Xrplwin正在开发PHP开源XRPLWINANALYZER(XWA)。
这个项目仍在积极发展中。
介绍
XRP Ledger(XRPL)是由全球开发人员社区领导的分散的公共区块链。
XWA存储每学交易历史记录,并以可搜索的方式提供。
搜索引擎是XWA的核心功能和用于分析和汇总分类帐数据的基础。
将描述以可搜索方式存储XRPL交易的方法。
汇总的实时数据可能会很麻烦,因为有很多活动部件,但是我们在Ledger系统的“ luck ”中,因为数据历史记录不可动摇(不动态变化)。我们将利用它来缓存响应并最大程度地减少数据库命中。
数据存储概述
主要持久数据存储是 AWS DynamoDB -Amazon DynamoDB是一种完全管理的专有NOSQL数据库服务,支持密钥值和文档数据结构。
次要的非势力db是 PostgreSQL 安装在用于临时聚合,映射和索引的本地服务器上。
其他PostgreSQL数据库用于存储用户首选项,搜索,标签等。
缓存概述
有几种缓存技术用于防止过度发出动力。
- redis
- 结果集的磁盘商店
- http像清漆一样缓存
深潜
用于交易存储的DynamoDB
每个XRPL事务都有许多可用字段,对于每个事务类型,仅将某些字段复制到DynamoDB,用于在这些交易中显示和搜索这些交易,包括从实时XRPL节点中获取其他数据的交易。此方法将使DynamoDB存储尽可能小。
让我们看付款类型示例。
使用大量的字段和元数据仅存储以付款类型:
分区键: pk
排序键: sk
- 日期 - 波纹时期
- 键: t
- 值:波纹时期整数(小于Unix Timestamp)
- 费用 - 滴水费
- 键: fe
- 值:滴水量(小于XRP数量)
- 交易对手地址
- 键: r
- 值:raddress ...
- 交易哈希
- 键: h
- 值:txhash
- 金额(仅XRP或金额+发行人+货币的金额)
- 键: a
- 值:字符串金额 - 可以是指数符号
- 令牌的其他键: i (可选)和 c (可选),其中 i 是raddress和 c 是货币ISO或十六进制
- 方向(表示或输出)
- 键: in (可选)
- 值:in -true(1位),out-标志未存储(0字节)
- sourcetag
- 键: st (可选)
- 值:字符串
- destinationTag
- 键: dt (可选)
- 值:字符串
一个样本支付交易的现实世界表示,就像这样
[
{
"a": 50,
"r": "rGhATPPU4tCfYF5mwrYoMsrDp23eKdsULU",
"c": "EUR",
"t": 478121360,
"SK": 11908872.003,
"h": "825029C9F6100DBEBB87C5701B8648830E5119AB84B1E82021D129B8BE953321",
"i": "rhub8VRN55s94qWKDv6jmDy1pUykJzF3wq",
"PK": "rhotcWYdfn6qxhVMbPKGDF3XCKqwXar5J4-1",
"fe": 15000
}
]
大多数字段键共享(同样命名)
例如,“ a ”金额可以表示付款中的转移金额或限制 trustset中的金额。构建确定过滤器时,此关键名称共享将消除复杂性。

分区键
使用 raddress 和数字事务类型的表分区密钥(PK)组合(示例rhotcWYdfn6qxhVMbPKGDF3XCKqwXar5J4-1)
排序键
排序键(范围键)是LeDgerIndex和TransActionIndex(示例11908872.003)的组合,它为我们提供了数字排序键,以通过时间订购特定 raddress 的所有交易。交易索引始终用零填充以保持一致的交易排序,最大值为999,这将使所有交易都保持在一个结果集的范围内,并具有特定的PK + Ledgerindex。
主键
rAddress-TYPE + LedgerIndex.TransactionIndex
rhub8VRN55s94qWKDv6jmDy1pUykJzF3wq-1 + 11908872.003
查询DynamoDB
这将描述如何在有或没有晚期条件下获得特定交易结果的技术如何获得查询。
