在我写过有关HarperdB的前几篇文章中,我们探索了Kubernetes和Helm的领域。现在是时候退后一步,尝试理解它在这篇短而直接的文章中提供的另一个很酷的功能。
让我们想象我们为一家公司工作,该公司为全球大型工厂的生产流程提供商业智能,并且您正在推出新产品;聪明的工厂!为此,工厂将配备最多种类型的传感器,这些传感器可以监视几种机器的关键特性,例如压力,温度和重量。
问题在于,所有这些数据都需要发送回公司的主要服务器,以便我们可以在其顶部应用机器学习模型和大数据分析。他们要求您提供一个不错的架构来实现它。该过程有一些规则:
- 传感器以非常快速的速率发送数据,因此将其发送给您的网络会使网络混乱,使数据流成为次级最佳解决方案。
- 数据应以原始格式存储在公司的数据库中。
- 即使在网络故障的情况下,传感器也会继续发送数据。您需要在网络返回后立即将数据与公司的服务器同步。
- 公司必须能够将配置发送到总部安装在客户中的传感器,而无需进行本地访问。
如何使用最少的精力和最佳技术执行所有这些任务?输入 harperdb簇。
集群
当我们说群集时,出现的基本想法是像库伯尼特一样,对吗?一堆虚拟机,表现为单一的大型机器。但是,Harperdb将这个想法更进一步。由于我们谈论的是一个数据库,因此“作品作为一个工作”的概念最终归结为拥有相同的数据,实际上,这是一组数据库的概念。
但是,在其他DBS中,所有数据都将在整个集群中复制,无论如何它们最终都会相同,那么您为什么不能选择要同步的数据?
当您将两个或多个HarperDB数据库的实例群群集在一起时,他们会询问您要共享的数据,这称为 subscription 。因此,基本上,HarperDB拥有的是非常强大且奇特的实现,该模型在表级别上有效,并且具有耐故障机制,使其可以在任何给定时间丢失连接,并自动重新同步。备份后数据。
集群如何工作?
我不会在这一部分中扩展自己,因为Harperdb具有very nice documentation about it6,但其想法是,每个数据库在群集中构成了节点,并且整个群集中的整个节点及其群体及其及其组中的整个节点配置称为拓扑。
要发送和接收数据,节点依赖于 channel ,称为schema:table,每个通道代表两个节点之间的连接,从特定表中发送或接收数据。频道有两个选择,它们可以是发布者,订阅者或两者兼而有之。
