
介绍
您是一个对传统数据库做得如此的人吗?
您是否无法从数据集中提取大量价值?
您是否担心将机器学习模型用于数据?
好吧,您现在可以将所有的担忧抛在后面,因为您可能与MindSDB拥有多合一的解决方案。顾名思义,MindSDB从字面上向您添加了Mind/Brain,并通过直接从数据库中的可用数据集启用简单的数据预测,而无需任何其他设置。
。当前,MindSDB同时为其所有用户提供免费的社区版本和付费版本,并且用户可以从两个可用的托管模型中进行选择,即通过Docker/pip或MindSDB Cloud。
。今天,让我们在使用MindSDB时学习一个重要方面之一,即创建视图。
创建视图将需要两件事。
- 数据集
- 预测模型
所以,让我们开始添加数据集,然后创建预测模型。
导入数据集
我们将使用MindSDB云来执行创建视图所需的所有操作。让我们从logging in/ signing up开始到MindSDB帐户,然后遵循以下步骤。
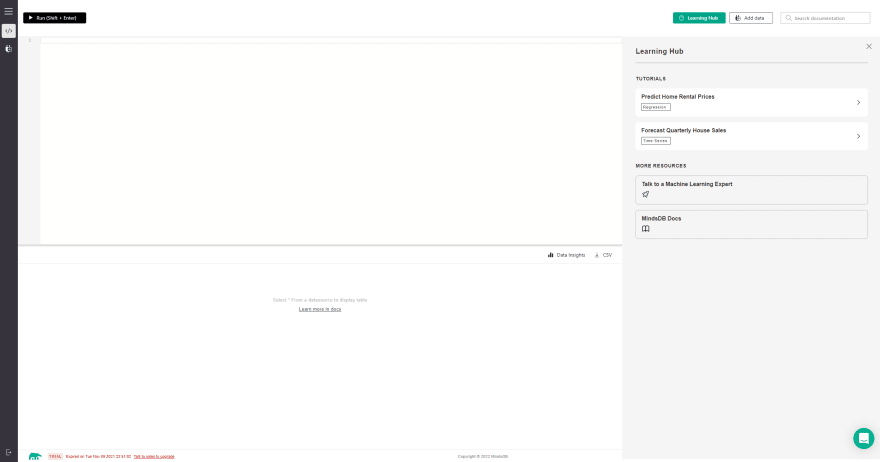
步骤1:登录后,您会发现MindSDB云编辑器加载在您面前。它在顶部包含一个查询编辑器,底部的结果查看器和屏幕右侧的学习中心资源。
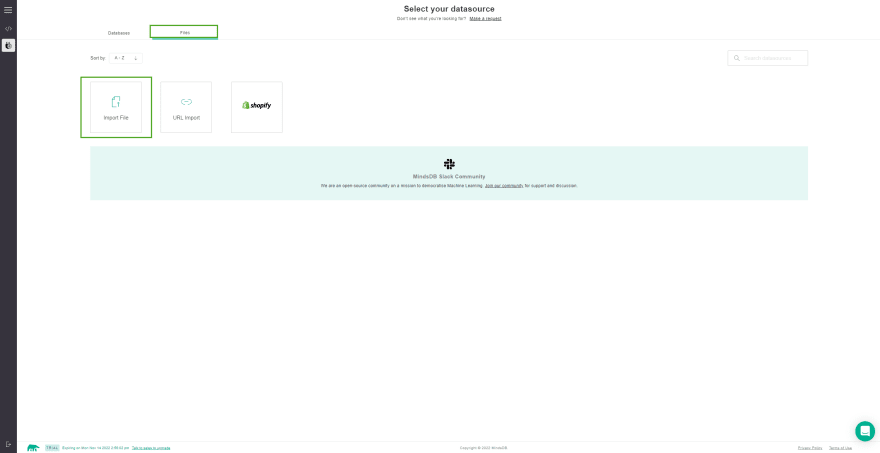
现在单击Add Data,然后将选项卡切换到Files而不是Databases,然后按Import File按钮。
步骤2:我们将使用Uber Trips Dataset并创建一个预测器来预测旅行票价。
