人,并从1441.190ms降低到179.813ms(87,52%)。
什么是位图索引扫描和位图堆扫描?
让我们看一下表布局和页面布局:
-
“每个表格和索引都存储为页面数组。” -Ref
-
“ PostgreSQL中的所有索引都是次要索引,这意味着每个索引都与表的主要数据区域分开存储(这在PostgreSQL术语中称为表的
heap)。” -Ref
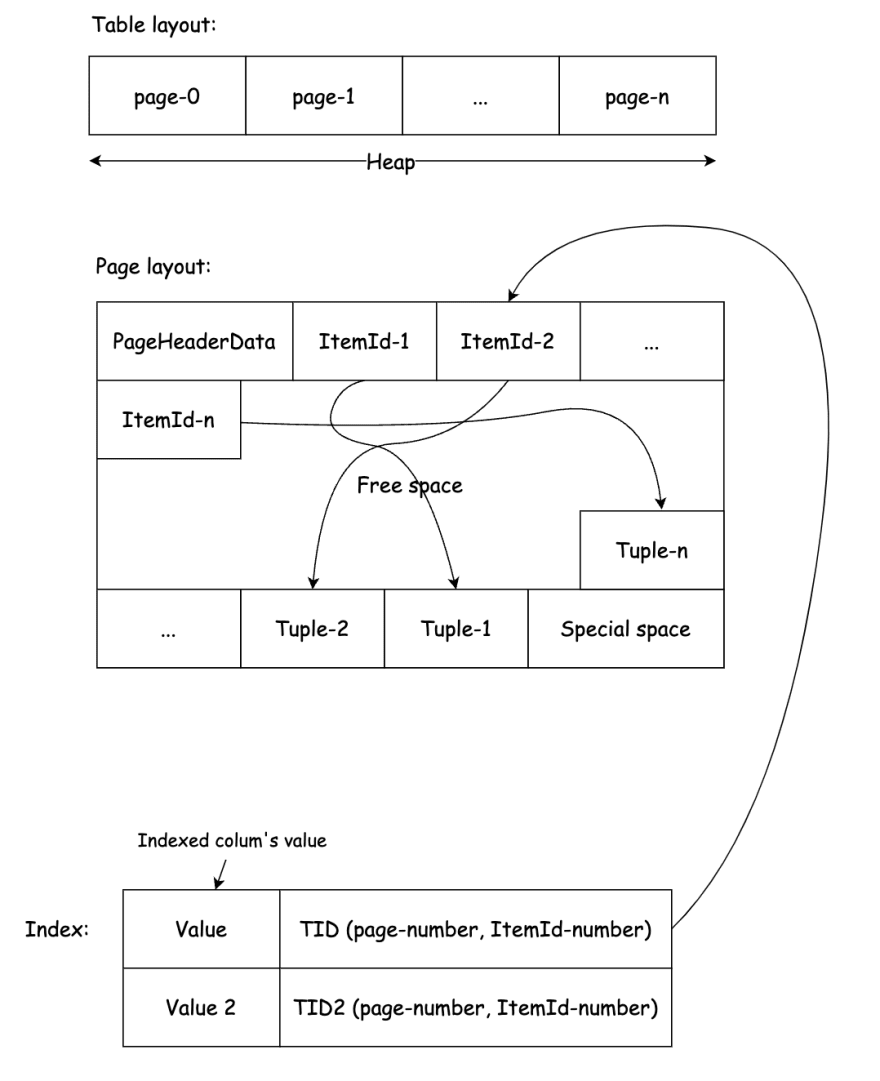
在bufpage.h中解释了页面布局:
-
ItemId或LinePointer:逻辑偏移该页面中的实际数据(Tuple - a row/record in table)。新数据(及其指针)将被添加到自由空间中。当自由空间满足时,该页面已满。 -
TID(元组标识符)或ItemPointer:一对(页/块号,LinePointer号),指向页面中的LinePointer/ItemId。
Bitmap Index Scan:在索引上扫描并创建位图。位图是一系列位,显示要获取哪个页面。首先,PostgreSQL将扫描索引以查找与条件匹配的值,然后将位图上的相应页面上的位转换为1。
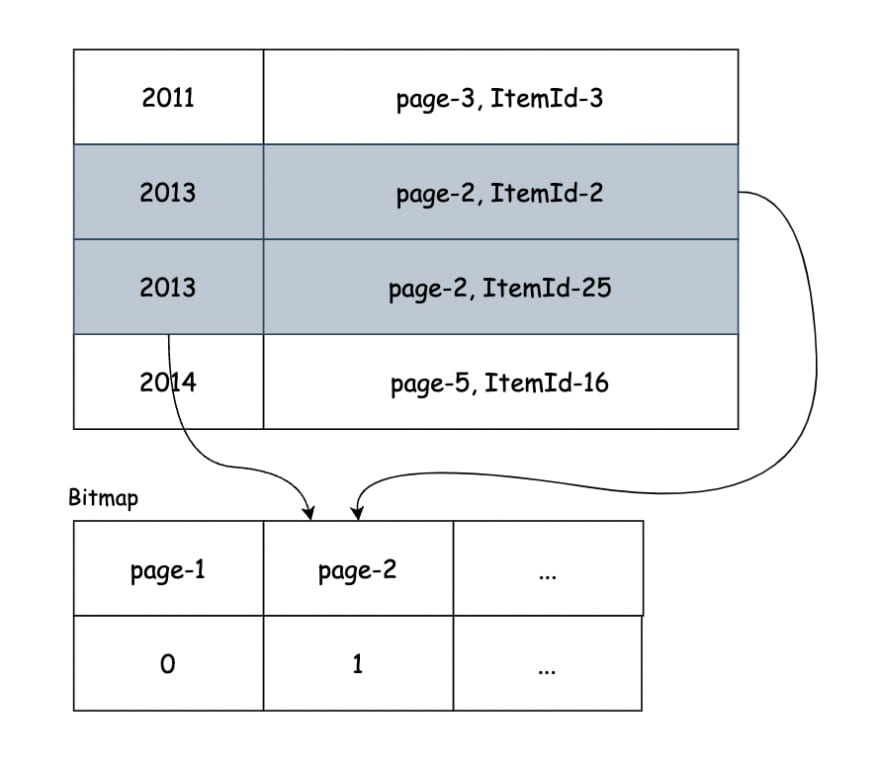
Bitmap Heap Scan:基于创建的位图,它将进行一个顺序磁盘读取到堆中以检索页面的标记为1,然后从该页面中,Recheck Cond将删除与条件不匹配的所有行。
对于索引上的每个匹配行,如果PostgreSQL对磁盘进行random IO access以获取整个行,它将非常慢,因为random I/O access比sequential I/O access慢。
因此,使用位图,它将批量读取数据(顺序IO访问),并确保未多次读取匹配的页面。
在索引(多列索引)中添加更多列:
在上面的示例上,我们看到了Bitmap Heap Scan,为了提高速度,我们可以将created和total添加到索引中以制造Index Only Scan
drop index my_index_2;
create index my_index_2 on orders(created_at, total);

