将被刮擦
完整代码
如果您不需要解释,请看一下the full code example in the online IDE
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
const searchParams = {
hl: "en", // Parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
device: "phone", // parameter defines the search device. Options: phone, tablet, tv, chromebook
age: null, // parameter defines age subcategory. Options: null (0-12 years), AGE_RANGE1 (0-5 years), AGE_RANGE2 (6-8 years), AGE_RANGE3 (9-12 years)
};
const URL = searchParams.age
? `https://play.google.com/store/apps/category/FAMILY?age=${searchParams.age}&hl=${searchParams.hl}&gl=${searchParams.gl}&device=${searchParams.device}`
: `https://play.google.com/store/apps/category/FAMILY?hl=${searchParams.hl}&gl=${searchParams.gl}&device=${searchParams.device}`;
async function scrollPage(page, scrollContainer) {
let lastHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
while (true) {
await page.evaluate(`window.scrollTo(0, document.querySelector("${scrollContainer}").scrollHeight)`);
await page.waitForTimeout(4000);
let newHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
if (newHeight === lastHeight) {
break;
}
lastHeight = newHeight;
}
}
async function getKidsAppsFromPage(page) {
const apps = await page.evaluate(() => {
const mainPageInfo = Array.from(document.querySelectorAll("section .oVnAB")).reduce((result, block) => {
const categoryTitle = block.textContent.trim();
const apps = Array.from(block.parentElement.querySelectorAll(".ULeU3b")).map((app) => {
const link = `https://play.google.com${app.querySelector(".Si6A0c")?.getAttribute("href")}`;
const appId = link.slice(link.indexOf("?id=") + 4);
if (app.querySelector(".sT93pb.DdYX5.OnEJge")) {
return {
title: app.querySelector(".sT93pb.DdYX5.OnEJge")?.textContent.trim(),
appCategory: app.querySelector(".sT93pb.w2kbF:not(.ePXqnb)")?.textContent.trim(),
link,
rating: parseFloat(app.querySelector(".ubGTjb:last-child > div")?.getAttribute("aria-label")?.slice(6, 9)) || "No rating",
iconThumbnail: app.querySelector(".j2FCNc img")?.getAttribute("srcset").slice(0, -3),
appThumbnail: app.querySelector(".Vc0mnc img")?.getAttribute("src") || app.querySelector(".Shbxxd img")?.getAttribute("src"),
video: app.querySelector(".aCy7Gf button")?.getAttribute("data-video-url") || "No video preview",
appId,
};
} else {
return {
title: app.querySelector(".Epkrse")?.textContent.trim(),
link,