因此,选择您刚刚下载的文件,单击Import a File部分,为我们将在Table name部分中创建的表格提供一个名称,然后单击Save and Continue。

步骤3:导入文件后,我们可以运行两个基本查询,现在可以在Cloud UI中的查询编辑器上找到这些问题,以检查新表是否与新表格在一起正确的记录。
Show Tables;
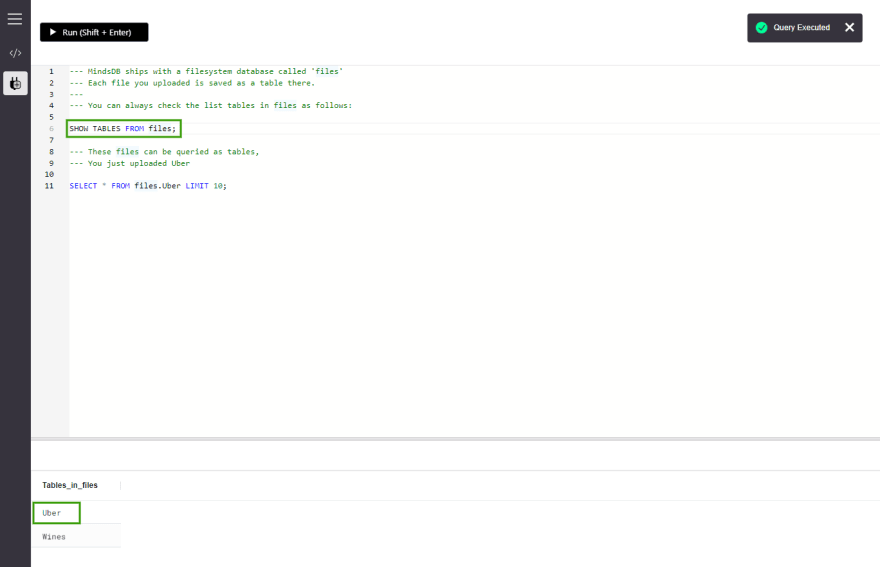
SELECT * FROM files.Uber LIMIT 10;
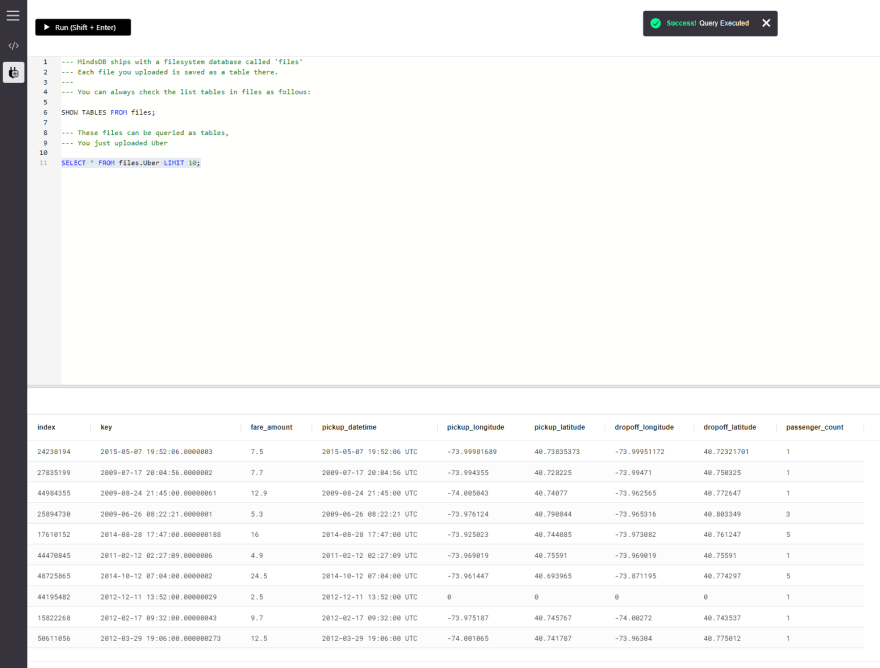
我们可以看到,数据记录存在,这意味着我们已经成功地完成了将数据集导入到我们的MindSDB Cloud Console中。
创建预测模型
我们可以使用简单的SQL语句轻松地在MindSDB中创建预测模型。让我们看看如何在下面做到这一点。
MindSDB提供了一个CREATE PREDICTOR语句,我们现在将使用该语句来创建和训练模型。
CREATE PREDICTOR mindsdb.uber_predictor
FROM files
(SELECT dropoff_latitude,dropoff_longitude,passenger_count,pickup_datetime,pickup_latitude,pickup_longitude,fare_amount FROM Uber LIMIT 10000)
