默认情况下,yugabytedb表(索引)在第一列上由哈希水平划分,默认情况下,默认情况下,取决于节点的数量。这很好地分配数据。但是,对于在范围上读取的列,哈希功能不是正确的选择。您为主键或辅助索引列定义range sharding by mentioning ASC or DESC。但是,默认情况下,仅使用一个平板电脑创建表或索引。当然,您可以在创建时间或更高版本的特定值上将其拆分。但是,您不想手动管理此问题,对吗? Yugabytedb可以在加载数据时将这单一平板电脑分开。
配置
在这篇文章中,我正在展示基本行为。我将在其他帖子中解释机制。我正在使用3个节点中的所有默认值2.13.1群集(预览版本 - 稳定版本可能会在默认情况下将其禁用以使其轻松滚动升级):
--enable_automatic_tablet_splitting=true
--tablet_force_split_threshold_bytes=107374182400
--tablet_split_high_phase_shard_count_per_node=24
--tablet_split_high_phase_size_threshold_bytes=10737418240
--tablet_split_low_phase_shard_count_per_node=8
--tablet_split_low_phase_size_threshold_bytes=536870912
--tablet_split_size_threshold_bytes=0
从参数您可以看到两个阶段。当有少数平板电脑时,“低相”会迅速分裂。 “高阶段”具有更大的阈值,以避免使用太多平板电脑。在这里,我将显示“低相位”,从一个空表开始,然后按100MB批次加载。这里的低相位阈值是
tablet_split_low_phase_size_threshold_bytes=536870912 = 512MB
在rf = 3实验室,带有yugabytedb 2.13.1我运行以下内容:
create table demo_auto_split ( id int generated always as identity, junk text, primary key(id asc) );
copy demo_auto_split(junk) from program 'base64 /dev/urandom | head -c 104857600' ;
\watch 1
这将创建一个范围内的表,仅当您不定义在哪里拆分时,它才会使用1平板电脑创建。在自动分解功能之前,您必须以后手动将其分开。
现在,我只是通过100MB复制语句加载数据,然后检查发生了什么。这是输出:
psql (13.5, server 11.2-YB-2.13.1.0-b0)
Type "help" for help.
yugabyte=# create table demo_auto_split ( id int generated always as identity, junk text, primary key(id asc) );
CREATE TABLE
yugabyte=# copy demo_auto_split(junk) from program 'base64 /dev/urandom | head -c 104857600' ;
COPY 1361788
加载100m(在1361788行中)后,我的表在一个SST文件中具有SST Files Uncompressed: 211.13M(SST Files: 137.67M压缩):

这是表创建时间的一个平板电脑,涵盖了整个值range: [<start>, <end>)
分裂深度

YB-Master GUI中可见的最后一项任务是关于该平板电脑的创建和领导者的选举:
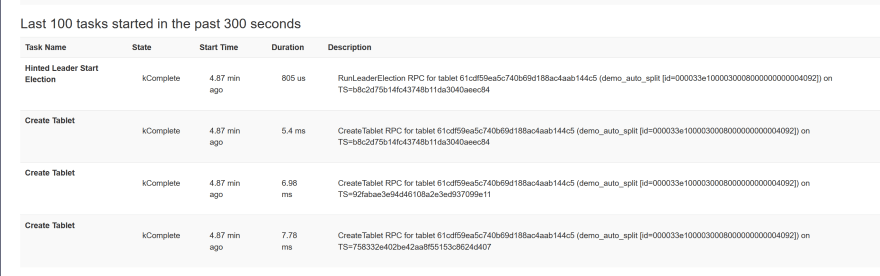
拆分深度1
我现在再次运行一个复制命令,以加载100m(1361788行)。我有2723576行,id从1到2723576,小于500MB:

再次加载100m(1361788行)。我有4085364行,id从1到4085364,仍然小于500MB的SST文件(压缩)

再次加载100m(1361788行)。我有4085364行,id从1到4085364,仍然小于500MB的SST文件(压缩)
在负载期间,我们达到500MB的阈值(SST Files: 512.80M)。几秒钟没有信息:

然后显示SST Files: 542.25M:

SplitDepth=0的平板电脑存储在range: [<start>, <end>)中的所有行仍然是running11,但我看到了另外两个平板电脑,在SplitDepth=1 split value 1895723,一个已经Running,另一个仍然是Creating

几分钟后,这两个新平板电脑是Running,前一个是Deleted
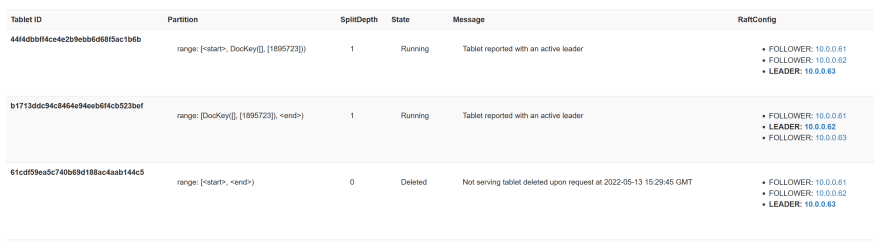
Deleted像木筏日志一样保存,以防万一跟随者离开网络一段时间,以便在返回时可以快速赶上。
自动分裂由主驱动,因此您可以在那里找到任务(Get Tablet Split Key,Split Tablet,然后是Stepdown Leader和Delete Tablet):

日志中有更多信息,您可以在该应用程序运行,阅读和写作以及通过RAFT协议同步时看到复杂的操作在后台运行。
我现在有两个带有SST Files: 188.36M和SST Files: 353.99M的平板电脑


自动分类阶段
这里触发拆分的阈值是tablet_split_low_phase_size_threshold_bytes=536870912,这意味着低相位的平板电脑大于512MB。这种低期非常激进,因为平板电脑可能会更大。这个想法是分开以在节点VCPU和RAM上分配负载,甚至对于中型表。但是,一旦使用了所有资源,平板电脑太多并不是最佳的,因此对于平均每节点8平板电脑的表格,可与tablet_split_low_phase_shard_count_per_node=8配置的表平均值。
然后,平板电脑将生长到更大的尺寸,直到到达tablet_split_high_phase_size_threshold_bytes=10737418240,这意味着当它们大于10GB时,高相会拆分它们。这里的目标是要降低积极性,因为分布已经正确,但是在添加新节点时使平板电脑易于移动。该高相位的平板电脑数量限制,由tablet_split_high_phase_shard_count_per_node=24配置,这再次是每个节点的平均值。这也意味着,如果您添加新节点,平板电脑将重新平衡,并且平均值降低。
然后,对于此表或索引,每个节点上的24片平板电脑将在10GB上生长,但还有另一个限制可以避免难以操纵的平板电脑尺寸。默认情况下,使用tablet_force_split_threshold_bytes=107374182400设置为100GB。然后它们继续增长,但您可能会缩放群集,因为这意味着每个节点240GB的表
此功能在:
中描述
https://github.com/yugabyte/yugabyte-db/issues/8039