今天,我决定在Amazon Aurora上再进行一次荒谬的测试,这次是与不同的MySQL引擎一起玩的。
对mysql和aurora进行了一些荒谬的实验
Amazon RDS和Amazon Aurora完全支持MySQL DB实例的InnoDB存储引擎。有一些功能,例如Snapshot Restore,仅支持InnoDB存储引擎。但是InnoDB并不是MySQL或Aurora mysql
的RDS上唯一可用的您可以看到所有引擎启用了运行一个简单的发动机:
MySQL> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
innodb是默认引擎,您应该使用的每个表格。除非您不关心表中存储的数据。
但是InnoDB是不是RDS上最快,最轻的存储引擎。不,我不是在谈论Myisam,我说的是垃圾垃圾箱,BLACKHOLE存储引擎:
黑洞存储引擎充当一个黑洞,它接受数据但将其扔掉并且不存储。检索总是返回空的结果。
什么?
优化IOP和数据问题较少的最佳方法不是首先将数据保留。好的,我们将少存储数据,但是我们真的在CPU使用方面有好处吗?它真正花费了多少,存储(无用)数据?
有什么真正的差异?
我们将运行一个小实验,以4 ACU(约8GB)的固定尺寸运行Aurora无服务器实例。
让我们创建一个简单的表格和一个程序,以几个(百万和无用的)记录填充它。这里没有任何幻想,每个电话只有一些随机数和500万记录。
CREATE TABLE data
(id bigint(20) NOT NULL AUTO_INCREMENT,
datetime TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP,
value float DEFAULT NULL,
PRIMARY KEY (id)) ENGINE=InnoDB;
DELIMITER $$
CREATE PROCEDURE generate_data()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 5000000 DO
INSERT INTO data (datetime,value) VALUES (
FROM_UNIXTIME(UNIX_TIMESTAMP('2022-01-01 01:00:00')+FLOOR(RAND()*31536000)),
ROUND(RAND()*100,2));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
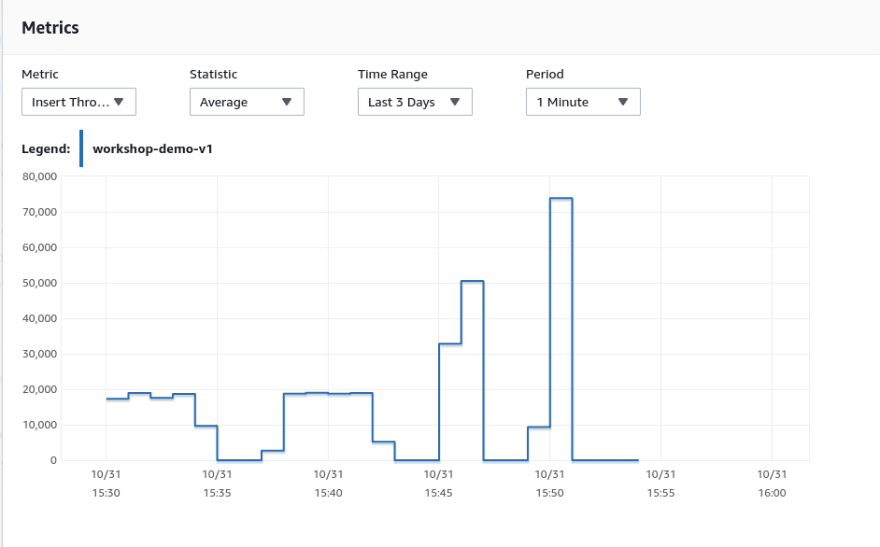
现在,我们可以调用我们的简单过程(两次,看到结果不是随机性和可重现的),并将数据库的指标与InnoDB和黑洞发动机进行比较。我们在执行之间有点睡觉(200秒),以具有更清晰的指标:
CALL generate_data();
SELECT sleep(200);
CALL generate_data();
SELECT sleep(200);
ALTER TABLE data ENGINE=BLACKHOLE;
CALL generate_data();
SELECT sleep(200);
CALL generate_data();
,获胜者是...
正如预期的那样,数据库的CPU负载差异很大,存储(无用)数据并不便宜。

插入吞吐量增加,减少了运行该过程所需的时间。
你在开玩笑吗?
否,在某些角案件中运行简单:
ALTER TABLE myUselessTable ENGINE=BLACKHOLE;
并不是完全疯狂。在场景中:
-
紧急按钮。好的,您的数据库确实已经用完了IOPS,您没有逻辑上的分类来将流量分开以分开实例。垂直缩放将无济于事。如果您有一些数据可能会丢失,那么在黑洞上运行桌子可能是淘汰的监狱卡。
-
加快应用程序更改。好的,您的产品中不再那么酷了,您决定停止收集数据并删除数据,但几天或几周内将没有修复 /新版本。您可能很幸运,并且能够在此期间放弃记录。
3 测试您的新酷功能对写入IOPS对复杂工作负载的影响。像在这些虚拟测试中一样,尝试有或没有黑洞。您可能会得到一些有用和可怕的数字。
可持续性?
每个人都谈论可持续性,让我们添加最终音符。上个月,我参加了Sheen Brisals在柏林Serverless Architecture Conference的无服务器中的可持续性的演讲。 Sheen的关键信息之一是摆脱无用的数据:如果您不需要数据,请不要存储它。

Gert Leenders最近分享了一个similar view:
没有数据访问的情况下,Petabyte数据湖没有价值。
我完全同意,best way to have fewer problems with data is not to have the data。无用数据的成本不仅是存储。
不需要存储的商店数据。您不仅要进行不需要的存储空间。您正在燃烧CPU周期。你正在加热地球。您正在排出信用卡。您正在放慢应用程序。
您甚至可能不需要更改产品来削减一些好处。继续使用那个简单的Alter表。
或删除整个数据库并停止该RDS / Aurora实例。好,也许我只是在开玩笑。