rating: parseFloat(app.querySelector(".vlGucd > div:first-child")?.getAttribute("aria-label")?.slice(6, 9)) || "No rating",
thumbnail: app.querySelector(".TjRVLb img")?.getAttribute("srcset"),
appId,
};
}
});
return {
...result,
[categoryTitle]: apps,
};
}, {});
return mainPageInfo;
});
return apps;
}
async function getMainPageInfo() {
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".oVnAB");
await scrollPage(page, ".T4LgNb");
const apps = await getKidsAppsFromPage(page);
await browser.close();
return apps;
}
getMainPageInfo().then((result) => console.dir(result, { depth: null }));
准备
首先,我们需要创建一个node.js* project并添加koude0包koude1,koude2和koude3以控制铬(或chrome或firefox,但现在我们仅在DevTools Protocol上使用铬在headless或无头模式中。
在使用我们的项目的目录中,打开命令行并输入npm init -y,然后是npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth。
*如果您没有安装node.js,则可以download it from nodejs.org并遵循安装documentation。
ð注意:另外,您可以使用puppeteer无需任何扩展即可,但是我强烈建议将其与puppeteer-extra一起使用puppeteer-extra-plugin-stealth,以防止您使用无头铬或正在使用web driver的网站检测。您可以在Chrome headless tests website上检查它。下面的屏幕截图显示了差异。

Process
首先,我们需要滚动所有应用列表,直到没有更多的列表加载,这是下面描述的困难部分。
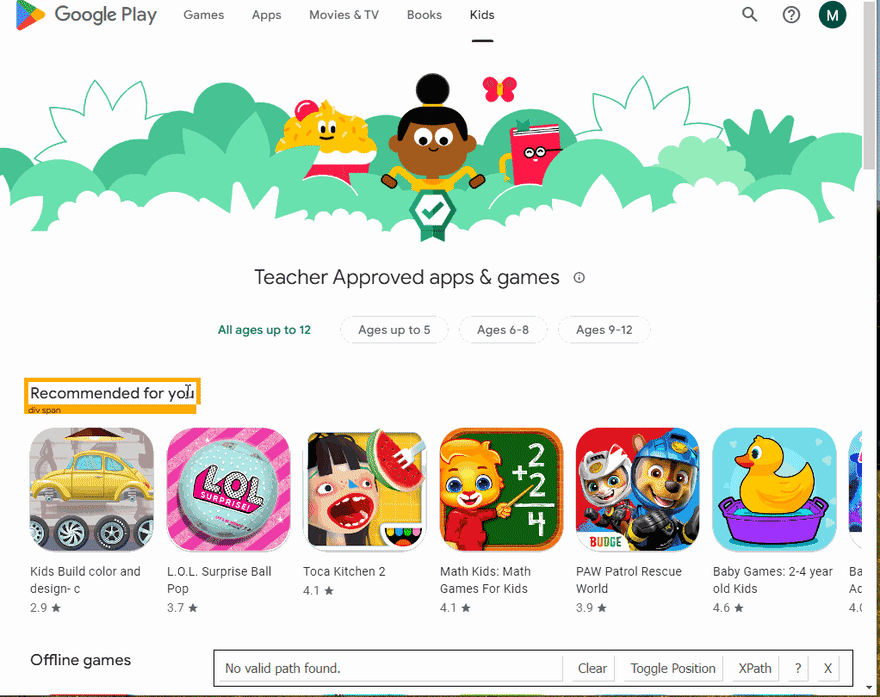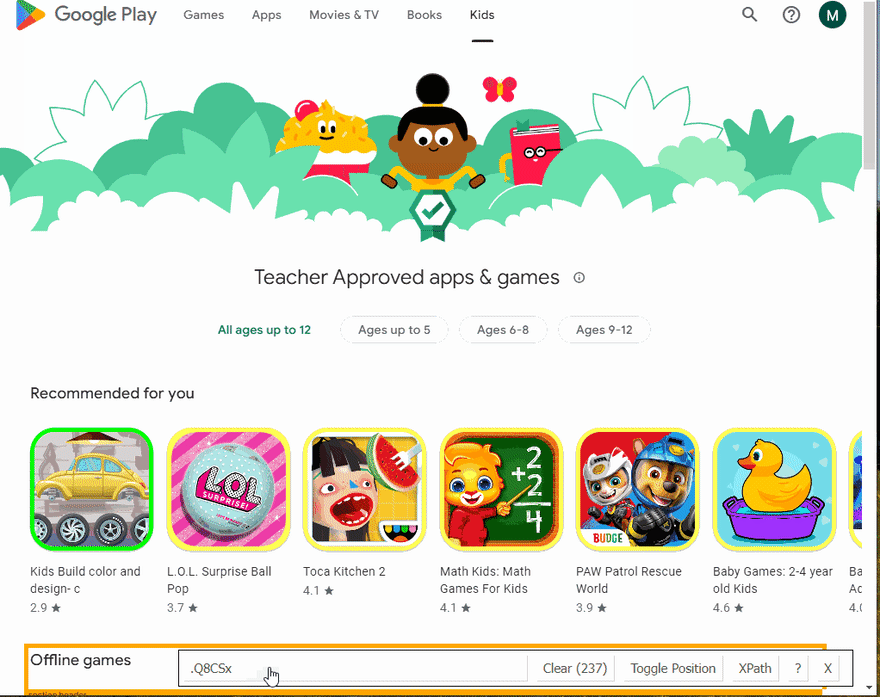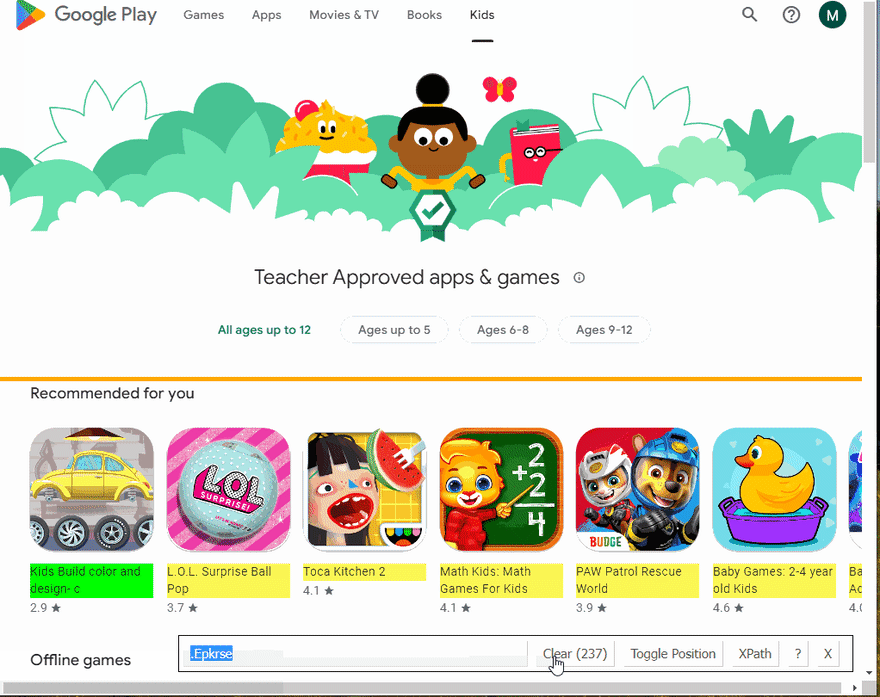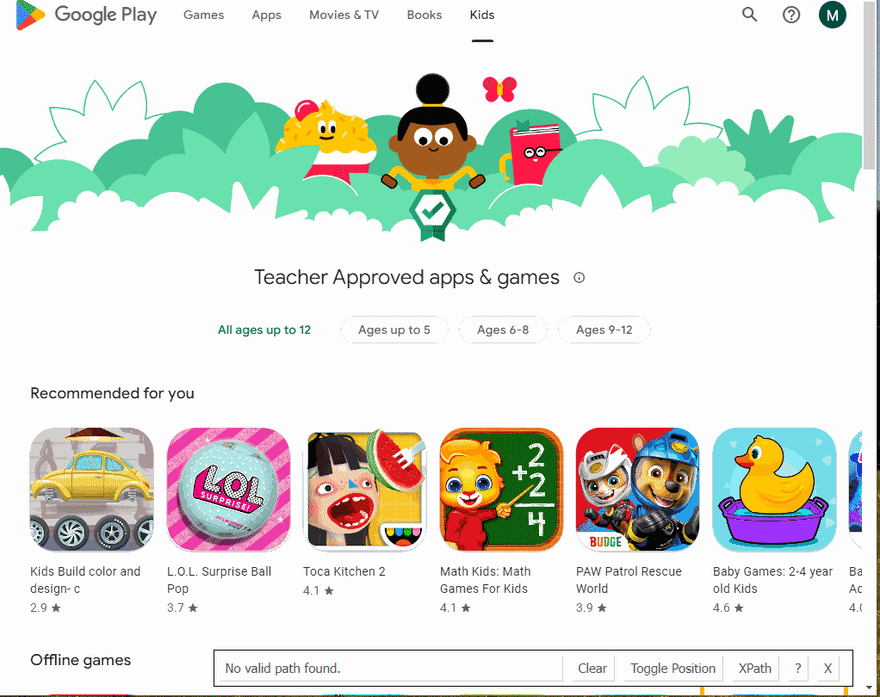