PREDICT fare_amount;
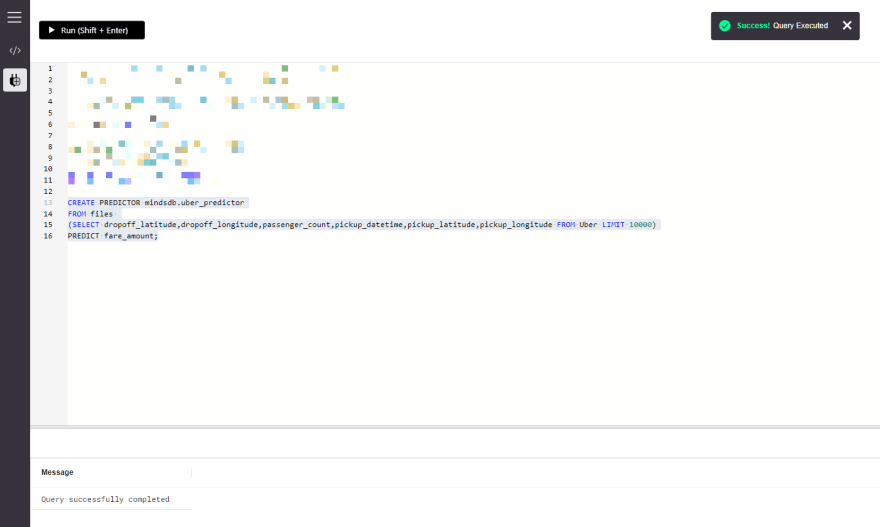
模型可能需要一段时间才能训练。我们可以使用以下模型检查模型的当前状态。
SELECT status
FROM mindsdb.predictors
WHERE name='uber_predictor';
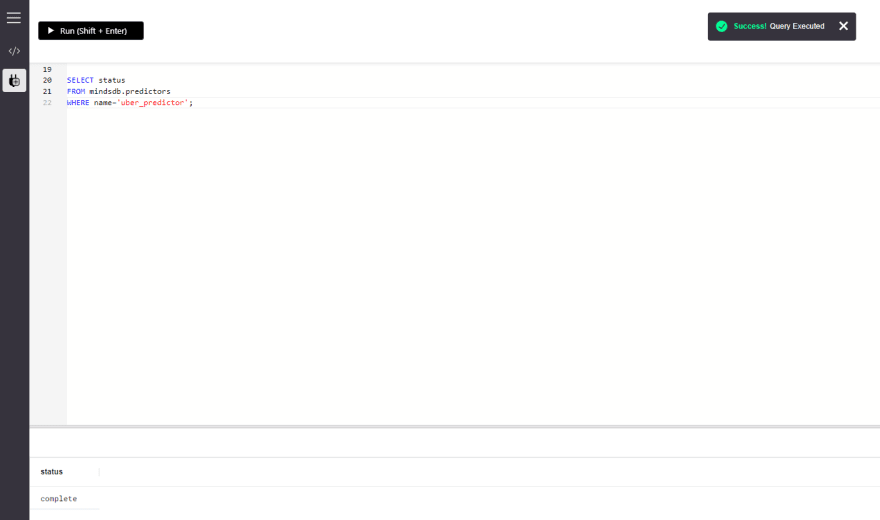
由于当前状态为complete,我们现在准备进行预测。但是,如果状态为generating或training,请等待状态为complete。
创建视图
在前面的部分中,我们已经完成了创建两个创建视图的必需项目,即数据集和一个预测模型。
在本节中,我们将从创建视图开始。但是,让我们首先了解一种观点。
MindSDB为我们提供了CREATE VIEW语句,该声明为我们创建了一个视图。换句话说,此语句创建了一个AI表。
AI表通常由原始数据集表组成,即Uber表和预测器模型,即Uber_predictor。
所以,CREATE VIEW语法将看起来像这样。
CREATE VIEW [new_view_name] AS (
SELECT
T.[Feature_column_name1],
T.[Feature_column_name2],
T.[Feature_column_name3],
P.[target_column] AS target_column_name
FROM [database_name].[table_name] AS T
