
介绍
MindSDB无疑将一流的机器学习能力带入传统数据库。它充当现有表顶部的AI层,并在简单的SQL语句的帮助下可以轻松,立即训练模型并立即预测结果。
MindSDB提供了大量的集成,几乎所有可用数据库和许多ML框架,使用户更容易与MindSDB一起轻松管理其现有数据基础结构。此外,MinsDDB以两种方式提供其服务,即本地部署(使用Docker或Pip)和MindSDB Cloud,这两者都为所有消费者提供了免费级别。
在本教程中,我们将使用MindSDB Cloud的功能集来预测葡萄酒的质量。
将数据导入MindSDB云
我们可以从Kaggle,Datahub,Google DataSet搜索等任何可用来源获得免费数据集来训练我们的预测模型。我们将使用Kaggle的this dataset进行本教程。
所以,让我们开始从将此数据集添加到MindSDB Cloud的过程中。
步骤1:我们需要首先将sign in转到MindSDB Cloud Console或启动registering的新帐户。
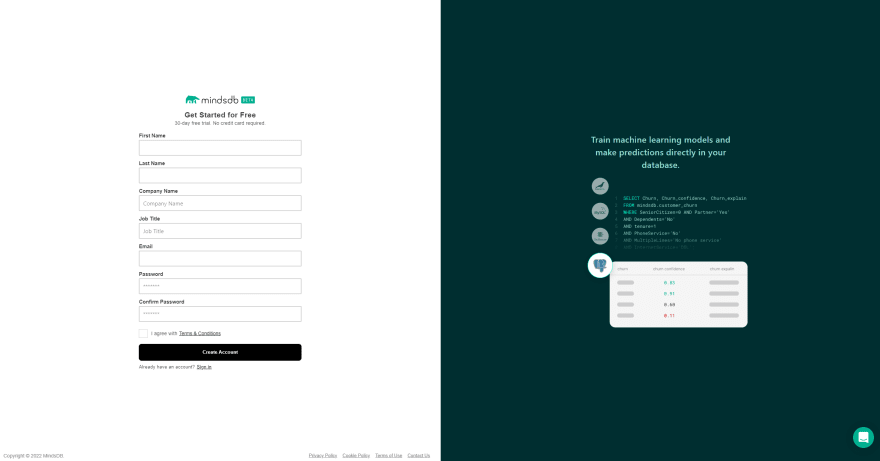
步骤2:登录后,它将打开MindSDB云编辑器。我们在顶部找到一个查询编辑器,我们可以编写查询,然后击中其上方的Run(Shift+Enter)按钮以执行它们,结果查看器在结果为为查询显示,最后,我们在右侧有学习中心,可作为新用户的学习帮助。
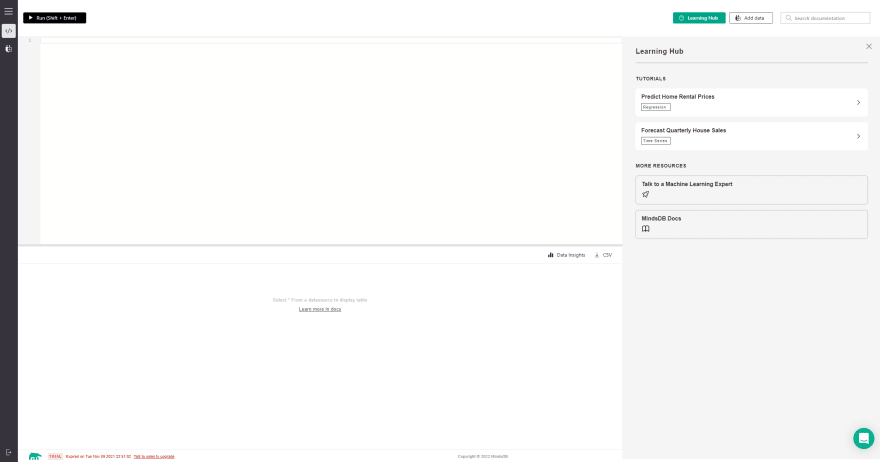
步骤3:现在从右上角找到Add Data按钮,然后点击它。然后在顶部的标签切换到Files而不是Databases,然后单击Import File按钮。

步骤4:现在单击Import File部分,浏览我们刚刚从上面链接下载的数据集文件并选择它。在Table name字段中提供表格的名称,然后单击“ Save and continue”按钮以启动导入过程。

步骤5:在成功导入数据集后,我们将重新定向到MindSDB云编辑器。查询编辑器现在将在其中列出两个基本的SQL查询。
让我们一一执行它们并检查结果。
第一个查询应显示可用表的列表。确保列表中有一个表格,并在导入数据集时提供了上面提供的名称。
