介绍
原始文章here
使用100k的100万数据库记录几乎不是当前的Mongo Atlas定价计划的问题。您只需使用索引和分页,就可以充分利用它,没有任何喧嚣。
。但是,想象一下您的项目最近获得了新的ETL管道的大量客户数据集。现在,您需要进行一次性上传脚本,然后处理数据集的所有(或部分)的KPI计算。
拥有大于100万记录的数据集怎么样? 700万?甚至超过50ð!并非所有的标准方法都在此类卷中有效地工作。
因此,让我们看一下如何通过逐渐增加数据集大小并解决性能问题来处理这一卷!
免责声明 - 所有代码都位于这里 Github
设置
使该实验变得简单,我选择使用 m30 *专用 * cluster on Mongo Atlas。有一个无服务的蒙哥计划,但让我们省略此实验。

另外,还有一个已经可以加载数据集示例的built-in tool in Atlas,但是我建议您跟随使用“自定义脚本”的 *粗糙 *方法。您可能没有Atlas的自托管MongoDB服务器,或者Atlas CLI无法支持您的数据集扩展类型,此外,您将自己控制数据流。
另外还有一件事是互联网速度。实验在我的本地MacBook Pro上完成,具有25英镑的WiFi连接。当前实验的结果可能与在Rady Ready EC2实例上运行的结果有所不同。
。您在哪里可以找到一些示例数据?
要使用数据生成并制作一个自定义数据集,我可以建议使用https://generatedata.com/。我用它来生成数据记录。在撰写本文的那一刻,基本的年度计划的费用为25美元,您不会后悔。
此工具在浏览器中起作用,因此您需要在一代中准备好重量CPU负载。
不要忘记 *从生成的内容中剥离空格 *tick tick以使您的文件〜20%
我花了〜3H生成254MB大小的1ð数据集。这是一个JSON文件,我们将稍后使用将其加载到Mongo中。
您会在插入段落中找到准备使用数据集的链接。

我建议使用此工具不超过2M数据,因为花了一段时间,您的笔记本电脑CPU。
想要更少的努力数据吗?转到Kaggle
我的一位同事向我推荐了一个很棒的DS平台,该平台已经准备好了用于测试数据的数据集。挖掘出来后,我找到了两个适合最适合的数据集。
您可以查看其所有内容,但是通常,有一个5GB JSON文件 - yelp_academic_dataset_review.json,它包含6,9ðJSON Records。使用Dadroid查看大量JSON文件。
](https://res.cloudinary.com/practicaldev/image/fetch/s--WcxWS-ud--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/2912/1%2Af0Rdc1kIVwWb-nml6DxkMA.png)
这是45GB的蒸汽评论。下载它时,我不知道内部有多少个记录,因为所有文件都在分页的文件夹中。稍后,我们将找出如何编写脚本,以总结所有记录的计数。它们的确切数量将被揭示,但是相信我,这可以称为大(小)数据。
如何插入数据?
我建议将您的数据集放在工作文件夹外面。它将阻止您的代码编辑器为所有文件树索引并放慢文本搜索。
插入100万记录
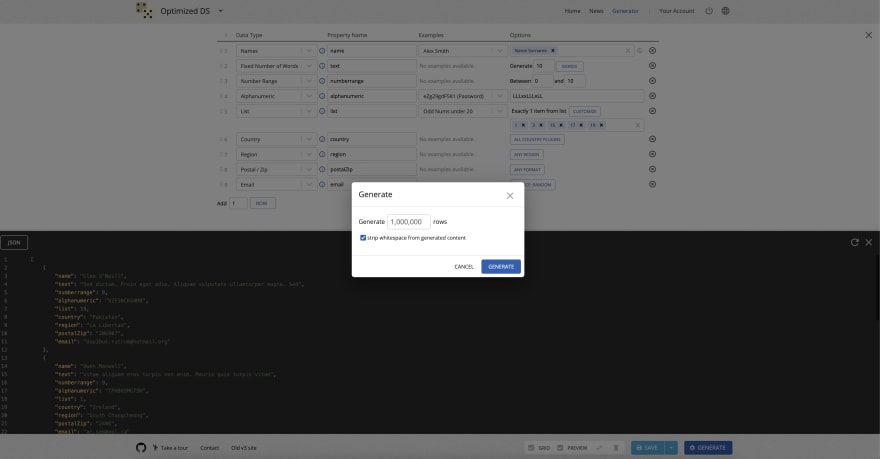
让我们从仅使用一个简单的更新程序操作插入1m JSON开始。生成数据的模板:
数据样本:
我决定尝试将所有文档插入一个没有任何块的文档:
在此脚本中,我们只是调用anonymous函数,该函数将立即执行。我将使用本机MongoDB驱动程序,因为所有其他Lib都建在此基础上。在第3行上,我将导入的诺言fs在JSON解析输入中使用。
尝试免费计划的能力很有趣,因此此脚本是在免费的地图集集群上运行的。
> node insert/1m/index.js