因为查询需求在索引上的所有信息,因此它不需要在堆上获取数据。 179.813ms(位图堆扫描)现在已减少为69.775ms(仅索引扫描)。
多列索引中的列订单:
我们应该考虑索引的列顺序。让我们从(created_at,total)转换为(total,created_at),然后再试一次,我们将看到计划者不会使用索引,它将在整个表中使用Seq Scan:
:
drop index my_index_2;
create index my_index_2 on orders(total, created_at);

使用(created_at,total),该索引将首先按created_at对数据进行排序,然后按total进行排序:
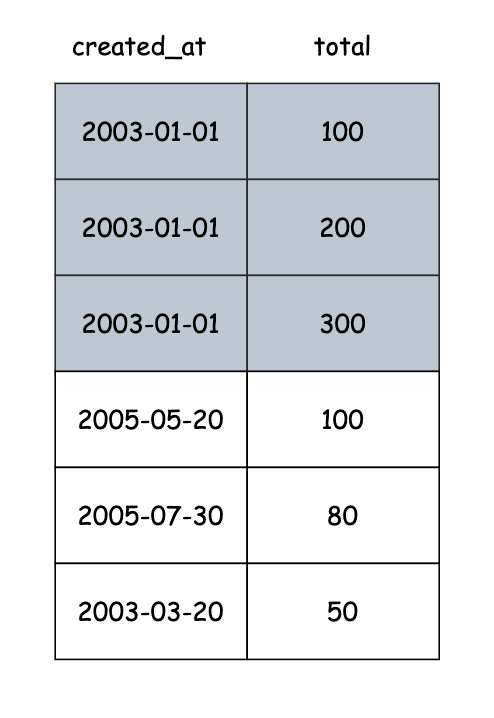
PostgreSQL将从左至右看索引。如果查询与索引顺序匹配,则计划器将使用索引。
在上面的查询中,计划者将首先进行分析,它将从条件开始 - >在2013年的日期找到所有行,然后在发现的行上进行聚合(sum)。但是total是索引上的第一列,而不是created_at,计划者无法跳过订单。
更多列:
让我们放下my_index_2并再次创建以重新排序列
drop index my_index_2;
create index my_index_2 on orders(created_at, total);
让我们做一个需要更多列的示例。如果我们想知道他们在2013年购买了多少人,那么user_id正在参与其中。
这就是我们想要的:
sum | user_id
-------+---------
32576 | 1
16119 | 2
18539 | 3
查询:
select sum(total), user_id from orders
where created_at between '2013-01-01' and '2013-12-31' group by user_id;
它将触发索引my_index_2,但仍需要在堆上读取数据以获取user_id数据。