a 发布通道将将该特定表的所有更改发布给订阅其的任何其他节点,让我们看看一个示例。如果我想在表 dog 上发布从第一个节点到第二个节点的架构中的所有更改,我可以创建发布频道< /strong>称为dev:dog。
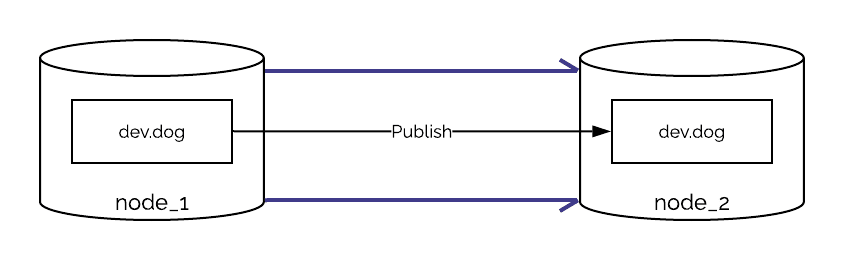
另一方面,我可以用不同的方式表达它,我可以说我想听节点1中的 dog 表中的所有更改,所以我可以订阅它:

当您在任何节点中创建订阅时,该特定表的任何更改都将同步到其他表,dev:dog上的任何新数据都将发布给其他节点,以及任何更新或删除。如果表格中不存在该表,则还将创建它,但是,**像drop这样的破坏性操作将不会传播。
创建群集
因此,您决定创建概念证明,以查看您使用HarperdB簇的想法是否会起作用。由于Harperdb具有可用的docker映像,因此我们将首先创建一个Docker组成的文件。
这个想法是模拟HarperdB节点的两个实例,并将它们都连接到群集中。为此,我们将在您的Docker组合中创建两个服务,第一个将是代表传感器的服务:
services:
harper-edge:
image: harperdb/harperdb
container_name: harper-edge
ports:
- "9900:9925"
- "9901:9926"
- "62000:62344"
environment:
- HDB_ADMIN_USERNAME=admin
- HDB_ADMIN_PASSWORD=admin
- CLUSTERING=true
- CLUSTERING_USER=cluster
- CLUSTERING_PASSWORD=cluster
- CLUSTERING_PORT=62344
- NODE_NAME=harper-edge
我们将打开端口9925、9926和62344,但是由于我们将在同一台计算机中旋转另一个服务,因此我们不能仅使用相同的端口,因此我们将它们分别映射到9900、9901和6200 。我们将在环境变量中启用聚类,然后将群集端口设置为62344,因为我们在端口清单中设置了。最后,我们将节点命名为 harper-edge 。
对于将代表公司服务器的第二个实例,我们将复制第一部分,然后更改名称和端口,最终文件将如下:
services:
harper-edge:
image: harperdb/harperdb
container_name: harper-edge
ports:
- "9900:9925"
- "9901:9926"
