memgraph是用于静态或实时图分析的开源内存中图表计算平台。它拥有一组在C ++中实现的高度优化的图形算法,还提供了在Python,C/C ++或Rust中创建自定义过程的可能性。阅读how to explore your NetworkX graphs with Memgraph以了解与NetworkX相比使用Memgraph的好处。
最受欢迎的图形算法之一是Pagerank算法,最初由Google Search使用在其搜索引擎结果中对网页进行排名。 Pagerank有许多实现,而NetworkX和Memgraph则具有他们的作用。让我们找出示例数据集上哪个更快!
数据集
NetworkX和Memgraph Pagerank可以并且将从Memgraph运行,因为在Memgraph中,可以通过Python程序扩展Cypher查询语言。在其中一个过程中,我们将利用NetworkX库。
memgraph的视觉界面Memgraph Lab具有一系列数据集,可用于各种图形实验和探索。为此比较的数据集是由78,181个节点和310,227个关系制成的Wikipedia文章数据集。 Wikipedia文章数据集可以从数据集部分导入到数据库中。

可以在 Graph架构部分中生成Wikipedia文章数据集的图形数据模型,以更好地了解数据集中的节点和关系如何相互交互。

Wikipedia文章数据集足够大,可以获得显着的结果,以比较Memgraph和NetworkX的Pagerank算法。可以在更大的数据集上进行比较,但是NetworkX可以很快地吞噬内存,并且这种用例是Memgraph所能没有进行测试的问题或需要的选择。
。自定义查询模块
memgraph与NetworkX集成在一起,这意味着它可以将NetworkX图以及使用NetworkX库的一组NetworkX算法和算法转换为memgraph图。 Memgraph内部的NetworkX算法已优化,以获得最佳性能并在Memgraph Digraph对象上运行。
自定义查询模块允许我们在网络X Digraph对象上运行NetworkX Pagerank算法,而不是在Memgraph Digraph对象上运行它以进行更公平的比较。可以通过创建新模块在查询模块部分中开发自定义查询模块。名称是根据偏好给出的,我们将其称为查询模块measure。

以下是用于比较的自定义查询模块的代码:
import mgp
import networkx as nx
@mgp.read_proc
def pagerank(ctx: mgp.ProcCtx) -> mgp.Record(node=mgp.Vertex, rank=float):
g = nx.DiGraph()
g.add_nodes_from(ctx.graph.vertices)
for v in ctx.graph.vertices:
g.add_edges_from([(edge.from_vertex, edge.to_vertex) for edge in v.in_edges])
pg = nx.pagerank(g, tol=1e-05)
return [mgp.Record(node=k, rank=v) for k, v in pg.items()]
在查询模块中,Procedure Pagerank从上下文中提取图形,并创建一个NetworkX Digraph的实例。然后,网络X Pagerank算法在该挖掘机上运行。
自定义查询模块的过程由查询执行部分运行。使用以下cypher查询来调用来自测量查询模块的pagerank()过程:
CALL measure.pagerank() YIELD node, rank;
如果您有兴趣使用Memgraph开发自定义查询模块,请前往我们的documentation并了解更多信息。
比较
为了获得最佳比较,Memgraph的get()过程是从pagerank模块中调用的,并且从measure模块中调用了自定义过程pagerank()。返回结果的数量限制为1,因为如果结果被过滤或不限于限制,则不必要的时间会被计数。
以下是Wikipedia文章数据集上Memgraph的Pagerank的结果:
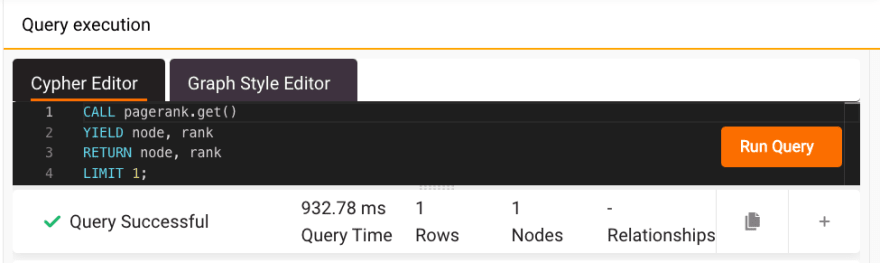
这是同一数据集上NetworkX的Pagerank的结果:

memgraph在Wikipedia文章数据集量表(78,181个节点和310,227个关系)上执行Pagerank算法时,
重要的是要注意,由于其C ++的实现和高度优化的storage memory usage,Memgraph在更大范围内胜过网络。 Pagerank只是Memgraph开箱即用的图形算法的一个示例。有关更多信息,可用查询模块的check out the list。
值得一提的另一件事是,Memgraph支持动态图算法,这可以进一步加快图形分析!例如,使用dynamic PageRank和一系列数据流,Memgraph在消耗图形对象(即在数据库中创建)后立即为您提供新更新的结果。对于实时用例,例如信用卡欺诈检测,而Memgraph则是最佳的。
结论
由于其优化的存储内存使用量和C ++中图算法的实现,Memgraph Phaph Praph Praphhers在大型数据集上的图形计算比NetworkX更好,如在78,181个节点上运行Pagerank算法所示,如在78,181个节点上的Pagerank算法所示,Memgrapher的310,227关系是Memgraph的5次越过5次越过5倍及时的备件。而不是networkx。随着数据集大小的增加,与NetworkX相比,Memgraph的速度也随之增加。
如果您想检查更多示例和比较,请前往music social network tutorial进行中心比较或社交网络分析教程以了解有关community detection的更多信息。
要了解更多信息,请前往我们的resources for NetworkX开发人员。