- 注意:该项目的最初想法得益于 sumil shah shah视频,有关弹性搜索Aquí。
可以在Github中咨询带有最终结果的存储库。
- ndice
要求
- Python(3.10.6可选)和Python的基本知识。
- jupytt neeebook
- Docker /关于Docker和Docker组成的知识。
Docker的“打开搜索安装”
执行简单清洁数据后,它们将存储在“开放搜索”中,因此我们将开始使用Docker初始化开放搜索服务。
为此,在kude0文件夹中,我们将创建带有以下内容的kude1文件(阅读代码的注释)(Más información):
version: "3"
services:
# Este es el servicio principal de Open Search, que nos
# permitirá almacenar datos y realizar búsquedas.
se-opensearch:
# Imagen de docker oficial de open search
image: opensearchproject/opensearch:1.3.6
container_name: se-opensearch
# Nombre del host dentro de la red de docker
hostname: se-opensearch
restart: on-failure
ports:
- "9200:9200"
# Performance analyzer, no lo usaremos, pero
# en la documentacion oficial lo utilizan
- "9600:9600"
expose:
- "9200"
- "9600"
environment:
- discovery.type=single-node
# Deshabilitamos el plugin de seguridad para poder
# conectarnos sin certificados SSL (no recomendado
# para producción)
- DISABLE_SECURITY_PLUGIN=true
volumes:
# Creamos un volúmen para que los datos no se pierdan
# al momento de detener el contenedor de docker.
- opensearch-data-1:/usr/share/opensearch/data
networks:
# Red interna de docker.
- se-opensearch-net
# Este servicio es opcional, solamente añade un dashboard
# web para poder visualizar nuestros datos.
se-opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:1.3.6
container_name: se-opensearch-dashboards
hostname: se-opensearch-dashboards
depends_on:
- se-opensearch
restart: always
ports:
- "5601:5601"
expose:
- "5601"
environment:
- OPENSEARCH_HOSTS="http://se-opensearch:9200"
- DISABLE_SECURITY_DASHBOARDS_PLUGIN=true
networks:
- se-opensearch-net
# Creamos el volúmen
volumes:
opensearch-data-1:
# Creamos la red
networks:
se-opensearch-net:
一旦创建并保存了kude1文件,在kude3文件夹中,我们执行kude4命令以启动服务:
docker-compose up
数据清洁
要从本节开始,在Kude5文件夹中,我们将创建一个Jupyter笔记本电脑文件,但是在可选之前,我们将创建Python (Más información)的虚拟环境:
在cleansing/文件夹中:
virtualenv -p python3 environment
从Linux激活虚拟环境:
source environment/bin/activate
从Windows激活虚拟环境:
./environment/Scripts/activate
不管我们是否创建虚拟环境,我们现在都将执行jupyter笔记本电脑安装,为此,我们在控制台中执行:
pip install notebook
安装它后,我们执行了以下操作:
jupyter notebook
在Jupyter Notebook网站中,我们创建了一个新的“笔记本”:

在新笔记本中,我们将安装必要的软件包:
!pip install pandas
# Paquete para conectarnos a open search
!pip install opensearch-py
# "Paquete" para convertir los textos a vectores
!pip install sentence-transformers
import pandas as pd
import json
import re # Expresiones regulares
# Estos dos paquetes los usaremos para generar un numero
# aleatorio mas adelante
import time
import math
# Coneccion a Open Search
from opensearchpy import OpenSearch
# Helpers para insertar todos los datos de manera rápida
from opensearchpy import helpers
from sentence_transformers import SentenceTransformer
# Descargamos el modelo para transformar los textos
# (Esto puede demorar un poco)
transformer_model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
安装软件包后,我们“读取”使用 web刮擦生成的kude7文件,然后将其转换为pandas DataFrame:
# Leer el archivo
file = open('../scraping/data.json')
data = json.load(file)
# Convertir a un DataFrame de pandas
df = pd.DataFrame(data)
# Mostar el DataFrame
df
如果一切都正确,我们应该看到一张桌子如下:

清洁数据将采取的第一步是消除重复条目,为此,我们执行以下代码:
print('Length before dropping duplicates: {}'.format(df.shape))
# Eliminamos entradas duplicadas a partir de la url ya que
# esta deber ser única.
df.drop_duplicates(subset=['url'], keep='first', inplace=True, ignore_index=False)
print('Length after dropping duplicates: {}'.format(df.shape))
消除了重复数据后,我们可以删除不sessed的字符,在这种情况下,这将是:
- 视频说明中的链接
- 熔岩跳。
- 非α©河(包括表情符号)
- 冗余空格。
我们将通过执行以下代码来通过正则表达式来完成以上表达式:
# Realizamos una copia del dataframe para no afectar el
# original en caso de que algo salga mal
df_bk = df.copy()
# Iteramos cada fila del DataFrame
for index in df_bk.index:
title = df_bk['title'][index]
description = df_bk['description'][index]
tags = df_bk['tags'][index]
new_tags = []
# Remove urls
title = re.sub(r'(http|https|www)\S+', '', title)
description = re.sub(r'(http|https|www)\S+', '', description)
# Remove \n texts
title = title.replace('\n', ' ')
description = description.replace('\n', ' ')
# Remove non-alphanumeric chars
# title = re.sub(r'[^a-zA-Z0-9\']', ' ', title)
description = re.sub(r'[^a-zA-Z0-9]', ' ', description)
# Iteramos cada tag ya que los tags son un array de strings
for tag in tags:
new_tag = re.sub(r'[^a-zA-Z0-9]', '', tag)
new_tag = re.sub(' +', ' ', new_tag)
new_tags.append(new_tag.)
# Remove redundant spaces
title = re.sub(' +', ' ', title)
description = re.sub(' +', ' ', description)
# Set new value
df_bk['title'][index] = title
df_bk['description'][index] = description
df_bk['tags'][index] = tags
# Mostramos el DataFrame resultante al final
df_bk
如果正确执行了上一步,我们应该看到一个与显示几个步骤相似的表。
在开放搜索中存储
拥有数据,其余步骤是将它们存储在开放搜索中,我们首先生成一个连接:
# Connection variables
host = 'localhost'
port = '9200'
# Usuario y contraseñas por defecto
auth = ('admin', 'admin')
# Connect
client = OpenSearch(
timeout = 300,
hosts = [{'host': host, 'port': port}],
http_compress = True,
http_auth = auth,
use_ssl = False,
verify_cers = False,
)
client.ping()
如果我们执行了先前的单元格,则应显示一个kouude9,否则,确认正在执行Docker-compos或审查官方文档:

在将数据存储在开放搜索中之前,我们将创建一个新列来存储代表每个Abiaoqian Vines15的向量:
# Creamos una columna vacía
df_bk = df_bk.assign(vector="")
现在,我们将在新列中插入相应的vitorial vitorial (Más información):
# Iteramos cada fila / vídeo
for index in df_bk.index:
title = df_bk['title'][index]
description = df_bk['description'][index]
tags = df_bk['tags'][index]
# Creamos un solo string que contenga los textos importantes del vídeo
bundle = title + ' ' + description
for tag in tags:
bundle += ' ' + tag
# Transformarmos el string único a un vector con el
# modelo descargado previamente
vector = transformer_model.encode(bundle)
# Asignamos el vector a la columna vacía
df_bk['vector'][index] = vector
# Mostramos el DataFrame final
df_bk
如果一切都正确执行,我们应该看到以下的表:

拥有所有空白数据,我们可以创建开放搜索,,可以将其视为关系数据库中表的等效物,尽管它们并不完全相同:
index_name = 'videos'
index_body = {
'settings': {
# Es necesario configurar esto para utilizar el plugin KNN
# EN la mayoría de campos se dejaron los valores por defecto
'index': {
'number_of_shards': 20,
'number_of_replicas': 1,
'knn': {
'algo_param': {
# Default 512: https://opensearch.org/docs/latest/search-plugins/knn/knn-index#method-definitions
# Higher values lead to more accurate but slower searches.
'ef_search': 256,
# Using during graph creation
'ef_construction': 256,
# Bidirectional links for each element
'm': 4
}
}
},
'knn': 'true'
},
# A continuación se definen las "columnas" del índice, las
# cuales son los campos de nuestros videos
'mappings': {
'properties': {
'url': {
'type': 'text'
},
'thumbnail': {
'type': 'text'
},
'title': {
'type': 'text'
},
'description': {
'type': 'text'
},
'tags': {
# Text type can be used as array
'type': 'text'
},
'vector': {
'type': 'knn_vector',
'dimension': 384
}
}
}
}
# Si el índice ya existe, lo eliminamos (Esto es solo en caso
# de ejecutar el notebook nuevamente)
if(client.indices.exists(index=index_name)):
client.indices.delete(index=index_name)
# Creamos el índice
reply = client.indices.create(index_name, index_body)
print(reply)
上面的答案应如下:
{'acknowledged': True, 'shards_acknowledged': True, 'index': 'videos'}
最后,我们可以插入我们的数据;为此,我们可以迭代每个行并单独插入它们,但是我们将使用整个开放搜索的整体批量,使我们能够以拉克的方式插入大量数据:
< br>
# Crearemos un array ya que el método bulk recibe un elemento
# iterable
data = []
# Iteramos cada fila del DataFrame
for index in df_bk.index:
# Tomamos todos los datos
url = df_bk['url'][index]
thumbnail = df_bk['thumbnail'][index]
title = df_bk['title'][index]
description = df_bk['description'][index]
tags = df_bk['tags'][index]
vector = df_bk['vector'][index]
# Formamos un diccionario con los datos y lo insertamos al array
# El campo _index es necesario para indicarle a Open Search
# el índice al que debe agregar los datos
data.append({'_index': index_name,
'url': url,
'thumbnail': thumbnail,
'title': title,
'description': description,
'tags': tags,
'vector': vector})
# Insertamos los datos
reply = helpers.bulk(client, data, max_retries=5)
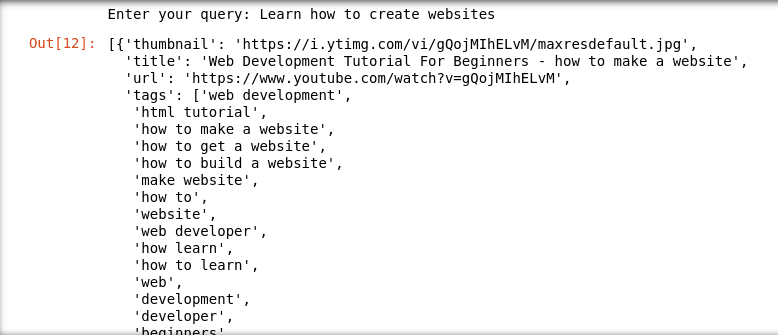
要验证数据是否正确插入,我们可以在笔记本(Ver ídea original)中模拟bysques:
# Recibir el input por teclado
query = input('Enter your query: ')
# Convertir el input a un vector (Para poder usar el plugin KNN en Open Search).
query_vector = transformer_model.encode(query)
open_search_query = {
# Tomamos 24 resultados
'size': 24,
# Campos que nos interesan de la respuesta
'_source': ['url', 'thumbnail', 'title', 'tags'],
# Filtro
"query": {
"bool": {
'must': [
# Usamos el plugin knn
{'knn': {
"vector": {
# Le pasamos nuestro vector
"vector": query_vector,
# Tomamos los 24 "vecinos más cercanos"
"k": 24
}
}}
]
}
}
}
response = client.search(
# Buscamos en nuestro índice
index = index_name,
# Limitamos a 24 resultados
size = 24,
# Cuerpo de la búsqueda
body = open_search_query,
request_timeout = 64
)
# Simplificamos el resultado ya que por defecto tiene muchos
# otros campos
videos = [x['_source'] for x in response['hits']['hits']]
# Mostramos los resultados obtenidos
videos
下面的一些bar示例:

最后
这是第三部分的结论,我们对数据进行了简单清洁,并将它们存储在公开搜索中,我邀请您继续下一个我们将开发Python API的下一个,以允许我们的用途来制作Bysaes。
参考
咨询参考文献以转到不同页面内部或末尾出现的每个链接。