SHOW TABLES FROM files;

第二个查询使您可以检查我们刚刚导入的表中是否存在正确的数据记录。
SELECT * FROM files.Wines LIMIT 10;
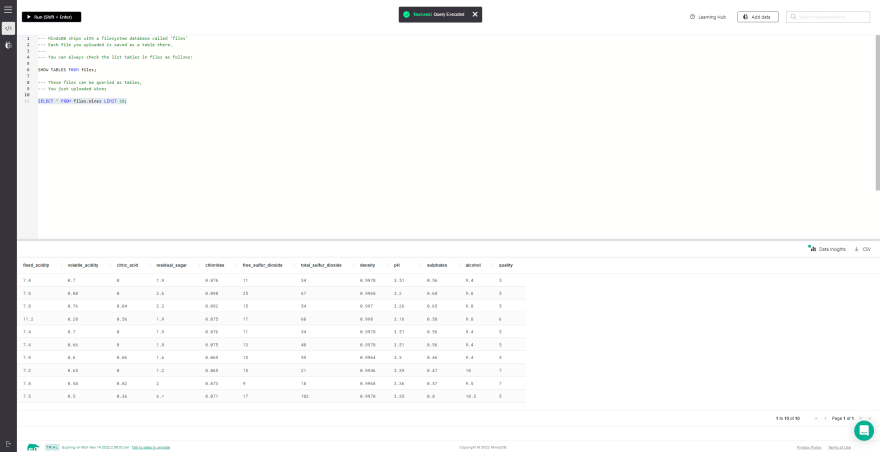
我们现在已经准备好数据表,现在可以继续下一节。
训练预测指标模型
使用MindSDB,训练预测器模型可以像编写SQL查询然后执行它一样容易。因此,让我们看看如何通过遵循以下步骤来做到这一点。
步骤1: MindSDB提供了一个CREATE PREDICTOR语句,我们可以用来创建和训练模型。语法的格式如下。
CREATE PREDICTOR mindsdb.predictor_name (Your Predictor Name)
FROM database_name (Your Database Name)
(SELECT columns FROM table_name LIMIT 10000) (Your Table Name)
PREDICT target_parameter; (Your Target Parameter)
带有real field_names而不是占位符的真正查询看起来像下面的一个。
CREATE PREDICTOR mindsdb.wine_predictor
FROM files
(SELECT * FROM Wines LIMIT 10000)
PREDICT quality;

步骤2:该模型可能需要一些时间来根据所提供的培训数据的规模来完成培训。
在等待时,我们可以使用以下命令检查模型的状态。如果查询返回complete,则该模型准备好进行预测。但是,如果它返回generating或training,建议等到状态为complete。
SELECT status
FROM mindsdb.predictors
WHERE name='Name_of_the_Predictor_Model';
真正的查询将是这样的。
SELECT status
FROM mindsdb.predictors
WHERE name='wine_predictor'