JOIN mindsdb.[predictor_model_name] AS P
);
让我们弄清楚这些参数的实际含义。
- new_view_name-> 要创建的新视图的名称
-
t-> table
Uber。 的别名
-
feature_column_name1-> 功能列的名称要包含在表中的视图中的
Uber。 - p-> 预测模型的别名。
- target_column-> 必须预测的列。
- target_column_name-> 要在视图上显示的目标列的名称。
- database_name-> 存在该表的数据库名称。
-
table_name-> 原始数据表的名称,即
Uber - preditionor_model_name-> 预测器模型的名称
当我们用实际的列名代替占位符时,实际查询将看起来像这样。
CREATE VIEW UberFare AS (
SELECT
T.pickup_latitude,
T.pickup_longitude,
T.dropoff_longitude,
T.dropoff_latitude,
T.passenger_count,
T.pickup_datetime,
P.fare_amount AS Fares
FROM files.Uber AS T
JOIN mindsdb.uber_predictor AS P
);

当我们执行上述语句时,查询应返回successful状态。这确认了最终创建了视图。
查询视图
当我们创建视图时,让我们现在尝试使用一些简单的选择语句来获取视图。
SELECT * from views.UberFare;
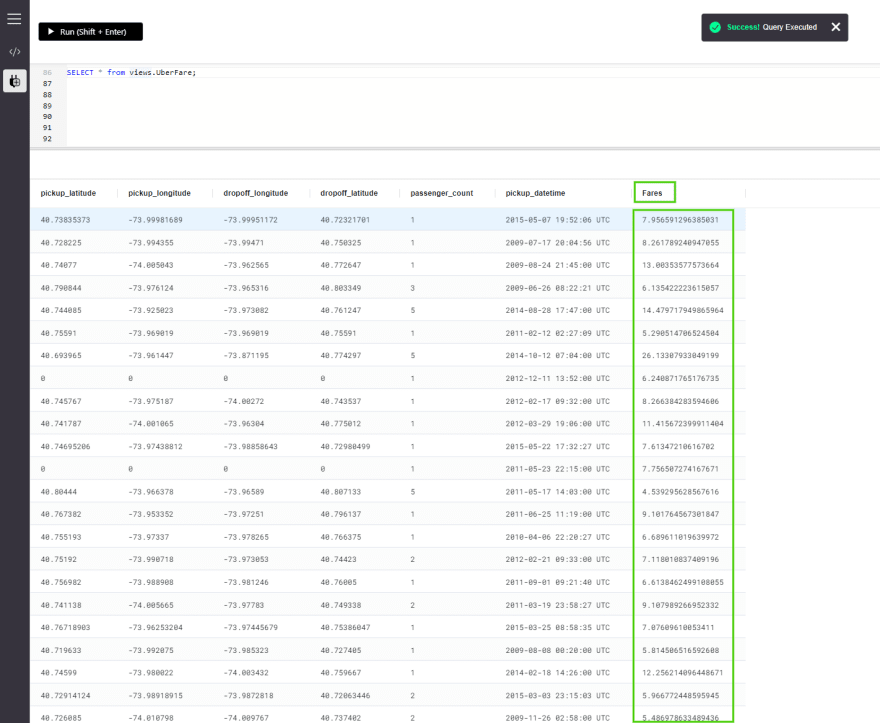
这应该在创建时提供的所有行返回视图(AI表)。您可以标记目标值列名更改为我们在CREATE VIEW语句中设置的名称,即从fare_amount更改为Fares。
另外,您应该注意,此目标列中的值也已更改。这是因为现在Fares列保存了来自模型的预测值,而不是随附数据集的原始值。
您还可以通过某些特定参数,其中何处子句在视图中滤除数据。
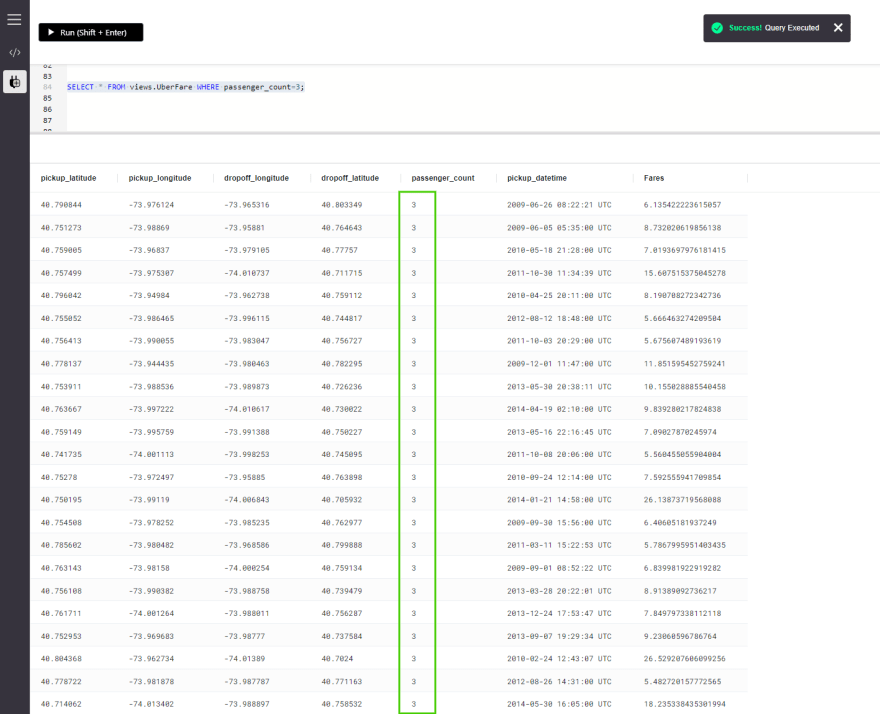
SELECT * FROM views.UberFare WHERE UberFare.passenger_count=3;
这过滤了所有乘客数量为3的视图中的所有记录。
您可以在官方Mindsdb文档页面here中找到有关创建视图的更多文档。
结论
这标志着本教程的终结。因此,让我们总结我们刚刚完成的任务。我们从登录到MindSDB Cloud帐户,下载数据集并将其上传到创建表格,训练了预测模型,创建视图并最终从视图中提取记录。
。MindSDB拥有许多此类令人兴奋的功能。因此,现在该是sign up免费帐户的时候了,并亲自开始使用MindSDB并探索它带给您现有数据库的惊人。
最后,在离开之前,如果您要学习新事物和有价值的东西,请放下LIKE。此外,欢迎读者社区的各种反馈。