- "62000:62344"
environment:
- HDB_ADMIN_USERNAME=admin
- HDB_ADMIN_PASSWORD=admin
- CLUSTERING=true
- CLUSTERING_USER=cluster
- CLUSTERING_PASSWORD=cluster
- CLUSTERING_PORT=62344
- NODE_NAME=harper-edge
harper-host:
image: harperdb/harperdb
container_name: harper-host
ports:
- "9902:9925"
- "9903:9926"
- "62001:62344"
environment:
- HDB_ADMIN_USERNAME=admin
- HDB_ADMIN_PASSWORD=admin
- CLUSTERING=true
- CLUSTERING_USER=cluster
- CLUSTERING_PASSWORD=cluster
- CLUSTERING_PORT=62344
- NODE_NAME=harper-host
我们只是在端口中总结1个,以免冲突,也更改节点的名称。这里重要的部分是群集用户和密码在两种服务中都必须相同。
让我们用docker compose up旋转,您应该看到两个正在运行的HarperDB实例的结果。现在,让我们去HarperDB Studio并注册它们。只需创建您的帐户,组织,然后单击注册一个新的用户管理的实例。这应该是我们拥有的数据:
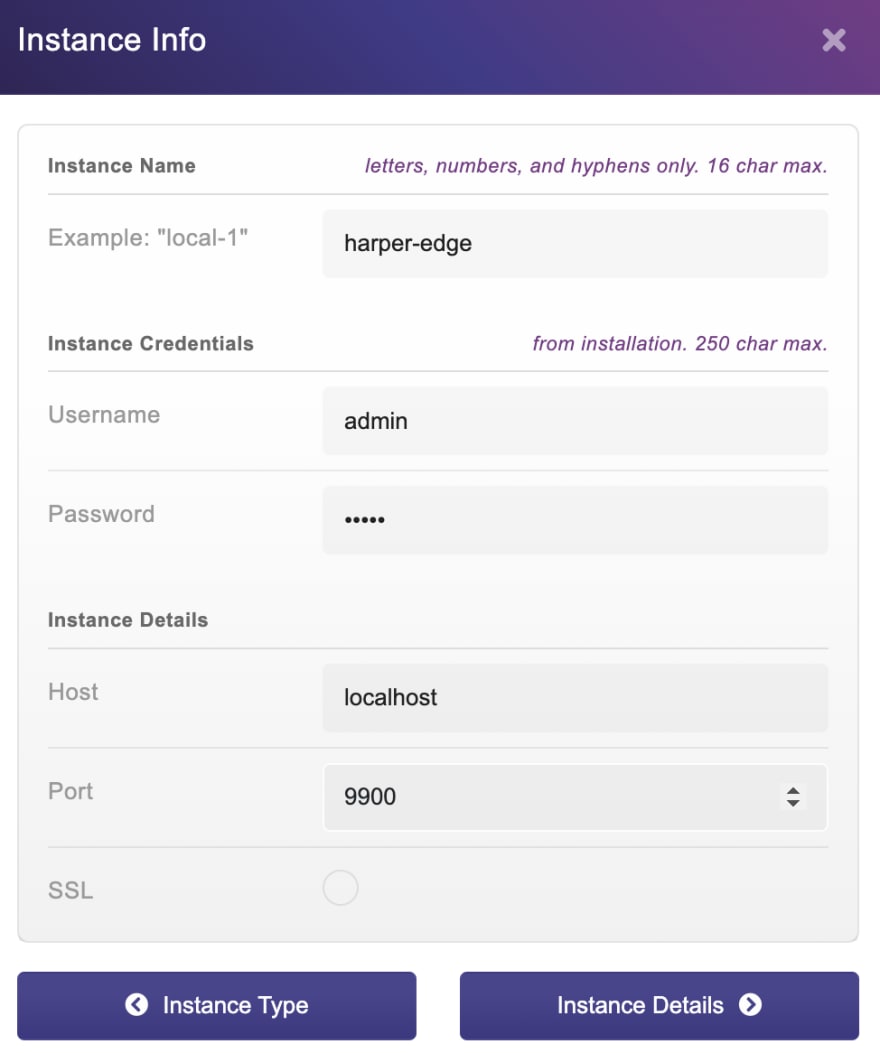
选择免费实例并接受条款,我们应该准备去:
让我们对另一个做同样的事情:

什么将更改仅是端口号,现在是9902。
连接节点
我们不会在任何实例上创建任何表。取而代之的是,让我们跳入我们的工作室,转到任何这些实例的“群集”选项卡:

如您所见,我们列出了其他节点,但是当我们尝试连接时,我们会收到一个错误:
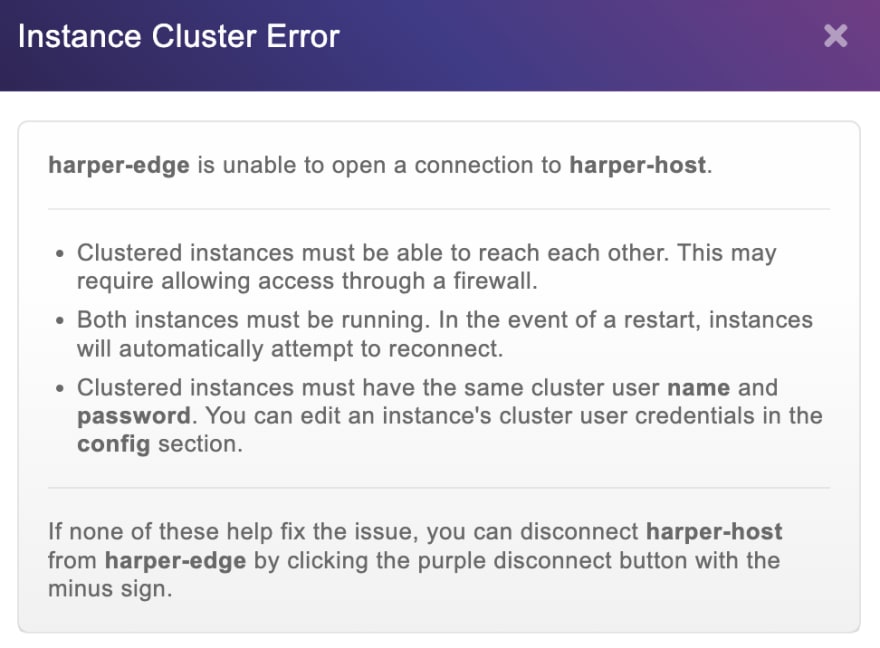
由于我们正在使用Docker,因此该实例无法通过Harperdb Studio连接到集群中的另一个节点,在这种情况下,我们需要将这些问题掌握在我们自己的手中。<<<<<<<<<<<<<<< /p>