下一步是在滚动完成后从HTML元素中提取数据。通过SelectorGadget Chrome extension,获得合适的CSS选择器的过程非常容易,该过程能够通过单击浏览器中的所需元素来获取CSS选择器。但是,它并不总是完美地工作,尤其是当JavaScript大量使用该网站时。
如果您想了解更多有关它们的信息,我们在Serpapi上有专门的Web Scraping with CSS Selectors博客文章。
下面的GIF说明了使用Selectorgadget选择结果的不同部分的方法。
代码说明
声明koude1从puppeteer-extra Library和koude11控制Chromium浏览器,以防止网站检测到您正在使用puppeteer-extra-plugin-stealth库中使用web driver:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
接下来,我们“说” puppeteer使用StealthPlugin,编写必要的请求参数,并使用ternary operator搜索URL(URL可能因是否指定年龄而有所不同):
puppeteer.use(StealthPlugin());
const searchParams = {
hl: "en", // Parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
device: "phone", // parameter defines the search device. Options: phone, tablet, tv, chromebook
age: null, // parameter defines age subcategory. Options: null (0-12 years), AGE_RANGE1 (0-5 years), AGE_RANGE2 (6-8 years), AGE_RANGE3 (9-12 years)
};
const URL = searchParams.age
? `https://play.google.com/store/apps/category/FAMILY?age=${searchParams.age}&hl=${searchParams.hl}&gl=${searchParams.gl}&device=${searchParams.device}`