Reading json: 3.279s
Connected successfully to server
Started insertion process successfully to server
Inserting records: 2:18.415 (m:ss.mmm)
Mongo甚至没有感觉到!读取文件花了大约3秒钟,Mongo读取1M记录大约2.5分钟。另外,为此创建了不超过3个连接。
M30群集呢?让我们测试它将如何执行运行相同的脚本。
node insert/1m/index.js
Reading json: 2.874s
Connected successfully to server
Started insertion process successfully to server
Inserting records: 2:20.470 (m:ss.mmm)
这里的性能没有变化。当前的方法是 *Fine *方法,您可以使用它一次插入。但是简单的方法不是我们的。进入下一节。
插入700万
现在让我们与7 million JSON合作。记录示例:
一个评论这里的巨大比以前生成的数据集中的一个记录要少,但是,此卷足以给Node和Mongo带来一些压力。
以前的方法是否可以使用此类数据量?让我们测试。我更改了通往新数据集的路径并启动了我的脚本。
node insert/1m/index.js
RangeError [ERR_FS_FILE_TOO_LARGE]: File size (5341868833) is greater than 2 GB
at new NodeError (node:internal/errors:372:5)
at readFileHandle (node:internal/fs/promises:377:11)
at async /Users/mongo-performance/insert/1m/index.js:16:36 {
code: 'ERR_FS_FILE_TOO_LARGE'
2GB是可以存储在node.js buffer实体中的文件的限制大小。这就是为什么我们应该在这里使用Streams!
文档的快速参考:
流是一个抽象接口,用于在Node.js中使用流数据。 Node.js提供了许多流对象。例如,request to an HTTP server和process.stdout都是流实例。流可以可读,可写或两者兼而有之。所有流都是EventEmitter的实例。
现在我们需要对脚本进行一些粗略的更改。
第23行 - 我们创建了一个readable流,并使用stream-json lib到pipe IT。这样做是因为从node.js使用A raw 缓冲液会使阅读过程更加复杂。我们需要以某种方式将缓冲区和解析在我们自己的字符串中脱离json。
第25行通过事件发射极消耗。该函数订阅了一个 *数据 *事件,每个数据变量完全包含我们7M数据集文件中的一个JSON记录。
第27行 - 将所有记录推入一个累加器数组
第29行有一个remainder操作员 - 只要将新的100K记录推到数组时,它仅用于触发。
。第30行 - 当我们进入IF语句分支时,应暂停管道以防止新数组推动。再也没有新的插入设备,每次通话后等待100ms。恢复管道,直到结束事件开火以退出脚本。
在此示例中,我们以轻微的延迟顺序插入100K。测试时间!
node ./insert/insert-7mil-m30.js
Connected successfully to server
arrayToInsert size - 354.85045185293717 mb
Inserting time - 100000: 45.277s
--------------
.................