HarperdB具有一个API,可让您在两个节点之间手动创建连接。在任何请求工具上,您都有邮递员,失眠或任何其他任何其他url:http://localhost:9902在邮政请求中。您可以使用任何主机来做我们将要做的事情,但是要保持项目的想法,让我们连接到代表公司数据库的主机。
在“身份验证”部分中,我们将使用基本的HTTP auth,用户名和密码是我们在撰写文件中定义的密码,在这种情况下,它们俩都是admin。现在我们将创建一个看起来像这样的JSON机构:
{
"operation": "add_node",
"name": "harper-edge",
"host": "harper-edge",
"port": 62344,
"subscriptions": []
}
因此,从公司的数据库中,我们要发布配置和 subscribe 传感器数据,让我们告诉节点,subscriptions键内有两个对象:
{
"operation": "add_node",
"name": "harper-edge",
"host": "harper-edge",
"port": 62344,
"subscriptions": [
{
"channel": "default:sensor_data",
"subscribe": true,
"publish": false
},
{
"channel": "default:configs",
"subscribe": false,
"publish": true
}
]
}
现在,我们回到工作室并登录 harper-host 实例。我们将创建名为default的模式和一个名为configs的表。

现在,让我们通过单击右上角的+按钮添加一个简单的数据:

保存后,让S切换到harper-edge实例,然后查看!我们现在有一个配置表,在该表中,我们有相同的项目刚刚添加:
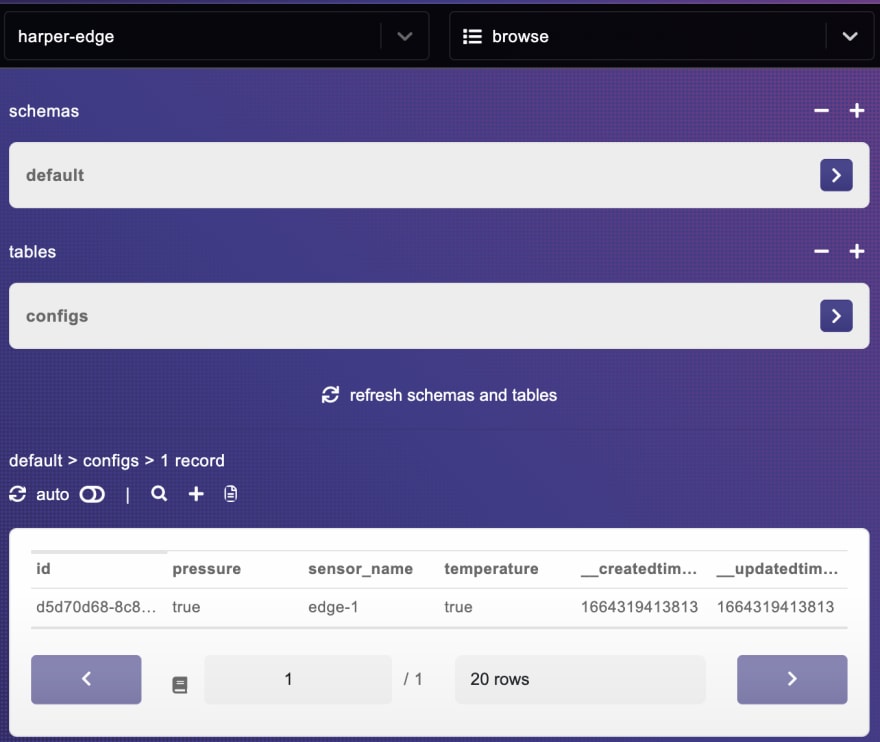
让我们在harper-edge实例上进行相同的操作,然后添加一个名为sensor_data的表,然后用id hash添加一些数据,然后添加一些数据:
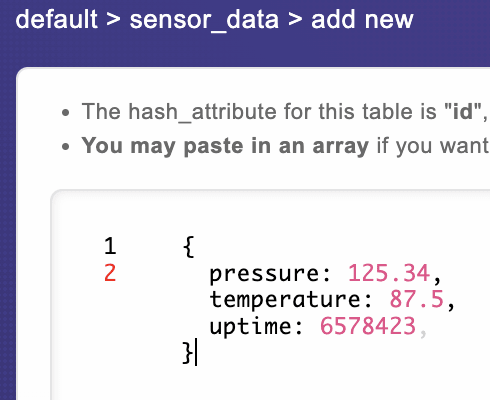
,如果我们切换回主机,我们还在那儿也有相同的数据:

这是有效的,即使我们删除了一个侧面的数据,在这种情况下,另一端的数据也将被删除。
结论
这是这一惊人功能的第一个瞥见。请继续关注下一个教程,以了解我们如何使用Harper的Pub/sub在其他现实世界中为我们提供帮助。