: `https://play.google.com/store/apps/category/FAMILY?hl=${searchParams.hl}&gl=${searchParams.gl}&device=${searchParams.device}`;
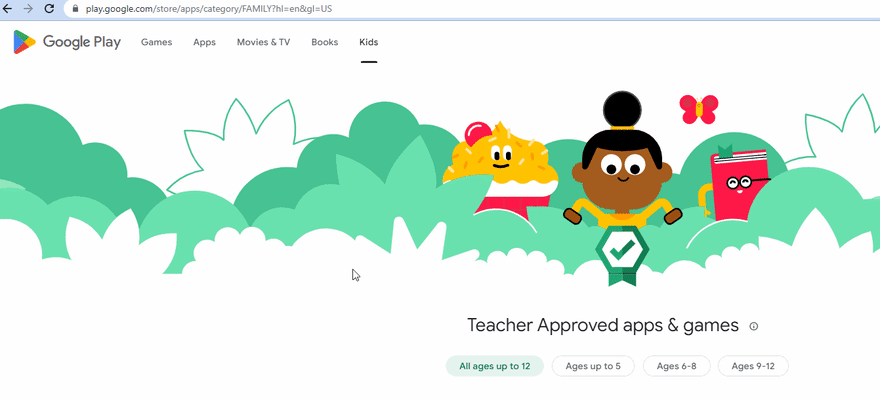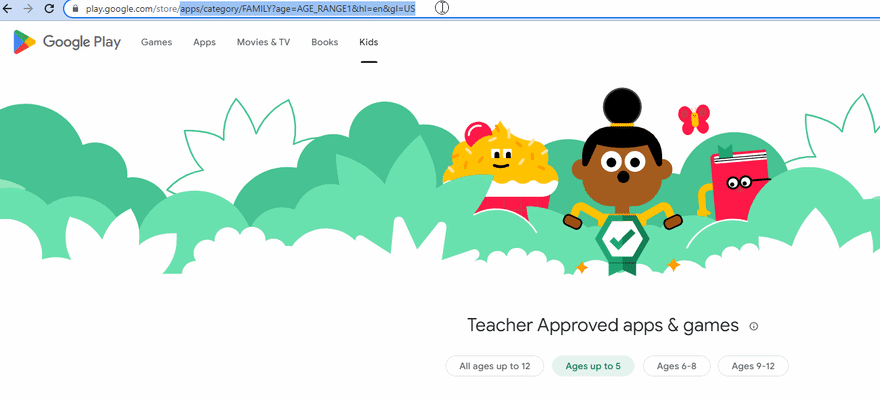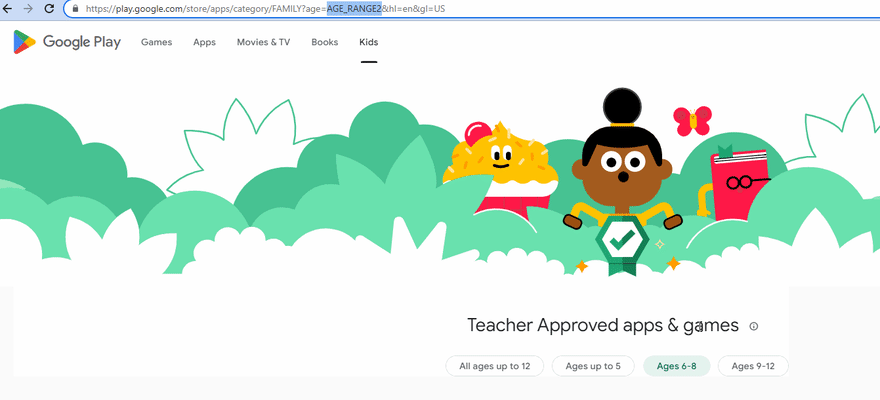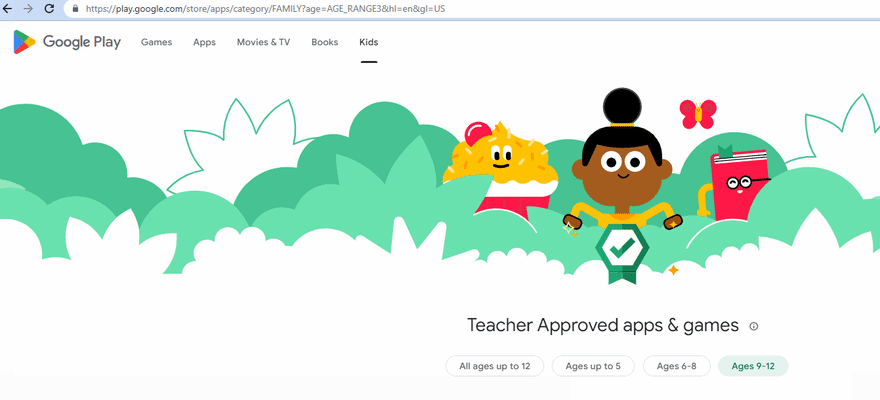
如果将age参数设置为null,则意味着我们使用默认年龄子类别(0-12岁),并且URL看起来像这样:
"https://play.google.com/store/apps/category/FAMILY?hl=en&gl=US";
否则,URL看起来像这样:
"https://play.google.com/store/apps/category/FAMILY?age=AGE_RANGE1&hl=en&gl=US";
下面的GIF说明了URL的变化:
接下来,我们编写一个函数以滚动页面以加载所有文章:
async function scrollPage(page, scrollContainer) {
...
}
在此功能中,首先,我们需要获得scrollContainer高度(使用koude18方法)。然后,我们使用while循环,在其中滚动scrollContainer,等待2秒(使用koude21方法),然后获得一个新的scrollContainer高度。
接下来,我们检查newHeight是否等于lastHeight我们停止循环。否则,我们将newHeight值定义为lastHeight变量,然后重复重复直到页面不向下滚动到末尾:
let lastHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
while (true) {
await page.evaluate(`window.scrollTo(0, document.querySelector("${scrollContainer}").scrollHeight)`);
await page.waitForTimeout(4000);
let newHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
if (newHeight === lastHeight) {
break;
}
lastHeight = newHeight;
}
接下来,我们编写一个函数以从页面获取书籍数据:
async function getKidsAppsFromPage(page) {
...