arrayToInsert size - *142*.*23186546517442* mb
Inserting time - *6900000*: *25*.911s
--------------
Operation took - *1749*.*997* seconds = ~29 minutes
Process finished with exit code 0
插入大约29分钟。现在似乎合理的时间太多了。
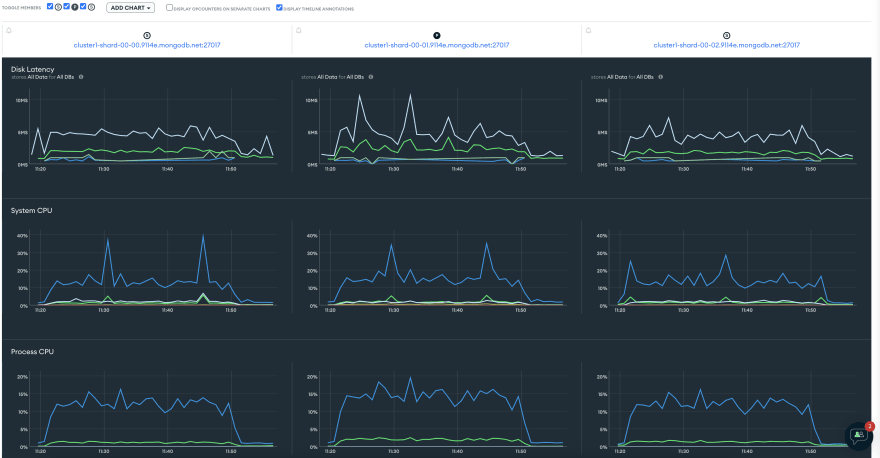

您在这里可以看到,我们使用了大约30%的系统CPU,而66个IOPS是插入过程中最高值。
根据每7m文档的29分钟,当您需要放置50m记录时,几乎需要一个无穷大(运行〜3,5h)ð。
我们肯定可以通过添加一些并行插入操作来改进它,并可能增加100k块的大小以使更多的并行操作处理:
第36行-42 – radash.parallel用于制作5个平行插入,并具有20K记录。块是由lodash.chunk方法创建的。
稍后,此方法将被重复用于更大的插入,因此请花点时间弄清楚它的工作原理。
结果:
node insert/7m/7m-m30-per200k-5X20k.js
Connected successfully to server
arrayToInsert size - 269.14077478740194 mb
id: 1664486093579 - stats: size 26.909 mb, records: 20000 - took: : 7.258s
id: 1664486093497 - stats: size 26.581 mb, records: 20000 - took: : 11.450s
................
id: 1664486950224 - stats: size 27.520 mb, records: 20000 - took: : 6.973s
id: 1664486951694 - stats: size 27.230 mb, records: 20000 - took: : 5.562s
--------------
Operation took - 867.229 seconds // ~14 minutes
我们在这里看到的性能提高到50%!我想现在好多了。那mongo呢?
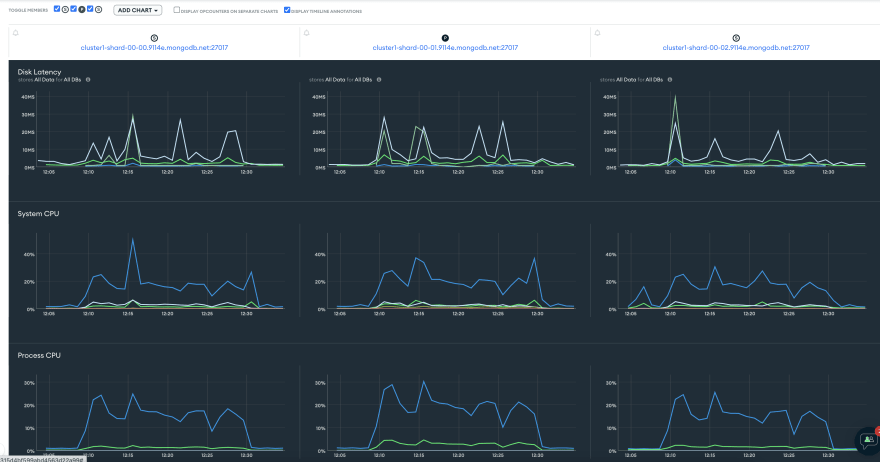
系统CPU上升到40%,比测序100K插入高10%。
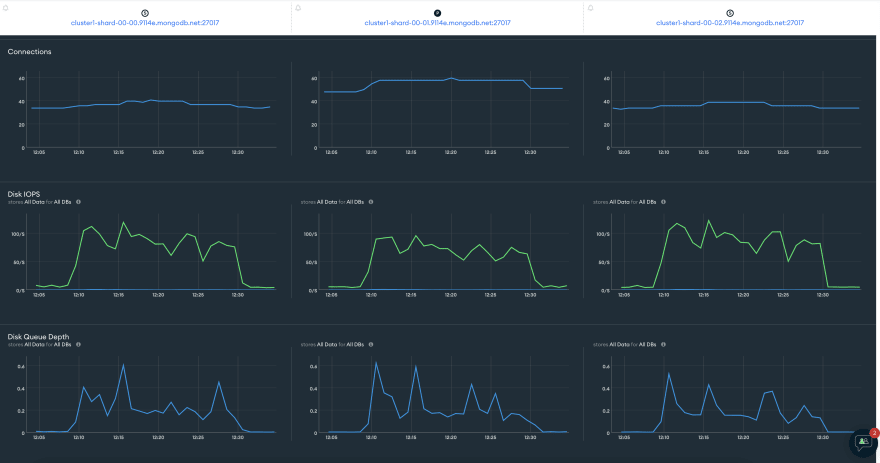
iops几乎从50增加到100增加了一倍,连接也从40增加到〜60。
。我确定这里有一个重要的改进方法,但是在大多数情况下,这个结果很好。现在使用这种并行化,我们可以在大小的数据上获取。
插入超过50ð
要使此测试实现,我们需要大量数据,对吗?因此,我选择了steam dataset在Steam上大约50000多种游戏的用户评论。另外,我提到,在弄乱插入脚本之前,我们需要了解到处的记录。
数据集文件夹的快速概述