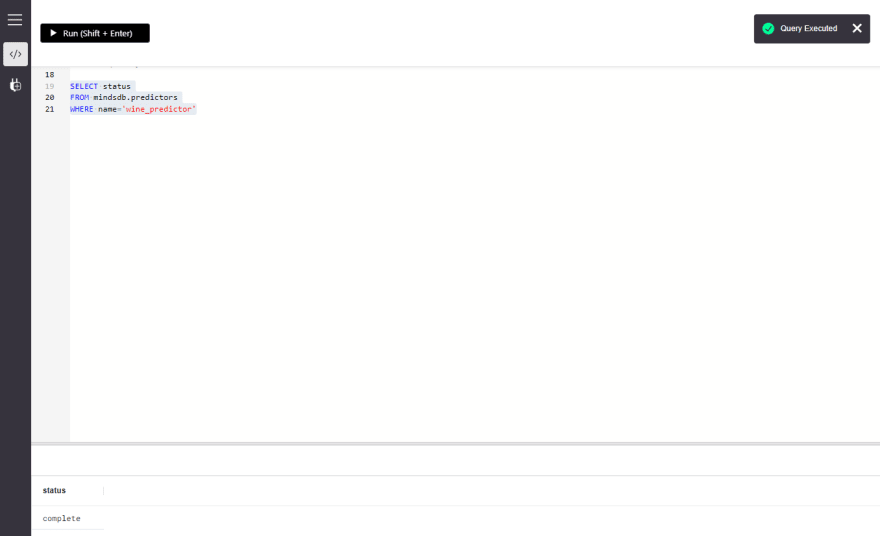
当我们获得complete状态时,我们现在可以对葡萄酒质量进行预测。
描述预测指标模型
在直接跳入预测之前,了解有关我们的预测变量模型的细节确实非常重要。
因此,在本节中,我们将尝试使用DESCRIBE语句以3种不同方式来弄清我们的模型的详细信息。
- 通过功能
- 模型
- 模型合奏
通过功能
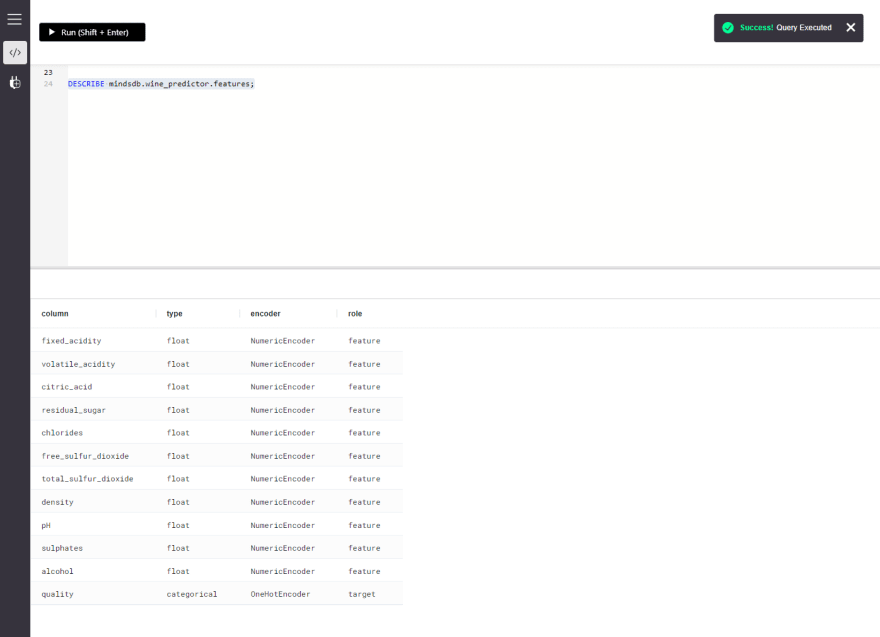
此查询旨在返回表中的每一列的角色,并提及在这些列上使用的每一列上使用的特定编码器来训练模型。
DESCRIBE mindsdb.predictor_name.features;
按模型
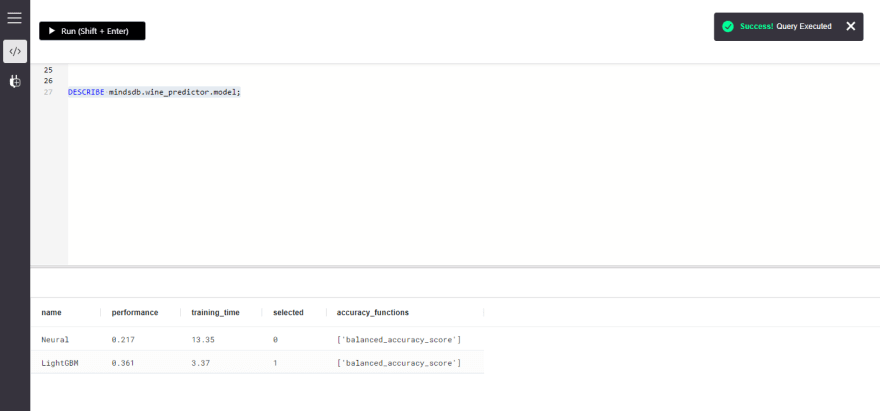
此查询获取培训期间使用的所有可用候选模型的列表。在其selected列下具有1的候选模型被选择用于预测器模型,并且应该具有best performance值。
DESCRIBE mindsdb.predictor_name.model;
通过模型合奏
此查询旨在为我们提供一个带有不同参数列表的JSON输出,这些参数有助于确定预测变量的最佳候选模型。
DESCRIBE mindsdb.predictor_name.ensemble;

现在是时候进入预测葡萄酒质量价值的有趣部分了。
查询模型
MindSDB仅在SELECT语句的帮助下提供了预测目标值的便利性。在这里,我们可以使用简单的SELECT查询来预测葡萄酒的质量,并要求该模型返回预测的质量。
应该注意的是,葡萄酒的质量完全由多个特征值确定。如果遗漏了其中一些特征值,则准确性可能会降低。
,但让我们仍然尝试根据具有这样的查询的一些功能集来预测葡萄酒质量。
SELECT target_value_name, target_value_confidence, target_value_confidence
FROM mindsdb.predictor_name
WHERE feature1=value1 AND feature2=value 2,...;
我们的真实查询将采用像这样的特征参数集的值。