}
在此功能中,我们从页面上下文中获取信息并将其保存在返回的对象中。接下来,我们需要使用"section .oVnAB"选择器(koude28方法)获取所有HTML元素。
然后,我们使用koude29方法(允许用结果使对象)迭代使用koude30方法构建的数组:
const apps = await page.evaluate(() => {
const mainPageInfo = Array.from(document.querySelectorAll("section .oVnAB")).reduce((result, block) => {
...
}, {});
return mainPageInfo;
});
return apps;
最后,我们需要使用以下方法获取所有数据:
在每个ITARATION步骤中,我们返回上一个步骤结果(使用koude38),并添加带有categoryTitle常数名称的新类别:
我们需要使用两个不同的结果模板,因为页面上有两个不同的应用程序布局:
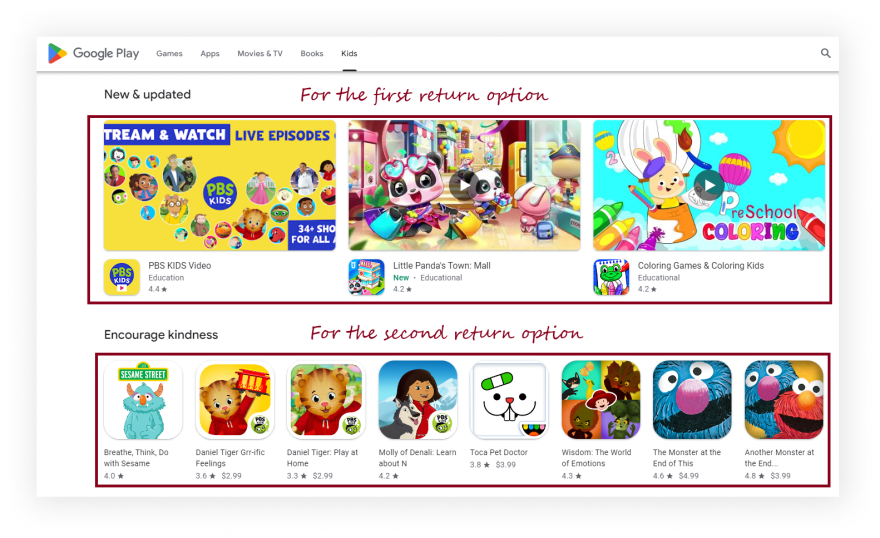
const categoryTitle = block.textContent.trim();
const apps = Array.from(block.parentElement.querySelectorAll(".ULeU3b")).map((app) => {
const link = `https://play.google.com${app.querySelector(".Si6A0c")?.getAttribute("href")}`;
const appId = link.slice(link.indexOf("?id=") + 4);
// if one layout appears
if (app.querySelector(".sT93pb.DdYX5.OnEJge")) {
return {
title: app.querySelector(".sT93pb.DdYX5.OnEJge")?.textContent.trim(),
appCategory: app.querySelector(".sT93pb.w2kbF:not(.ePXqnb)")?.textContent.trim(),
link,
rating: parseFloat(app.querySelector(".ubGTjb:last-child > div")?.getAttribute("aria-label")?.slice(6, 9)) || "No rating",
iconThumbnail: app.querySelector(".j2FCNc img")?.getAttribute("srcset").slice(0, -3),
appThumbnail: app.querySelector(".Vc0mnc img")?.getAttribute("src") || app.querySelector(".Shbxxd img")?.getAttribute("src"),
video: app.querySelector(".aCy7Gf button")?.getAttribute("data-video-url") || "No video preview",
appId,
};
// else extracting second layout
} else {
return {
title: app.querySelector(".Epkrse")?.textContent.trim(),
link,
rating: parseFloat(app.querySelector(".vlGucd > div:first-child")?.getAttribute("aria-label")?.slice(6, 9)) || "No rating",
thumbnail: app.querySelector(".TjRVLb img")?.getAttribute("srcset"),
appId,
};
}
});
return {
...result,
[categoryTitle]: apps,
接下来,编写一个函数来控制浏览器并获取信息:
async function getMainPageInfo() {
...