此数据集由文件夹组成,每个文件夹都包含10到2000个JSON文件。每个JSON可能包含任何数量的评论。
在当前示例中,脚本应主要在每个文件夹上迭代,读取文件并保存在那里的评论数组长度的计数器。查看JSON文件中的一个评论:
如您所见,此记录是比较数据集的最大文档。
我想在此脚本中做的一件事是添加一些输入参数以限制我们的文件夹的分页。它将让我们通过为每个过程选择一系列文件夹来测试数据子集并同步插入。现在让我们检查脚本本身!
第2行âminimist软件包用于使易于阅读节点过程中的CLI参数。现在可以像这样使用* node inde.js -from = 1 - to = 55*
第11行使用fs.promises.readdir
列表目录第13行选择数据集文件夹内的路径,并将其切成我们将要使用的确切范围。
第18行 - 循环内部的每条路径都包含一个没有JSON文件的文件夹,并且应该在此处执行相同的操作 - 列出所有JSON文件,使用fs.promises.readdir。
内心路径包含我们需要迭代的JSON文件的所有路径。我使用的是radash.selly以更快地读取文件。另外,这里没有流,因为几乎每个文件都不大于100kb。
第27行 - 从缓冲弦和读取键的阅读长度中解析JSON。总结DonereadingReview var。
第33行上有一个重要的控制台日志。由于稍后可以平行数据插入,因此我们需要知道读取多少个文件夹以积累下一百万个记录。是时候运行这个怪异的脚本了!
node insert/50m+/read-size-of-dataset/index.js --from=1 --to=60000
All paths 51936
done paths - 1953 done reviews 1000066
done paths - 3339 done reviews 4000078
........
done paths - 44528 done reviews 59000025
done paths - 51410 done reviews 63000010
Reviews 63199505
Reviews 63199505
Operation took - 429.955 seconds // ~ 7 minutes
在阅读此数据集时,我的笔记本电脑风扇达到了最大RRP。我们什么时候在这里有:
-
51936文件夹
-
令人难以置信的63 199 505记录!
-
阅读7分钟的时间(这只是计算长度)
让我们计算使用以前的步骤(7ð/14m)2H(约126分钟)插入63ð(大约126分钟)需要多长时间。我认为我们可以放弃这一点。
插入6300万记录
正如我们在权力之前所看到的那样。使用上一节的日志输出,我们应将日志分为6个均匀的部分。然后重复使用完成路径零件为-from和toparams输入我们的下一个脚本。它将导致这些对:
1 - 14454
14454 - 25104
25104 - 28687
28687 - 34044
34044 - 42245
42245 - 52000
由于我们已经准备好计数脚本以将范围用于文件夹,因此下一步只是添加插入。让我们回顾就绪脚本及其主要部分!
