什么是Apache Spark:
Apache Spark是一个数据处理框架,可以快速在非常大的数据集上执行处理任务,还可以在节点的单节点或群集上分发数据处理任务。
为什么Apache Spark:
-
快速处理 - SPARK包含弹性分布式数据集(RDD),该数据集(RDD)节省了读写和写作操作的时间,使其运行近十到一百倍。
-
灵活性 - Apache Spark支持多种语言,并允许开发人员在Java,Scala,R或Python中编写应用程序。
-
内存计算 - Spark将数据存储在服务器的RAM中,该数据允许快速访问并加速分析速度。
-
实时处理 - Spark能够处理实时流数据。与MapReduce仅处理仅存储数据的MapReduce,Spark能够处理实时数据,因此能够产生即时结果。
-
更好的分析与包括MAP和减少功能的MapReduce相反,Spark所包含的远不止于此。 Apache Spark由一套丰富的SQL查询,机器学习算法,复杂的分析等组成。通过所有这些功能,可以在Spark的帮助下以更好的方式进行分析。
火花的术语:
-
SPARK应用程序:SPARK应用程序是一个独立的计算,该计算运行用户提供的代码以计算结果。火花应用程序即使不运行作业也可以代表其运行。
-
任务:任务是发送给执行人的工作单位。每个阶段都有一些任务,每个分区的一个任务。在RDD的不同分区。
也完成了相同的任务。
-
job:作业是并行计算,由多个任务组成,这些任务响应于Apache Spark中的动作。
-
阶段:每个作业都分为较小的任务集,称为阶段,彼此相互依赖。阶段被归类为计算边界。所有计算都不能在一个阶段完成。它在许多阶段都取得了成就。
火花运行时架构的组件:
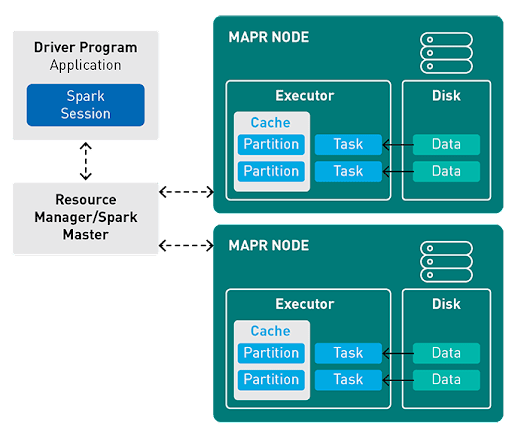
-
潜水员:程序的主()方法在驱动程序中运行。驱动程序是运行创建RDD并执行转换和操作的用户代码的过程,还可以创建SparkContext。
-
群集管理器:SPARK依靠集群管理器来启动执行者。这是Spark中的可插入组件。在Spark调度程序计划以FIFO方式安排的SPARK应用程序中,在集群管理器中,作业和动作。 Spark应用程序使用的资源可以根据工作负载动态调整。这可以在所有粗粒群集管理器上可用,即独立模式,纱线模式和Mesos粗粒模式。
-
执行者:给定的Spark作业中的单个任务在Spark执行者中运行。执行者在Spark应用程序的开头启动一次,然后在应用程序的整个生命周期内运行。即使Spark Executor失败,Spark应用程序也可以轻松继续。执行者有两个主要角色:
- 运行构成应用程序的任务并将结果返回给驱动程序。
- 为用户缓存的RDD提供内存存储。
Apache Spark提供了3种不同的API,用于使用大数据
* RDD
* DataFrame
* DataSet

- Spark RDD:RDD代表弹性分布式数据集。
它是Apache Spark的基本数据结构。 Apache Spark中的RDD是一个不变的对象集合,该对象在集群的不同节点上计算。
弹性,即借助RDD Lineage图(DAG)的耐故障,因此由于节点失败而能够重新计算缺失或损坏的分区。
分布式,因为数据位于多个节点上。
数据集表示您使用的数据的记录。用户可以通过JDBC进行外部加载数据集,该数据集可以是JSON文件,CSV文件,文本文件或数据库,而无需没有特定的数据结构。
- Spark DataFrame:
Spark DataFrames是数据点的分布式集合,但是在这里,数据被组织到命名列中。他们允许开发人员在运行时调试代码,而RDD不允许进行。
DataFrames可以将数据读取为各种格式,例如CSV,JSON,AVRO,HDFS和HIVE表。已经对大多数预处理任务处理大型数据集已经进行了优化,因此我们不需要自己编写复杂的功能。
- 火花数据集:
数据集也是SPARKSQL结构,代表数据帧API的扩展。数据集API结合了数据范围的性能优化和RDD的便利性。此外,API与强烈键入的语言更好。
在2016年晚些时候,在SPARK 2.0数据集和DataFrame 合并中将学习Spark的复杂性降低。
在Java中使用Apache Spark
- 用Maven安装Apache Spark
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.1</version>
</dependency>
- 用gradle安装apache spark
dependencies {
compile 'org.apache.spark:spark-sql_2.13'
}
sparksession vs sparkcontext â€既然Spark或pyspark的早期版本,SparkContext是使用RDD进行Spark编程并连接到Spark Cluster的入口点,因为Spark 2.0 Sparksession已被引入,并成为使用DataFrame和DataSet开始编程的切入点。由于我们正在使用Spark 2.0,因此我们将仅使用SparkSession访问API。
- 创建Sparksession
从上面的代码
sparksession.builder()返回sparksession.builder类。这是一个供需的建筑商。 Master(),AppName()和GetorCreate()是SparkSession.builder。
master()â如果您在群集上运行它,则需要将主名用作to Master()的参数。通常,它会根据您的群集设置为纱线,也是kubernetes。
在独立模式下运行时使用本地[X]。其中x表示从主机机器中使用的CPU核心。
appName()将SPARK Web UI中显示的Spark应用程序设置一个名称。如果未设置应用程序名称,它将设置一个随机名称。
getorCreate() - 如果已经存在,则返回一个火花对象。如果不存在,可以创建一个新的。
- 将数据安装到Apache Spark
有两种将数据安装到Apache Spark
的方法 内存中的安装数据
读取来自文件(JSON,CSV,文本,二进制)的数据
spark在读取文件时支持三个模式
允许的:在符合损坏的记录时将其他字段设置为null,并将错误的字符串放入rustal_records列
dropmalformed :忽略整个损坏的记录。
Failfast :符合损坏的记录时会引发异常。
show()用于以表行和列格式显示数据框的内容。默认情况下,它仅显示20行,列值以20个字符截断。
它将布尔人作为参数,show(false)显示列的完整内容,其中显示(true)不
- 这是我们将与之合作的JSON
假设我们想找出一个名字爱丽丝且年龄超过 24
的人我们可以使用Apache Spark
提供的数据集上的过滤器APIApache Spark智能处理损坏的记录,并根据创建Spark Session期间的模式集采取行动
处理损坏记录的两种方法:
- 将损坏的记录捕获到文件夹中
- 从数据集中过滤损坏的记录
您可以在github上找到回购。任何建议,请在评论中发布它们
将在Apache Spark中分享更多关于内存调整,以在即将到来的博客中处理更大的数据。所以请继续关注