}
首先,在此功能中,我们需要使用带有当前options的puppeteer.launch({options})方法来定义browser,例如headless: true和args: ["--no-sandbox", "--disable-setuid-sandbox"]。
这些选项意味着我们将headless模式和数组与arguments一起使用,我们用来允许在线IDE中启动浏览器流程。然后我们打开一个新的page:
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
接下来,我们更改默认值(30 sec)等待选择器的时间到60000毫秒(1分钟)与koude46方法缓慢连接,请使用koude48方法访问URL,并使用koude49方法来等待等待选择器直到选择器加载:< br>
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".oVnAB");
最后,我们等到页面滚动,将应用程序数据从apps常数中保存到页面,关闭浏览器,然后返回接收到的数据:
await scrollPage(page, ".T4LgNb");
const apps = await getKidsAppsFromPage(page);
await browser.close();
return apps;
现在我们可以启动我们的解析器:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
输出
{
"New & updated":[
{
"title":"PBS KIDS Video",
"appCategory":"Education",
"link":"https://play.google.com/store/apps/details?id=org.pbskids.video",
"rating":4.4,
"iconThumbnail":"https://play-lh.googleusercontent.com/Fel1apzw2D5Qy1xZ9HYQ3LPEJqZB5OxdhkorYLrQ7fTUIdGU8uIY_qiN9ZvaRs9eItQ=s128-rw",
"appThumbnail":"https://play-lh.googleusercontent.com/9MSE2M5sGVy73d75bBemSfZQicBp1cOkjjG-c3tvW5vOVrpOaXdAyjmnbVcBCMWSaLk=w416-h235-rw",
"video":"No video preview",
"appId":"org.pbskids.video"
},
... and other results
],
"Encourage kindness":[
{
"title":"Breathe, Think, Do with Sesame",
"link":"https://play.google.com/store/apps/details?id=air.com.sesameworkshop.ResilienceThinkBreathDo",
"rating":4,
"thumbnail":"https://play-lh.googleusercontent.com/-UbCkW4xbM661t4mndTi7owhXY0GYBCRQn4Pxl7_1tXgCCvqKsJwUKE-O61NO0CuJA=s512-rw 2x",
"appId":"air.com.sesameworkshop.ResilienceThinkBreathDo"
},
... and other results
],
... and other categories
}
usuingaoqian41 from serpapi
本节是为了显示DIY解决方案与我们的解决方案之间的比较。
最大的区别是您不需要从头开始创建解析器并维护它。
也有可能在Google的某个时候阻止请求,我们在后端处理它,因此无需弄清楚如何自己做或弄清楚要使用哪个验证码,代理提供商。
首先,我们需要安装koude51:
npm i google-search-results-nodejs
这是full code example,如果您不需要说明:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(process.env.API_KEY); //your API key from serpapi.com
const params = {
engine: "google_play", // search engine
gl: "us", // parameter defines the country to use for the Google search
hl: "en", // parameter defines the language to use for the Google search
store: "apps", // parameter defines the type of Google Play store
store_device: "phone", // parameter defines the search device. Options: phone, tablet, tv, chromebook, watch, car
apps_category: "FAMILY", // parameter defines the apps and games store category. In this case we use "FAMILY" to scrape Google Play Children apps
};
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
const getResults = async () => {
const json = await getJson();
const appsResults = json.organic_results.reduce((result, category) => {
const { title: categoryTitle, items } = category;
const apps = items.map((app) => {
const { title, link, rating, category, video = "No video preview", thumbnail, product_id } = app;
if (category) {
return {
title,
link,
rating,
category,
video,