是3个已更改的主要部分:
第46行 - 我们只是将新评论推入数组
第55行65â当评论比阈值更多的评论时,它们插入了mogno,当循环在最后一次迭代中时,我们强行插入数据以确保所有数据都插入
>第87行插入功能,每20k和parallelly插入
由于我们已经为早期的同一数据集大小的块定义了对,所以我想我们可以尝试在6个并行过程中运行插入脚本。为了使事情变得简单,让我们只打开6个终端窗口并运行它!您始终可以在Node.js和pm2工具中使用内置的worker threads模块,但是我们的实验可以满足最原始的解决方案。测试时间!

每个并行执行的结果:
--from=*1* --to=*14454*
Done reading reviews: *10 963 467
*Script: took - *4963*.*341* seconds ~ 1h 22m
--------
--from=*14454* --to=*25104
*Done reading reviews: *10 498 700
*Script: took - *5016*.*944* seconds ~ 1h 23m
--------
--from=*25104* --to=*28687*
Done reading reviews: *10 874 942
*Script: took - *5050*.*838* seconds ~ 1h 24m
---------
--from=*28687* --to=*34044
*Done reading reviews: *11 659 485
*Script: took - *5088*.*016 * seconds ~ 1h 24m
---------
--from=*34044* --to=*42245
*Done reading reviews: *10 044 895
*Script: took - *4796*.*953* seconds ~ 1h 19m
---------
--from=*42245* --to=*52000*
Done reading reviews: *9 158 016
*Script: took - *4197* seconds ~ 1h 9m
插入记录的63ð花了大约1小时24分钟!它比我们先前的顺序插入预测快33%!我们在一个半小时的时间内加载了近45GB的数据。那mongo呢?
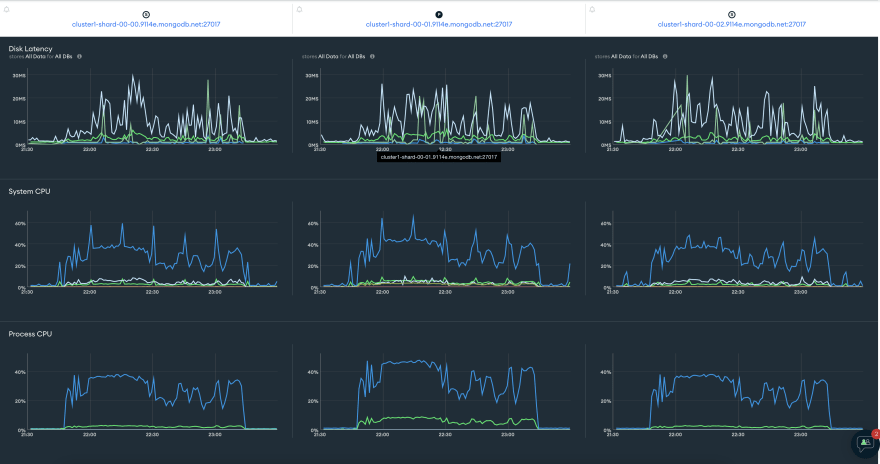

这些插入物非常重载集群。最大系统CPU 〜65%,整个期间的过程CPU约为40%。连接几乎整个时间都保持在100,IOPS平均为125。我想这些结果已经足够好了!
还有一件事
所描述的所有方法都是一般绩效的改进。但是,还有一个特定于驱动程序的黑客,您可以根据您的项目使用。
mongodb insertmany方法具有options参数,您可以更改以使插入更快:
-
writeconcern
-
订购
使用它们也可能会加快插入。
,但是您需要记住:订购:false不允许您依靠文档的插入顺序。
writeconcern:{w:0}请求不确认写操作(source)。
如果这些都不意味着您欢迎使用应用程序!
包起来!
-
您可以使用insertmany轻松插入1M记录。它不应对您的应用程序性能产生任何巨大影响。
-
从1m到10m的加载可能要求您使用流API和插入物的一些并行化。由于插入时间和增加写入负载,它可能会影响应用程序的性能。
-
要加载超过1000万个过程,您需要并行化两个过程和插入才能使其快速。由于群集CPU和IOPS经常使用,因此应用程序性能会大大降低。计划脚本运行或调整可以并行执行多少操作/进程
对您的阅读至关重要,希望它能帮助您成为更好的开发人员。