SELECT quality,quality_confidence,quality_explain
FROM mindsdb.wine_predictor
WHERE pH=3.3 AND density=0.997 AND alcohol=9.4 AND sulphates=0.46;
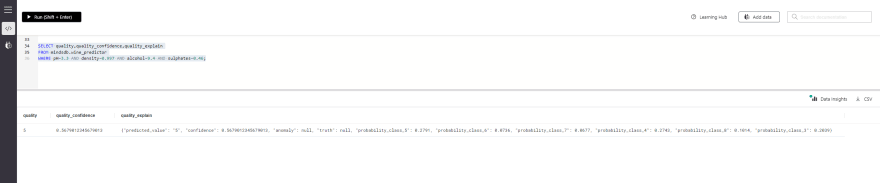
这里预测的quality(葡萄酒质量)为5,因此葡萄酒既不能被称为好也不好。
是时候传递所有功能集的值以具有更准确的预测了。现在,这使查询像下面的查询一样。
SELECT quality,quality_confidence,quality_explain
FROM mindsdb.wine_predictor
WHERE pH=3.5 AND density=0.9976 AND alcohol=13 AND sulphates=0.86
AND fixed_acidity=10.3 AND volatile_acidity=0.3 AND citric_acid=0.72
AND residual_sugar=2.5 AND chlorides=0.075 AND free_sulfur_dioxide=11
AND total_sulfur_dioxide=20;

这绝对可以称为质量高的葡萄酒,因为价值为8。
就是这样!现在,我们已经成功地使用了预测变量模型来预测葡萄酒质量。
注意:
quality_confidence,quality_explain之类的参数将分别为我们获取置信价值和其他细节,例如异常,真实价值和概率类。
结论
这标志着教程的结尾。现在该快速回顾了。最初,我们从创建MindSDB云帐户,导入数据集并使用Cloud GUI创建表,创建和训练了一个预测模型,以三种可能的方式描述了其模型详细信息,并最终预测了葡萄酒的质量。
。随着本教程现在已经结束,我建议大家免费创建自己的MindSDB帐户,然后旋转。您也可以在本地安装和使用它。所有相关的说明都可以找到here。
最后,在您离开之前,不要忘记在下面的Comments部分中键入反馈中的键,并通过在本文中删除LIKE来显示一些爱。