让我们将user_id列添加到索引:
drop index my_index_2;
create index my_index_2 on orders(created_at, user_id, total);
现在使用Index Only Scan是因为所有信息都存储在索引上,执行时间从326.488ms减少到179.271ms:

索引上的列订单:
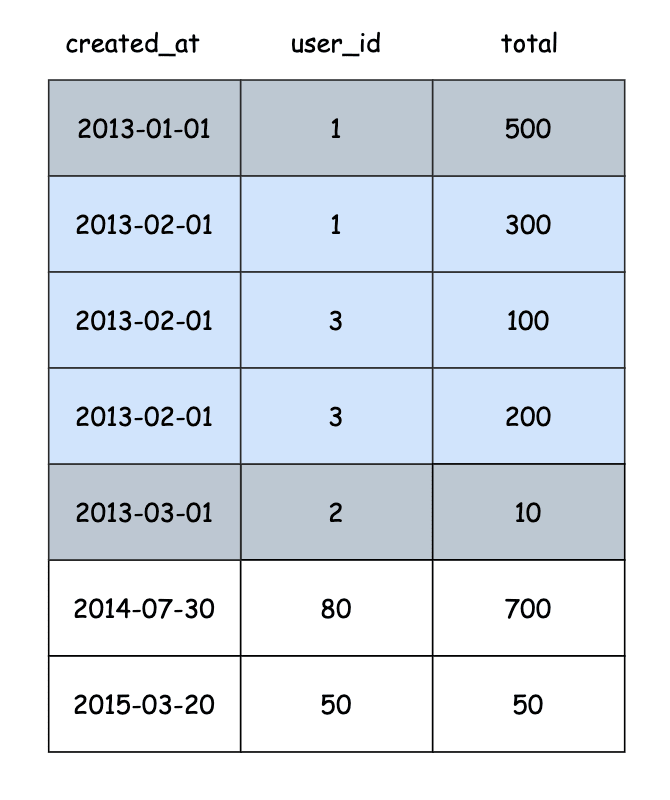
上面索引中的行由created_at对,如果两个行具有相同的created_at值,则它将按user_id对它们进行排序,依此类推。
如果我们想知道特定用户在2013年制作的日期和多少订单> 2000 USD:
select total, created_at from orders
where
total > 2000 and
user_id = 2 and
created_at between '2013-01-01' and '2013-12-31';

尽管where子句中的顺序与索引中的顺序不匹配,但PostgreSQL足够聪明,可以处理它。在这种情况下,其他数据库软件可能不会使用索引。
尝试其他列订单:
drop index my_index_2;
create index my_index_2 on orders(total, user_id, created_at);

发生了什么事?计划者使用Seq Scan而不是Index Only Scan,即使在查询上也没有功能,并且查询列顺序与索引匹配,为什么计划者不使用Index Only Scan?
要找出答案,请使用此命令阻止SEQ扫描,然后重试:
set enable_seqscan = off;

总成本估算:138388.73ms(seqscan)<242808.46ms(仅索引扫描),因此计划者
认为SEQ扫描比仅索引扫描快,在这种情况下估计可能不好。
要了解有关成本估算的更多信息,请阅读更多here。
而不是帮助估计变得更加准确,这与您在开发/分期/阶段模式中不同的许多因素有关。
让我们尝试其他订单:
user_id, created_at, total:
drop index my_index_2;
create index my_index_2 on orders(user_id, created_at, total);

user_id, total, created_at:
drop index my_index_2;
create index my_index_2 on orders(user_id, total, created_at);

哇,只要让user_id成为168ms的第一列,它减少到0.112ms〜0.188 ms。这是一个很大的进步。
在我的示例数据库中,它具有7,998,663 rows the total > 2000,但是特定用户仅在90〜100行附近具有100行,因此,如果首先用user_id对索引进行排序,它将消除几乎所有情况。
因此,在实际应用程序中,我们应该根据业务要求设计索引基础。了解数据的分布将非常有帮助,并记住索引仅针对特定查询。