限制
有几个限制。
- 历史随时间限制
- 分页结果
当要求从和到 日期字段的单一raccount 交易时,不得超过31天。如果单个查询返回超过10K的结果,则输出以10K结果的增量分页到几页。这是为了使HTTP响应不太大。
XWA搜索引擎
数据获取几句:
- http缓存
- 磁盘缓存
- 条件映射器通过计数DynamoDB来减少生成SK范围,该动态需要查询并构建 scanplan
- Scanplan列出了针对DynamoDB执行的查询列表
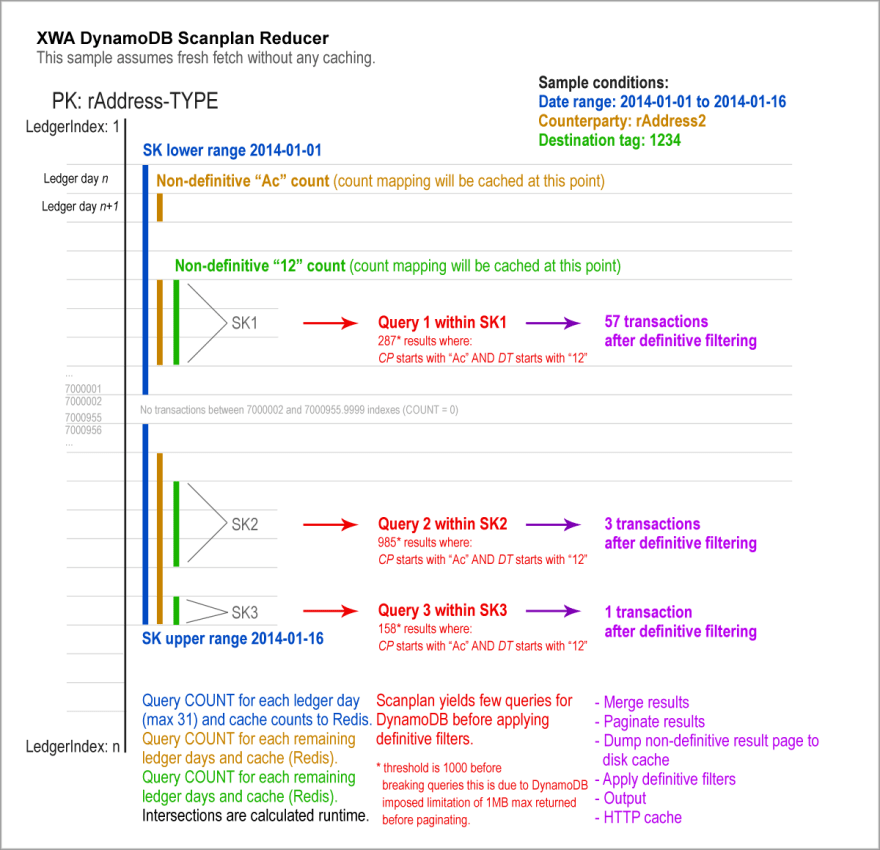
执行工作流
上面的模式演示了查询过程,以通过三个过滤器,日期范围,对手raddress2和目标标签提取交易过程1234。对每个请求的交易类型S进行重复此过程,并在缓存之前合并和分类后进行邮政。
当访问搜索API的请求首先是击中的一件事是反向代理(如varnish),如果未缓存请求,则将传递给后端PHP脚本。
根据已发送的过滤器参数,确定性和非确定过滤器标识符(哈希)生成,并用于查找下一级别的缓存-Disk缓存文件。如果在磁盘上找到了该非确定标识符的结果收集的缓存,则在返回JSON输出之前,收集不重新审理,并在返回JSON输出之前进行定期过滤器。
如果找不到磁盘缓存,则在日期范围和每个非确定过滤器的地图数据之间构建每日循环,以本地DB查找。如果在本地DB中找不到,则DynamoDB计数查询将针对特定PK的日范围(SK)执行。返回的计数存储在本地DB(地图表)中,也存储在Redis中。这样可以确保对DynamoDB的打击更少。在所有计数统计数据均已提取后,PHP脚本计算结果> 0的相交分类帐开始。在该 scanplan 被生成作为执行扫描和查询DynamoDB的基础。
。扫描计划的每一个DynamoDB查询的硬编码限制为1000个项目,如果在一组分类帐时返回了1000多个项目,则扫描计划可能会将一个分为多个查询。这将避免由于其返回数据的1MB限制而导致的结果。
。简而言之,对于条件的组合,扫描程序将仅提取特定的分类帐天,而这些分类帐日在其中包含一项或多项交易。确定的过滤器将在这些交易上循环,并拒绝任何不完全匹配的东西。
非确定和确定性过滤的示例:
交易对手 rvcdef1234567 将产生100件交易,其中“ r ”以“ vc ”开头,而确定性过滤将滤除5个交易,准确地滤除5个交易匹配。这样就这样做了,因此我们有有限的缓存组合。
同步Raccount历史
在Laravel中创建了命令,该命令同步到某些Raccount的完整交易历史记录,每个交易都以减少格式存储在DynamoDB中(以节省空间)。
此命令在一个(或几个)背景队列作业中执行。这是预测性dynamoDB写道的优势,可以根据需求控制写入吞吐量。
一台小型Linux服务器可以处理每秒60个写字,足以在几个小时内同步交换帐户的完整历史记录(这仅需要一次)。
2-3K交易的小个人帐户将在2-10分钟内同步,这是我们在基准测试时的经验。
同步分类帐日
Laravel内部创建了命令,即Synces Ledger天数,Cron Job将在一天开始(UTC)每天执行此命令,以确保以前和今天的Ledger索引索引边缘可用于Raddress Seancer和search。
。缓存冲洗
- 地图表 - 弹出映射超过30天
- 磁盘冲洗 - 删除超过30天或开始的月开始
- redis缓存-30天(在评论中)
- HTTP缓存-2个月(在评论中)
redis和varnish需要设置为自动驱逐旧物品。
聚合
使用功能强大的搜索引擎数据聚合很容易壮举。
让我们探索场景,需要在其中显示特定货币的支出图,例如GateHub。要显示此数据,足以在特定时间上查询搜索引擎,只需每天或一个月添加金额即可。这将包括令牌过滤器,从和过滤,dir = out。
希望知道您在付款交易上花了多少费用?
使用条件:type =付款和dir = out
帐户值随时间图?查询付款token = xrp,看看发生了什么以及随时间范围内发生什么。
其他用例
使用目的地和源标签过滤在交换上跟踪您的帐户。
通过查询已知Exchange XRP帐户。
下一个
数据聚合和图形(即将开始)。
感谢您的阅读! ð