从CS毕业后,我开始阅读技术书籍,以扩大我对许多主题的了解,例如系统设计,低级CS,Cloud Native等。如今,我正在阅读Matthew Titmus的Cloud Native Go,使用GO的好处对云原住民世界进行了平稳的介绍。这本书以Go Basics和Cloud Native模式开始,这就是我认为“我应该写这些模式!”。
。在这一系列博客文章中,我将写有关我学到的云本地模式的文章 - 也使用Manim的插图。
问题
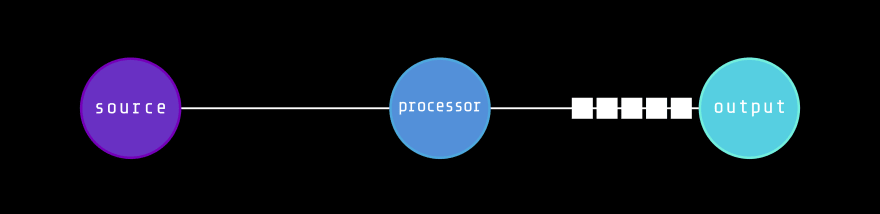
假设我们有一个恒定的数据源(例如GO channel),我们需要处理数据并将处理后的数据放入尽可能低的延迟的目标通道中。
在一般情况下,我们有一个处理器函数,该功能位于源和目的地中间,该功能处理数据包(此处的数据包是一个简单的抽象)。

但是,每个处理功能都有延迟。这可能是由于网络或CPU使用情况,阻止SYSCALL等。我们现在有一个瓶颈!

解决方案
对此问题有一个相当简单的解决方案:使用数据管道中的多个处理器。这样,我们可以同时处理数据流,从而减少整体延迟并减少管道拥塞。

那是粉丝登机和粉丝出现的地方
我们可以通过使用共享内存来实现此解决方案,例如消息队列。
使用这种方法,我们将将传入的数据包分为不同的输入队列。然后,每个队列自己的处理器将一一将数据包处理,处理数据,然后将处理的数据放入其相关的输出队列中。最后,目的地(另一个处理器,队列或其他系统)将从每个输出队列中获取处理后的数据包,并将其汇总到单个数据源中。
第一种方法将数据源(输入)拆分为多个数据源(输入队列)称为Fan-out模式。第二个,将多个数据源(输出队列)汇总到单个数据源(目标)被称为Fan-in模式。
为简单起见,我们为管道中的每个处理器指定了一个输入队列和一个输出队列。我们可以根据整体系统要求使用每个处理器的多个输入/输出队列,或几个处理器之间的共享队列。

去实施
让我们弄脏一些并发吧!首先,让我们定义我们的数据源:
func stringGenerator(prefix string, count uint) <-chan string {
ch := make(chan string)
go func() {
defer close(ch)
for i := uint(0); i < count; i++ {
ch <- fmt.Sprintf("%s-%d", prefix, i)
}
}()
return ch
}
函数stringGenerator创建了一个仅接收字符串频道,创建了一个goroutine,将前缀的字符串放入频道中,并返回频道。我们稍后在风扇输出代码中从该频道中阅读。
我们的处理器功能也很简单:
func stringProcessor(id int, source <-chan string) <-chan string {
ch := make(chan string)
go func() {
defer close(ch)
for data := range source {
ch <- fmt.Sprintf("P-%d processed message: %s", id, data)
millisecs := rand.Intn(901) + 100
time.Sleep(time.Duration(millisecs * int(time.Millisecond)))
}
}()
return ch
}
在处理器功能中,我们将等待随机的时间来模拟处理器延迟。
粉丝淘汰实施
在Fan-Out实施中,我们将使用一个仅接收渠道,并返回一小部分接收频道:
// Splitter implements the Fan-out pattern
func Splitter(source <-chan string, numDests uint) []<-chan string {
destinations := make([]<-chan string, 0, numDests)
for i := uint(0); i < numDests; i++ {
dest := make(chan string)
go func() {
defer close(dest)
for data := range source {
dest <- data
}
}()
destinations = append(destinations, dest)
}
return destinations
}
在Splitter函数内创建的goroutines将处理数据路由逻辑。请注意,在Goroutines内部,我们使用了一个range语句从source频道接收:
for data := range source {
dest <- data
}
这意味着每个Goroutine都会尝试从循环中的频道中读取,并且第一个进行读取的内容将接收下一个项目。换句话说,每个goroutine都会在下一个数据实例中战斗。
我们可以使用集中式解决方案进行风扇淘汰,而不是竞争戈洛蒂斯(Goroutines)。在这种情况下,我们将定义一个master process,以在所有输出渠道中分配每个传入数据实例(string)。
粉丝实施
在粉丝中,我们基本上将进行粉丝的反面,但有一些区别:
// Aggregator implements the Fan-in pattern
func Aggregator(sources []<-chan string) <-chan string {
destination := make(chan string)
var wg sync.WaitGroup
wg.Add(len(sources))
for _, source := range sources {
go func(src <-chan string) {
defer wg.Done()
for data := range src {
destination <- data
}
}(source)
}
go func() {
wg.Wait()
close(destination)
}()
return destination
}
Aggregator函数采用了一小部分仅接收输入源,并返回一个仅接收输出通道。在内部,我们为每个输入源创建了一个goroutine,该源连续读取源,并通过收到的数据填充输出通道(destination)。
请注意,我们已经使用sync.WaitGroup等待聚合器Goroutines完成。在关闭输入源(channel)之后,相应的Goroutine内部的for循环将结束,它将完成其作业。
关闭了所有输入源后,我们完成了聚合,现在我们可以关闭目标通道。 这是一个关键的步骤,如果我们不关闭我们创建的频道,那么GO运行时将会出现致命错误:
fatal error: all goroutines are asleep - deadlock!
主要的()
将所有功能放在一起,我们准备运行代码:
const (
processorCount = 10
)
func main() {
splitSources := Splitter(stringGenerator("test", 100), processorCount)
procSources := make([]<-chan string, 0, processorCount)
for i, src := range splitSources {
procSources = append(procSources, stringProcessor(i, src))
}
for out := range Aggregator(procSources) {
fmt.Println(out)
}
}
tl; dr
- 带有单个处理器的数据管道最终将撞到瓶颈
- 将输入源分为几个队列,并同时处理很有帮助
- 这种分裂过程 - 聚集模式称为风扇in/fan-out
感谢您的阅读!有关GO and Cloud Native的更多博客文章,请查看我的博客sazak.io。