thumbnail,
appId: product_id,
};
} else {
return {
title,
link,
rating,
thumbnail,
appId: product_id,
};
}
});
return {
...result,
[categoryTitle]: apps,
};
}, {});
return appsResults;
};
getResults().then((result) => console.dir(result, { depth: null }));
代码说明
首先,我们需要从koude51库中声明SerpApi并使用SerpApi的API键定义新的search实例:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(API_KEY);
接下来,我们为提出请求的必要参数编写:
const params = {
engine: "google_play", // search engine
gl: "us", // parameter defines the country to use for the Google search
hl: "en", // parameter defines the language to use for the Google search
store: "apps", // parameter defines the type of Google Play store
store_device: "phone", // parameter defines the search device. Options: phone, tablet, tv, chromebook, watch, car
apps_category: "FAMILY", // parameter defines the apps and games store category. In this case we use "FAMILY" to scrape Google Play Children apps
};
接下来,我们从Serpapi库中包装搜索方法,以便进一步处理搜索结果:
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
最后,我们声明了从页面获取数据并返回的函数getResult:
const getResults = async () => {
...
};
首先,在此功能中,我们获得了带有结果的json,然后我们需要在接收到的json中迭代organic_results数组。为此,我们使用koude29方法(它允许用结果使对象)。在每个ITARATION步骤中,我们返回上一个步骤结果(使用koude38),并添加带有categoryTitle常数名称的新类别:
const json = await getJson();
const appsResults = json.organic_results.reduce((result, category) => {
...
return {
...result,
[categoryTitle]: apps,
};
}, {});
return appsResults;
接下来,我们破坏了category元素,将title重新定义为categoryTitle常数,然后itarate items数组以获取此类别的所有书籍。为此,我们需要破坏book元素,为rating设置默认值“ no评分”并返回此常数:
我们需要使用两个不同的结果模板,因为页面上有两个不同的应用程序布局:
const apps = items.map((app) => {
const { title, link, rating, category, video = "No video preview", thumbnail, product_id } = app;
// if one layout appears
if (category) {
return {
title,
link,
rating,
category,
video,
thumbnail,
appId: product_id,
};
// else extracting second layout
} else {
return {
title,
link,
rating,
thumbnail,
appId: product_id,
};
}
});
之后,我们运行getResults函数,并使用koude69方法在控制台中打印所有接收的信息,该方法允许您使用带有必要参数的对象来更改默认输出选项:
getResults().then((result) => console.dir(result, { depth: null }));
输出
{
"New & updated":[
{
"title":"PBS KIDS Video",
"link":"https://play.google.com/store/apps/details?id=org.pbskids.video",
"rating":4.4,
"category":"Education",
"video":"No video preview",
"thumbnail":"https://play-lh.googleusercontent.com/Fel1apzw2D5Qy1xZ9HYQ3LPEJqZB5OxdhkorYLrQ7fTUIdGU8uIY_qiN9ZvaRs9eItQ=s64-rw",
"appId":"org.pbskids.video"
},
... and other results
],
"Enriching games":[
{
"title":"Violet - My Little Pet",
"link":"https://play.google.com/store/apps/details?id=ro.Funbrite.VioletMyLittlePet",
"rating":4.7,
"thumbnail":"https://play-lh.googleusercontent.com/lnv-uzrGlkY3Ke_UofPyq77k4RDjatyIOrCnTGoBSWtIF6sluX-eys3MH8Z43kZZ6g=s256-rw",
"appId":"ro.Funbrite.VioletMyLittlePet"
},
... and other results
],
... and other categories
}
链接
如果您想查看一些用serpapi制定的项目,write me a message。
添加Feature Requestð«或Bugð